【视频行为识别6】TSN(Temporal Segment Network—ECCV2016
TSN(Temporal Segment Networks)
论文:Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
论文链接:https://arxiv.org/abs/1608.00859
代码链接一(caffe):https://github.com/yjxiong/temporal-segment-networks
代码链接二(pytorch):https://github.com/yjxiong/tsn-pytorch
论文点评概述:
1)相对与以前双流方法(单帧RGB+光流),TSN通过将整段视频分段然后采样的方式,使得网络能够处理更长时间的视频,从而网络得到的时序特征更加丰富。
2)研究对比了四种输入信息模式:RGB图像、RGB帧差值、光流、扭曲光流(应对相机抖动)。
3)受限于当时的数据集相对较小,作者采用三种方式防止过拟合①交叉输入预训练(将RGB层参数用作光流预训练)、②部分BN和dropout、③裁剪扩充。
提出问题:
1)two-stream 卷积网络对于长范围时间结构的建模无能为力,主要因为它仅仅操作一帧(空间网络)或者操作短片段中的单堆帧(时间网络),因此对时间上下文的访问是有限的。而本文视频级框架TSN可以从整段视频中建模动作。)
2)与two-stream方法相同,TSN也是由空间流卷积网络和时间流卷积网络构成。但two-stream采用的是单帧或者单堆帧,而TSN使用从整个视频中稀疏地采样一系列短片段,每个片段都将给出其本身对于行为类别的初步预测,从这些片段的“共识”来得到视频级的预测结果。
解决的问题:
1、处理长时间视频的行为判断问题(此前一些论文主要对于单帧图像或几帧的短时间进行处理)。
2、解决数据少的问题,数据量少会使得一些深层的网络难以应用到视频数据中,因为过拟合会比较严重。
主要贡献:
1)提出了TSN(Temporal Segment Networks),基于长范围时间结构(long-range temporal structure)建模,结合了稀疏时间采样策略(sparse temporal sampling strategy)和视频级监督(video-level supervision)来保证在进行整段较长视频学习时,能够有效的学习到特征并且更高效。
2)基于本文TSN的基础上,进行了一些实验,去验证不同输入信息的效果和防止过拟合策略。
数据集表现:HMDB51(69.4%)、UCF101(94.2%)
TSN网络结构:
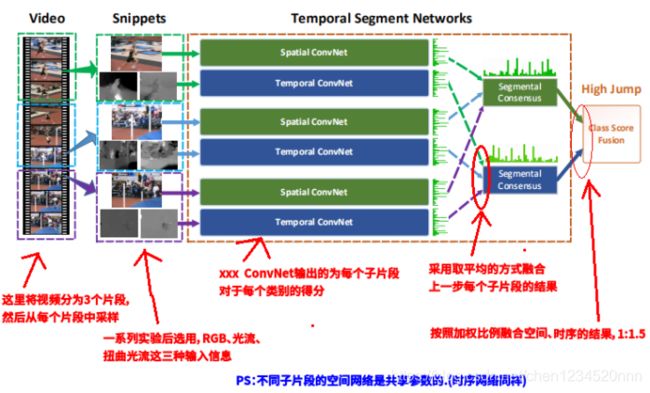
由上图所示,一个输入视频被分为 K 段(segment),然后从每段中随机采样得到子片段(snippet)。最后融合每个子片段的类别得分(融合这一部分作者写了一堆时髦的公式,但是最后选择对每个子片段结果取平均),这是一个视频级的预测。然后对所有模式的预测融合产生最终的预测结果。
![]()
网络结构和TSN函数表达式详解:
1)采样得到子片段:(T1,T2,…,Tk)表示K个采样得到的snippets(子片段),也就是说Tk是从其对应(S1,S2,…,Sk)中随机采样出来的结果。
2)子片段输入信息种类:Tk是一个snippet,每个snippet包含一帧图像和两个光流特征图(光流、扭曲光流)。这也就完成了作者说的稀疏采样。
3)单个子片段的输出:式子中的W就是网络的参数,F(Tk;W)函数代表采用 W 作为参数的卷积网络作用于短片段 Tk,函数返回 Tk 相对于所有类别的得分,也就是该snippet属于每个类的得分。F函数的输出值对应于网络结构图中Spatial ConvNet(空间)或Temporal ConvNet(时序)的输出结果,ConvNet图后面的绿色条形图,代表的就是socre在类别上的分布。
4)融合所有子片段结果:g是一个融合函数,在文中采用的是均值函数,就是对所有snippet的属于同一类别的得分做个均值。g函数的输出结果就是网络结构中Segmental Consensus的输出结果。
5)softmax计算概率:最后用H函数(文中用的softmax函数)根据得分算概率,概率最高的类别就是该video所属的类别。
6)融合时序和空间结果:在输入softmax之前会将空间和时序两条网络的结果进行合并,默认采用加权求均值的方式进行合并,文中用的权重比例是spatial:temporal=1:1.5。
7)所有子片段共享参数:网络结构中的K个Spatial ConvNet的参数是共享的,K个Temporal ConvNet的参数也是共享的,实际用代码实现时只是将K个子片段输入到同一个网络中。
损失函数(交叉熵):C表示类别数,yi是标签
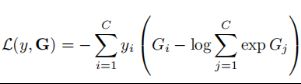
网络输入模式:

作者测试了四种输入类型:从左到右分别为RGB图像、RGB差值(两帧图像的差值)、光流场(optical flow fields)和扭曲光流场(warped optical flow fields)。
1)RGB图像:单一RGB图像表征特定时间点的静态信息,从而缺少上下文信息。
2)RGB差值:两个连续帧的RGB差异表示动作的改变,对应于运动显著区域。故作者实验将RGB差异堆作为另一个输入模式。
3)光流场(optical flow fields):光流场致力于捕获运动信息。
4)扭曲光流场:由于现实拍摄的视频中,通常存在摄像机的运动,这样光流场就不是单纯体现出人类行为。由于相机的移动,视频背景中存在大量的水平运动。受到iDT(improved dense trajectories)工作的启发,作者提出将扭曲的光流场作为额外的输入。通过估计单应性矩阵(homography matrix)和补偿相机运动来提取扭曲光流场。图2中,扭曲光流场抑制了背景运动,使得专注于视频中的人物运动。
防止过拟合:
1、交叉输入模式预训练
1)对于RGB输入:采用在ImageNet上预训练的模型做初始化。
2)对于其他输入模式(如RGB差异、光流场):它们基本上捕捉视频数据的不同视觉方面,并且它们的分布不同于RGB图像的分布。作者提出了交叉模式预训练技术:利用RGB模型初始化时间网络。
交叉训练模式具体操作方式:首先,通过线性变换将光流场离散到从0到255的区间,这使得光流场的范围和RGB图像相同。然后修改RGB模型第一个卷积层的权重来处理光流场的输入。具体是对RGB通道上的权重进行平均,并根据时间网络输入的通道数量复制这个平均值。这一策略对时间网络中降低过拟合非常有效。\
2、正则化技术
在学习过程中,Batch Normalization将估计每个batch内的激活均值和方差,并使用它们将这些激活值转换为标准高斯分布。这一操作虽可以加快训练的收敛速度,但由于要从有限数量的训练样本中对激活分布的偏移量进行估计,也会导致过拟合问题。因此,在用预训练模型初始化后,冻结所有Batch Normalization层的均值和方差参数,但第一个标准化层除外。由于光流的分布和RGB图像的分布不同,第一个卷积层的激活值将有不同的分布,于是,我们需要重新估计的均值和方差,称这种策略为部分BN。与此同时,在BN-Inception的全局pooling层后添加一个额外的dropout层,来进一步降低过拟合的影响。dropout比例设置:空间流卷积网络设置为0.8,时间流卷积网络设置为0.7。
3、数据增强
数据增强能产生不同的训练样本并且可以防止严重的过拟合。在传统的two-stream中,采用随机裁剪和水平翻转方法增加训练样本。作者采用两个新方法:角裁剪(corner cropping)和尺度抖动(scale-jittering)。
1)角裁剪(corner cropping):仅从图片的边角或中心提取区域,来避免默认关注图片的中心。
2)尺度抖动(scale jittering):将输入图像或者光流场的大小固定为 256×340,裁剪区域的宽和高随机从 {256,224,192,168} 中选择。最终,这些裁剪区域将会被resize到224×224 用于网络训练。事实上,这种方法不光包括了尺度抖动,还包括了宽高比抖动。
实验:
1、对比4种不同训练方式的效果
作者对四种方案进行实验:(1)从零开始训练;(2)仅仅预训练空间流;(3)采用交叉输入模式预训练;(4)交叉输入模式预训练和部分BN dropout结合。结果总结在下表1中:
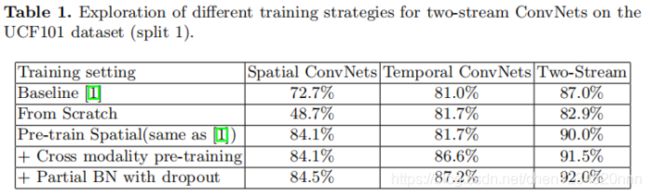
由上表可以看出,从零开始训练比基线算法(two-stream卷积网络)的表现要差很多,证明需要重新设计训练策略来降低过拟合的风险,特别是针对空间网络。对空间网络进行预训练、对时间网络进行交叉输入模式预训练,取得了比基线算法更好的效果。之后还在训练过程中采用部分BN dropout的方法,将识别准确率提高到了92.0%。
2、对比四种输入信息
在上文中提出了两种新的模式:RGB差异和扭曲的光流场。不同输入模式的表现比较如下表2:

对比结论:
1)RGB图像和RGB差异的结合可以将识别准确率提高到87.3%,表明两者的结合可以编码一些补充信息。
2)光流和扭曲光流的表现相近(87.2% vs 86.9%),两者融合可以提高到87.8%。
3)四种模式的结合可以提高到91.7%。由于RGB差异可以描述相似但不稳定的动作模式,作者还评估了其他三种模式结合的表现(92.3% vs 91.7%)。作者推测光流可以更好地捕捉运动信息,而RGB差异在描述运动时是不稳定的。在另一方面,RGB差异可以当作运动表征的低质量、高速的替代方案。
3、对比三种不同的聚合函数
TSN表达式中段共识函数被定义为它的聚合函数 g,这里评估 g 的三种形式:(1)最大池化;(2)平均池化;(3)加权平均。实验结果见表3。
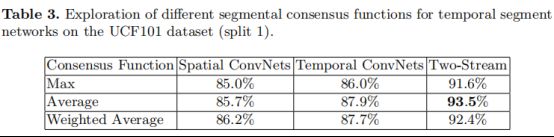
对比结果:平局池化函数达到最佳的性能。因此在接下来的实验中选择平均池化作为默认的聚合函数。
4、对比不同的基网络

对比结果:3个网络架构BN-Inception、GoogLeNet和VGGNet-16。在这些架构中,BN-Inception表现最好,故选择它作为TSN的卷积网络架构。
5、对比TSN中不同组件对准确率的影响

对比结果:从交叉预训练、部分BN与dropout、TSN的最终结构,一步一步提高了网络的准确率。
论文结果:
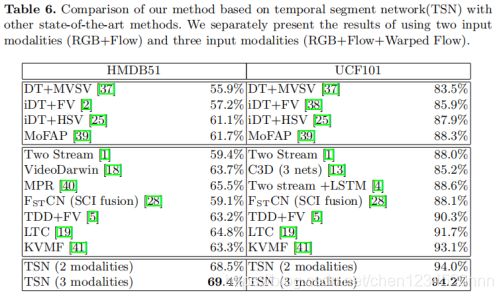
没什么好说的,详情见表,总之当年的SOTA。
特别感谢,参考文章链接:https://blog.csdn.net/zhang_can/article/details/79618781