卷积神经网络 注意力机制_卷积神经网络中的注意
卷积神经网络 注意力机制
This summer I had the pleasure of attending the Brains, Minds, and Machines summer course at the Marine Biology Laboratory. While there, I saw cool research, met awesome scientists, and completed an independent project. In this blog post, I describe my project.
今年夏天,我很高兴参加了海洋生物学实验室的“ 大脑,思维和机器”暑期课程。 在那儿,我看到了很酷的研究,遇到了很棒的科学家,并完成了一个独立项目。 在这篇博客中,我描述了我的项目。
In 2012, Krizhevsky et al. released a convolutional neural network that completely blew away the field at the imagenet challenge. This model is called “Alexnet,” and 2012 marks the beginning of neural networks’ resurgence in the machine learning community.
在2012年,Krizhevsky等人。 发布了一个卷积神经网络 ,在imagenet挑战中完全消失了。 该模型称为“ Alexnet”,2012年标志着神经网络在机器学习社区中兴起的开始。
Alexnet’s domination was not only exciting for the machine learning community. It was also exciting for the visual neuroscience community whose descriptions of the visual system closely matched alexnet (e.g., HMAX). Jim DiCarlo gave an awesome talk at the summer course describing his research comparing the output of neurons in the visual system and the output of “neurons” in alexnet (you can find the article here).
Alexnet的统治不仅让机器学习社区兴奋不已。 对于视觉神经科学界来说,这也是令人兴奋的,他们对视觉系统的描述与alexnet(例如HMAX )非常匹配。 吉姆·迪卡洛 ( Jim DiCarlo )在暑期课程上进行了精彩的演讲,描述了他的研究,比较了视觉系统中神经元的输出和alexnet中“神经元”的输出(您可以在此处找到文章)。
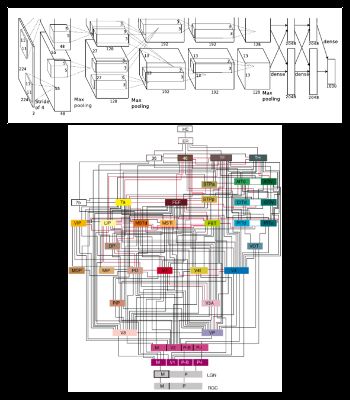
I find the similarities between the visual system and convolutional neural networks exciting, but check out the depictions of alexnet and the visual system above. Alexnet is depicted in the upper image. The visual system is depicted in the lower image. Comparing the two images is not fair, but the visual system is obviously vastly more complex than alexnet.
我发现视觉系统和卷积神经网络之间的相似之处令人兴奋,但请查看上面有关alexnet和视觉系统的描述。 上图显示了Alexnet。 视觉系统显示在下部图像中。 比较这两个图像是不公平的,但是视觉系统显然比alexnet复杂得多。
In my project, I applied a known complexity of the biological visual system to a convolutional neural network. Specifically, I incoporated visual attention into the network. Visual attention refers to our ability to focus cognitive processing onto a subset of the environment. Check out this video for an incredibly 90s demonstration of visual attention.
在我的项目中,我将生物视觉系统的已知复杂性应用于卷积神经网络。 具体来说,我将视觉注意力整合到了网络中。 视觉注意力是指我们将认知过程集中到环境的一个子集上的能力。 观看此视频 ,获得令人难以置信的90年代视觉注意力演示。
In this post, I demonstrate that implementing a basic version of visual attention in a convolutional neural net improves performance of the CNN, but only when classifying noisy images, and not when classifying relatively noiseless images.
在本文中,我演示了在卷积神经网络中实现视觉注意力的基本版本可以提高CNN的性能,但仅在对嘈杂的图像进行分类时,而对相对无噪声的图像进行分类时,才可以提高CNN的性能。
Code for everything described in this post can be found on my github page. In creating this model, I cribbed code from both Jacob Gildenblat and this implementation of alexnet.
这篇文章中描述的所有代码都可以在我的github页面上找到。 在创建此模型时,我从Jacob Gildenblat和alexnet的实现中抄写了代码 。
I implemented my model using the Keras library with a Theano backend, and I tested my model on the MNIST database. The MNIST database is composed of images of handwritten numbers. The task is to design a model that can accurately guess what number is written in the image. This is a relatively easy task, and the best models are over 99% accurate.
我实现了我的模型使用Keras库与Theano后台 ,我测试了我的模型上MNIST数据库 。 MNIST数据库由手写数字图像组成。 我们的任务是设计一个模型,该模型可以准确地猜测图像中写入了多少数字。 这是一个相对容易的任务, 最佳模型的准确率超过99% 。
I chose MNIST because its an easy problem, which allows me to use a small network. A small network is both easy to train and easy to understand, which is good for an exploratory project like this one.
我之所以选择MNIST,是因为它很容易解决问题,使我可以使用小型网络。 小型网络既易于培训,又易于理解,这对于像这样的探索性项目非常有用。

Above, I depict my model. This model has two convolutional layers. Following the convolutional layers is a feature averaging layer which borrows methods from a recent paper out of the Torralba lab and computes the average activity of units covering each location. The output of this feature averaging layer is then passed along to a fully connected layer. The fully connected layer “guesses” what the most likely digit is. My goal when I first created this network was to use this “guess” to guide where the model focused processing (i.e., attention), but I found guided models are irratic during training.
上面,我描述了我的模型。 该模型具有两个卷积层 。 在卷积层之后是一个特征平均层,它借鉴了Torralba实验室的最新论文中的方法,并计算了覆盖每个位置的单元的平均活动度。 然后,此特征平均层的输出将传递到完全连接的层。 全连接层“猜测”最可能的数字是什么。 当我第一次创建该网络时,我的目标是使用这种“猜测”来指导模型集中处理(即关注)的位置,但是我发现在训练过程中,指导模型是不固定的。
Instead, my current model directs attention to all locations that are predictive of all digits. I haven’t toyed too much with inbetween models – models that direct attention to locations that are predictive of the N most likely digits.
相反,我当前的模型将注意力转移到可以预测所有数字的所有位置。 我对模型之间的兴趣不大,这些模型将注意力集中在可以预测N个最可能数字的位置上。
So what does it mean to “direct attention” in this model. Here, directing attention means that neurons covering “attended” locations are more active than neurons covering the unattended locations. I apply attention to the input of the second convolutional layer. The attentionally weighted signal passes through the second convolutional layer and passes onto the feature averaging layer. The feature averaging layer feeds to the fully connected layer, which then produces a final guess about what digit is present.
因此,在此模型中“直接关注”意味着什么。 在这里,引导注意力意味着覆盖“关注”位置的神经元比覆盖无人照管位置的神经元更活跃。 我将注意力放在第二个卷积层的输入上。 注意力加权的信号通过第二个卷积层并到达特征平均层。 特征平均层将输入到完全连接的层,然后再对存在的数字做出最终猜测。
I first tested this model on the plain MNIST set. For testing, I wanted to compare my model to a model without attention. My comparison model is the same as the model with attention except that the attention directing signal is a matrix of ones – meaning that it doesn’t have any effect on the model’s activity. I use this comparison model because it has the same architecture as the model with attention.
我首先在普通MNIST集合上测试了此模型。 为了进行测试,我想将我的模型与一个模型进行比较而不引起注意。 我的比较模型与注意模型相同,只是注意指导信号是一个1的矩阵,这意味着它对模型的活动没有任何影响。 我使用此比较模型,因为它与注意模型具有相同的体系结构。
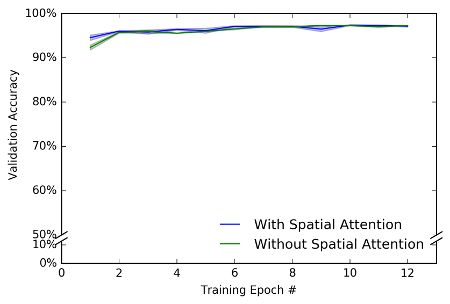
I depict the results of my attentional and comparison models below. On the X-axis is the test phase (10k trials) following each training epoch (60k trials). On the Y-axis is percent accuracy during the test phase. I did 3 training runs with both sets of models. All models gave fairly similar results, which led to small error bars (these depict standard error). The results are … dissapointing. As you can see both the model with attention and the comparison model perform similarly. There might be an initial impact of attention, but this impact is slight.
我在下面描述了我的注意力和比较模型的结果。 在X轴上是每个训练时期(60k试验)之后的测试阶段(10k试验)。 在Y轴上是测试阶段的准确度百分比。 我用两组模型进行了3次训练。 所有模型都给出了相当相似的结果,从而导致较小的误差线(这些误差线描述了标准误差)。 结果是……令人失望。 如您所见,关注模型和比较模型的执行情况相似。 注意可能会产生最初的影响,但是影响很小。
This result was a little dissapointing (since I’m an attention researcher and consider attention an important part of cognition), but it might not be so surprising given the task. If I gave you the task of naming digits, this task would be virtually effortless; probably so effortless that you would not have to pay very much attention to the task. You could probably talk on the phone or text while doing this task. Basically, I might have failed to find an effect of attention because this task is so easy that it does not require attention.
这个结果有点令人失望(因为我是注意力研究者,并且认为注意力是认知的重要组成部分),但是鉴于这项任务,这可能并不令人惊讶。 如果我给您指定数字命名的任务,那么这个任务实际上是毫不费力的。 可能如此轻松,以至于您不必非常注意该任务。 执行此任务时,您可能会打电话或发短信。 基本上,我可能找不到关注的效果,因为此任务非常容易,不需要关注。
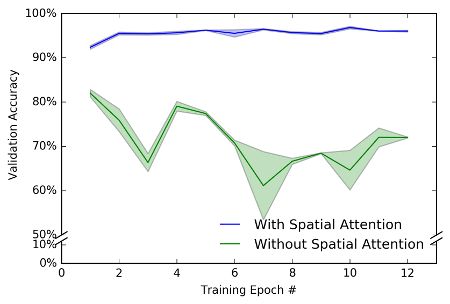
I decided to try my network when the task was a little more difficult. To make the task more difficult, I added random noise to each image (thank you to Nancy Kanwisher for the suggestion). This trick of adding noise to images is one that’s frequently done in psychophysical attention expeirments, so it would be fitting if it worked here.
我决定在任务比较困难时尝试使用我的网络。 为了使任务更加困难,我在每个图像上添加了随机噪声(感谢Nancy Kanwisher的建议)。 这种在图像上增加噪点的技巧是心理物理注意力实验中经常采用的技巧,因此,如果在这里有效,那将是合适的。
翻译自: https://www.pybloggers.com/2016/09/attention-in-a-convolutional-neural-net/
卷积神经网络 注意力机制