DeepMind 让AI 拥有记忆并实现序列学习,AlphaGo 一周年技术盘点
感谢新智元授权CSDN发布。
欢迎人工智能领域技术投稿、约稿、给文章纠错,请发送邮件至[email protected]
在 AlphaGo 获胜一周年的今天,DeepMind 发表最新研究成果,让神经网络成功在学习新任务的同时,不忘老的任务,向着自适应学习迈出重要一步。盘点 DeepMind 一年多以来的技术和商业成果,他们确实一直向着“解决智能”在努力。在赞叹的同时,我们也需要问自己——中国的 DeepMind 在哪里?
“以前,我们有一个能够学会玩任何游戏的系统,但它一次只能学会玩一个游戏,” DeepMind 研究科学家 James Kirkpatrick 在接受 Wired 采访时表示,“现在我们展示了一个可以一次学习玩好几个游戏的系统。”
Kirkpatrick 提到的这项研究今天在《美国科学院院刊》(PNAS)上发表,展示了 DeepMind 研究人员利用监督学习和强化学习,克服神经网络“灾难性遗忘”的问题——他们成功让 AI 实现了序列学习(sequences learning)。
DeepMind 表示,他们借鉴了神经科学的原理,从哺乳动物和人类的大脑固化以往知识的理论中汲取了灵感。
为了让 AI “拥有记忆”,DeepMind 研究人员此前曾经提出了可微分神经计算机(DNC),将一个外部存储结构引入神经网络。这次,他们开发了一种称为“弹性权重加固”(EWC)的算法,可以说是从内部改善,让神经网络能够在学习新任务的同时,不会忘记此前已经学到的内容。
根据 Kirkpatrick 的解释,算法能够挑选出它成功学会玩一款游戏中最有用的部分,并将这部分知识保留下来。“我们只允许 AI 在游戏之间以非常缓慢的速度做出改变,”Kirkatrick 说:“这样就有空间去学习新的任务,同时发生的变化也不会覆盖以前学习的内容。”
Kirkpatrick 表示,这项成果证明了神经网络可以完成序列性的学习,但这对学习效率是否有提升还不明确。
“我们的下一步是尝试和利用序列学习去改进现实世界的学习。”
DeepMind 再出击,修改学习规则,让神经网络拥有记忆
DeepMind 今天在官方博客发文,具体阐释了他们的这项研究成果。计算机程序在学习执行一项任务后,通常也很快就会忘记它们。DeepMind 在最新的 PHAS 论文中,提出可以修改学习规则从而克服程序遗忘的方法,让程序在学习一个新任务时能够记得旧的任务。这是程序朝向更智能化,能够持续、自适应地学习迈出的重要一步。
深度神经网络是目前用于解决各种任务(包括机器翻译、图像分类、图像生成等)的最成功的机器学习方法。然而,深度神经网络的设计让它们通常只有在所有数据一次性呈现时才能学习多个任务。在一个特定的任务上训练的网络,其参数只适应解决该特定任务。当引入新任务时,新的适应改写了神经网络在前一个任务上获得的知识。这种现象在认知科学中被称为“灾难性遗忘”,并且被认为是神经网络的基本局限之一。
相比之下,人类的大脑的工作方式与之非常不同。人类能够逐步学习,一次学会一个技能,并且在学习新任务时能够运用先前学到的知识。DeepMind 在最新的 PNAS 论文中,提出一种能够克服神经网络的灾难性遗忘的方法。我们的灵感来源于神经科学中有关哺乳动物和人类大脑固化既往获得的技能和记忆的理论。
神经科学家已经发现,大脑存在两种固化(consolidation)方式:系统固化和突触固化。系统固化是指将大脑中快速学习过程获得的记忆印记到缓慢学习的过程。根据已有研究,这种记忆是由有意识和无意识的回忆所介导的——例如,这个过程有可能在睡梦中发生。第二种机制是突触固化,是指那些在先前的学习任务中扮演重要角色的神经元之间的连接,不太可能被重写。我们的算法就是从大脑的这种机制得到灵感,试图解决灾难性遗忘问题。
学习两项任务过程的示意图:使用EWC算法的深层神经网络能够学习玩一个游戏,然后转移它学到的玩一个全新的游戏。
神经网络由多个连接组成,其连接方式与大脑神经元的连接方式非常相似。在学习一个任务后,我们计算每个连接对该任务而言的重要程度。在学习一个新任务时,根据每个连接对旧任务的重要程度,每个连接被保护以免受修改。因此,神经网络可以学习新任务而不重写在先前任务中已经学会的内容,并且不会导致显着的计算成本增加。从数学的角度来说,我们可以把在一个新任务中每个连接所附加的保护比作弹簧,弹簧的强度与连接的重要性成比例,因此,我们把该算法称为“弹性权重固化”(Elastic Weight Consolidation,EWC)。
为了测试我们的算法,我们依次让代理接触一个个不同的 Atari 游戏。光是根据游戏得分学会玩一个游戏已经是一项很有挑战性的任务了,要依次学会多个游戏的难度更高,因为每个游戏所需的策略都是不同的。如下图所示,如果没有 EWC,代理会在每个游戏停止播放后(蓝色)快速忘记这些游戏的内容。这意味着,平均而言,代理几乎不会学习单个的游戏。然而,如果我们使用 EWC(棕色和红色),代理不会轻易忘记,并可以一个接着一个地学会玩几个游戏。

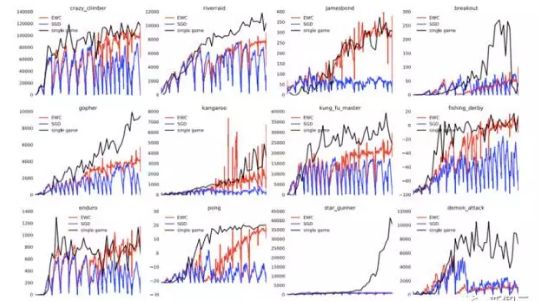
现在,计算机程序还不能自适应地、实时地从数据里学习。然而,我们的研究表明,灾难性遗忘不是神经网络的不可逾越的挑战。我们希望这项研究是朝着更加灵活有效的学习迈出的重要一步。
此外,我们的研究也推进了对人类大脑中信息固化的理解。事实上,我们的工作所基于的神经科学理论在非常简单的例子中已经得到了证实。我们的研究表明,这些相同的理论可以应用在更现实和复杂的机器学习环境中。我们认为,突触巩固是保留记忆和专门知识的关键,也希望大家对这一看法予以更多思考。
论文:克服神经网络灾难性遗忘的问题
我们可以看看 DeepMind 这篇 PNAS 论文的摘要,相信能够帮你更好地理解这项研究。

以顺序方式学习任务的能力对发展人工智能至关重要。直到现在,神经网络还不具备这种能力,业界也广泛认为灾难性遗忘是连接主义模型的必然特征。我们的工作表明,这个局限是可以克服的,我们能够训练网络,让它们将专业知识保留很长一段时间。我们的方法记住以往任务的方法是,选择性地减慢学习一些权重的速度,这些权重是对完成任务很重要的权重。通过识别手写数字数据集和学习一系列 Atari 2600 游戏,我们证明我们的方法是有效并且可扩展的。
AlphaGo 一周年:盘点 DeepMind 技术发展与商业探索
下面,在 AlphaGo 获胜一周年的今天,新智元特意盘点了 DeepMind 在学术研究和商业变现两方面的主要工作。

深度强化学习是 DeepMind 的特长,AlphaGo 正是 DeepMind 在深度强化学习方面积累后的爆发。实际上,DeepMind 自成立以来便专攻围棋,在 AlphaGo 之前就已经发表了多项相关成果,从最早在 NIPS 2013 获得最佳论文奖的 “Playing Atari with Deep Reinforcement Learning”,到 2016 年登上 Nature 封面的 “Masteringthe game of Go with Deep Neural Networks & Tree Search”。
简单说,DeepMind 的工作轨迹可以看做:
- Q-learning
- 强化学习
- Deep Q-Networks(DQN,深度强化学习)
- AlphaGo
2016 年 AlphaGo 获胜后,DeepMind 继续发展深度强化学习:学习过程稳定性、重复试验的优先排序、正常化、收集和校正结果。综合这些方面的提升,在 Atari 游戏中,智能体的平均得分提高了 300%。2016 年上半年,DeepMind 公布,在几乎所有的 Atari 游戏中,他们的智能体都达到了人类的水平。
DQN 之后,DeepMind 发表论文 “Asynchronous Methods for Deep Reinforcement Learning”,提出了异步深度强化学习,利用 CPU 多线程能力做并行计算。这种基于异步评价器(actor-critic)的算法 A3C,结合了 DQN 与用于选择行动的策略网络,在缩短 DQN 训练时间的同时减少了计算资源的消耗。由此,他们在被誉为有史以来最难 Atari 游戏——蒙特祖玛的复仇(Montezuma’s Revenge)中,取得了很好的成绩。
在机器人控制和移动等连续控制问题中,DeepMind 也开发了一系列深度增强学习的方法。Deterministic Policy Gradients(DPG)算法提供了一个具备连续性的 DQN,利用 Q-network 的差异性来解决大量的持续控制任务。异步强化学习在这些领域也都表现得很好,在使用一个分级控制策略来增强时,智能体能在不具备任何先验知识的情况下,解决一些具有挑战性的难题,比如新智元曾经报道过的、下面视频中的蚂蚁足球(ant soccer)。

就在上个月,DeepMind 发表了探索多个智能体之间合作与竞争的研究。他们使用强化学习技术,让智能体通过电子游戏,在类似 “囚徒的困境”的模拟环境中,展示竞争与合作的关系。在题为 “Multi-agent Reinforcement Learning in Sequential Social Dilemmas” 论文的摘要中,DeepMind 的研究员写道:“我们采用深层多代理强化学习来模拟AI 智能体间合作的出现。新的连续社会困境的概念允许我们模拟理性代理如何互动,并根据环境的性质和代理的认知能力达到或多或少的合作行为。研究可以使我们更好地理解和控制复杂的多代理系统的行为,如经济,交通和环境挑战。” 这项研究的结果是,AI 的行为会随着规则的变化而变化,情况取决于获利情况。DeepMind 表示,这个试验表明,现代的人工智能技术(深度多代理强化学习),可以应用于解释社会科学中古老的问题,例如“合作”这种行为出现的奥秘。
AlphaGo背后的英雄 David Silve 和他的研究生还发表论文,介绍了首个在没有任何先验知识的前提下,可扩展的端到端学习近似纳什均衡的方法,题目是“Deep Reinforcement Learning from Self-Play in Imperfect-Information Games”。在这项研究里,他们使用的机制和 AlphaGo 非常相似,结合了深度强化学习技术和虚拟自我对局。实验中,计算机通过自学成功掌握了德州扑克的技巧,表现已经接近人类专家水平,在只使用 6 张扑克牌 Leduc Hold’em 中,计算机会也选择博弈中的最优解。他们所用的算法具有一般性,因此可以推测这种方法可以解决所有策略性问题。
在生成模型方面,DeepMind 也进行了探索,并取得了一些重要的进展。
在发表有关图像生成的 PixelCNN 模型的论文之后,DeepMind 在 2016 年下半年发表了 WaveNet 论文并在其中展示了 WaveNet 生成音频的效果。DeepMind 在新闻稿中写道,WaveNet 通过生成原始的波形而不是将录音的样本拼接在一起,实现了世界上最逼真的语音合成。值得一提,DeepMind 还表示,他们计划将 WaveNet 用于谷歌的产品,让这种技术改进万千用户的产品体验。
另一个重要研究领域就是上文提到的记忆。
与传统计算机不同,神经网络没有“记忆”或者说存储大量信息的能力。因此,将神经网络决策能力和对复杂结构化数据的存储推理能力结合起来,是一个很大的挑战。而 DeepMind 在让神经网络拥有记忆方面,一直在努力探索。
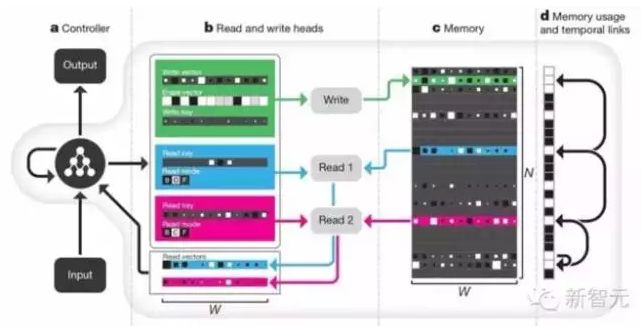
在 2016 年 10 月,DeepMind 发表了 可微分神经计算机(Differentiable Neural Computer,DNC),这也是他们在 18个月之内发表的第三篇 Nature 论文。DeepMind 称,这证明“我们的模型不但可以模仿神经网络的学习过程,而且能像计算机一样存储数据”。DNC 能够理解家谱、在没有先验知识的情况下计算出伦敦地铁两站之间的最快路线,还能解决拼图迷宫。德国研究者 Herbert Jaeger 将 DNC 称为 “升级版神经图灵机(NTM)”,认为 DNC 是目前最接近数字计算机的神经计算系统,该成果有望解决神经系统符号处理难题。
在提出这些理论后,DeepMind 也花时间改进这些系统的学习过程。在一篇题为 “Reinforcement Learning with Unsupervised Auxiliay Tasks”的论文中,DeepMind 描述了一种方法,把特定任务的学习速度提高了一个数量级。
考虑到高质量训练环境对智能体的重要性,DeepMind 在年底 NIPS 2016 会议伊始,宣布开源其内部研究环境 DeepMind Lab,并且和暴雪公司合作开发《星际争霸II》的 AI 训练的环境。

在商业探索方面,DeepMind 与谷歌的数据中心团队合作,将深度强化学习用于节能,发现了管理制冷系统的新方法,使建筑物能耗减少了 15%。这个消息公布出来以后,在业界引发了相当大的震动,主要是此前没有人想到能将深度强化学习用于建筑物节能,并且效果如此之好。目前,DeepMind 正在积极探索将这些技术应用在其他更大型的工业系统上。
此外,DeepMind 也全力进军医疗,成立了 DeepMind Health,在英国积极推进与两家国家卫生署医院在深度学习科研方面的战略合作,其中的一项成果是眼科疾病中十分常见而且亟待解决的问题——糖尿病视网膜病变检测。
前不久,DeepMind 还提出,要使用类似区块链系统的技术,解决数据隐私问题,试图从根本上为智能医疗打开通路。
结语
2017 年,AlphaGo 的升级版 Master 横扫中国棋坛,DeepMind 再次掀起旋风。DeepMind 的目标是“解决智能”(solve intelligence),一路走来,他们不断取得的成果和做出的努力都让人相信,他们确实在致力于实现这一目标。现在,业界公认 DeepMind 是世界上最重要的人工智能玩家,无可置疑的技术优势和人才实力,让他们获得了极高的地位和发言权。
【CSDN在线直播课】Google Tango将人类对空间的感知能力赋予移动设备。它能为应用开发带来哪些新思路?又将如何影响我们的生活?赛格威机器人(Segway Robotics)高级架构师和算法负责人陈子冲,将在《解密Google Tango,从视觉惯性里程计到机器人SLAM》课程中为你逐一解答。扫描下方二维码报名