python 数据结构与算法——并查集
文章目录
- 并查集
- python 实现
- 优化
- union by size
- 路径压缩
并查集
Disjoint Set,实际上字面翻译是不相交的集合。
中文名 “并查集” 实际上源自其基本操作:
- union(X,Y):求并集,指的是包含 X 的集合与包含Y的集合的并集
- find(X): 查元素 X 属于哪个集合
python 实现
一种简单的实现方法是利用数组记录每个元素的集合名,但这样效率太低。
在求并集的时候需要遍历整个数组来对涉及到的集合改名。如下图所示:

优化的策略为改用树结构,以根节点来表示集合名!
如此一来,并、查两个操作等价于:
- union(x,y):将 x 的根节点指向 y 的根节点
- find(x): 找出 x 的根节点
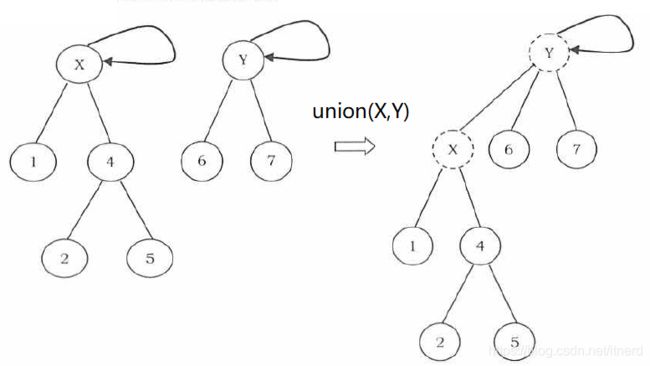
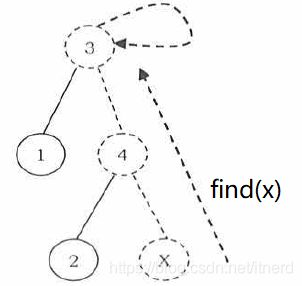
思路清晰,方法也简单:
class DisjointSet:
def __init__(self, n):
self.makeSet(n)
def makeSet(self, n):
self.S = [x for x in range(n)]
def find(self, X):
return X if(self.S[X] == X) else self.FIND(self.S[X])
def union(self, X, Y):
rootX, rootY = self.find(X), self.find(Y)
self.S[rootX] = rootY
def sameSet(self, X, Y):
return self.find(X) == self.find(Y)
测试
def test_disjointSet():
uf = DisjointSet(9)
uf.union(1, 2)
uf.union(3, 4)
uf.union(5, 6)
uf.union(2, 4)
assert(not uf.sameSet(1, 5))
assert(not uf.sameSet(2, 6))
assert (uf.sameSet(1, 3))
assert (uf.sameSet(1, 4))
优化
上面的实现是有缺陷的:没有对树做平衡,可能导致某棵树的某一分支过长,影响查询效率。
试想,如果构造的树退化成一个单项链表,那么查询最末端的叶子节点的集合名的时间代价是 N, 整条链的平均 find 代价也变成了 O ( N ) O(N) O(N)
一种启发式的优化策略是在求并(union)的时候,把元素少的集合 指向 元素多的集合,而不是反之。
这种策略成为 union by size (union by weight)
另一种策略是 union by height, 即把高度小的集合树 指向 高度大的集合树
可以证明,两种策略都可以使集合树的高度保持在 O ( log N ) O(\log N) O(logN)
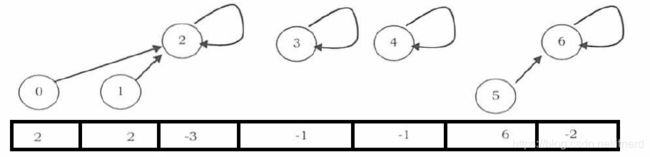
实现上述策略很简单,只要把根节点的值改成负数,用其绝对值代表集合大小即可!
union by size
class DisjointSet:
def __init__(self, n):
self.makeSetBySize(n)
def makeSet(self, n):
self.S = [-1 for _ in range(n)]
def find(self, X):
return X if (self.S[X] < 0) else self.find(self.S[X])
def unionBySize(self, X, Y):
rootX, rootY = self.find(X), self.find(Y)
if(self.S[rootY] < self.S[rootX]):
self.S[rootY] += self.S[rootX]
self.S[rootX] = rootY
else:
self.S[rootX] += self.S[rootY]
self.S[rootY] = rootX
路径压缩
我们还可以继续优化,可以在每次查找时,把路径上的节点都直接指向根节点,在下次 find 该路径上的节点的时间复杂度从 O ( log N ) O(\log N) O(logN) 变成了 O ( 1 ) O(1) O(1) !!!
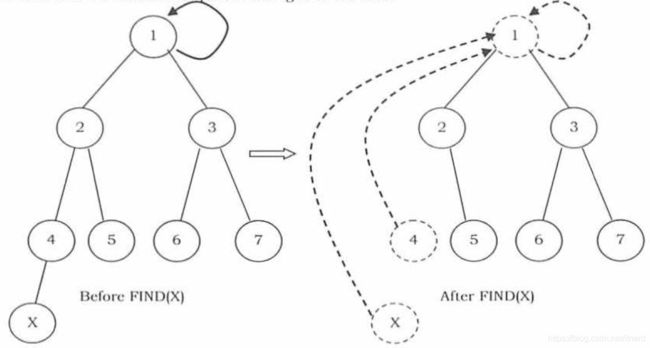
def findBySize(self, X):
if self.S[X] < 0:
return X
self.S[X] = self.findBySize(self.S[X])
return self.S[X]