论文笔记8 --(ReID)Camera Style Adaptation for Person Re-identification
《Camera Style Adaptation for Person Re-identification》
论文:https://arxiv.org/abs/1711.10295v1
Abstract
作为一项跨相机检索任务,由于摄像机的不同,person re-id会收到图像风格变化的影响。在以往的方法中,网络去潜在的学习不受相机风格影响的特征,而本文提出一个camera style (CamStyle) adaptation方法来解决这个问题。CamStyle可以作为一种数据增强方法来平滑相机风格的差异。利用CycleGAN,标注的训练图像可以被转换成每个相机的风格,并与原始训练样本一起形成增强训练集。这种方法提高了数据多样性以防拟合,但也会产生相当大的噪声。为了减轻噪声的影响,作者提出了label smooth regularization (LSR)的方法来缓解。
1. Introduction
Person re-id[37]是一项跨摄像头检索任务。给定一个感兴趣的查询人员,它的目标是从从多个摄像头收集的数据库中检索同一个人。在这个任务中,一个人的形象在外观和背景上经常发生比较大的变化。通过不同的相机拍摄图像是造成这种变化的主要原因(图1)。通常,摄像头在分辨率、环境光照等方面会彼此不同。

在解决相机变化的挑战时,以前的论文选择了一种隐含策略。即就是学习在不同相机下具有不变性的稳定特征表示。传统方法中的例子有:KISSME [13],XQDA [17],DNS [34]等。深度表示学习方法的例子有IDE [37],SVDNet [24],TripletNet [8]等。
与以往的方法相比,本文从相机风格适应的角度出发,提出了一种明确的策略。在基于深度学习的person re-id中,我们主要是受到大数据量需求的推动。为了学习对相机变化具有鲁棒性的能力,标注大型数据集是非常有用的,但却很昂贵。不过,如果我们可以向训练集中添加更多的样本,以了解摄像头之间的样式差异,我们就能够1)解决person re-id中的数据稀缺问题,2)学习不同摄像头之间的不变特性。最好是这个过程不用再花费任何人工标注,从而保持低预算。
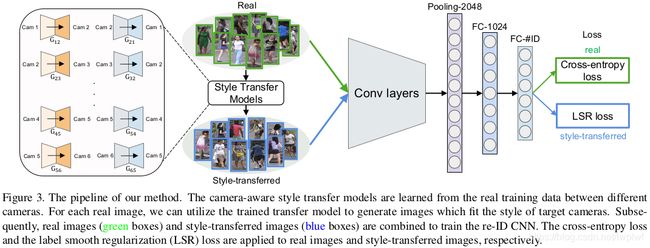
基于以上讨论,我们提出了一种camera style (CamStyle) adaptation方法来规范person re-id的CNN训练,在vanilla版本中,我们使用CycleGAN[41]学习每个相机对的image-image translation模型。利用学习好的CycleGAN模型,对于某个相机拍摄的训练图像,我们可以生成其他相机风格的新训练样本。通过这种方式,训练集是原始训练图像和风格转换图像的组合。风格转换的图像可以直接从原始训练图像借用标注信息。在训练中,我们按照[37]中的baseline model,使用新的训练集进行训练。Vanilla方法有助于减少过拟合并学到相机的不变性,但它也会给系统带来噪声(图2)。在全相机系统(full-camera systems)下,噪声问题盖过了它所带来的收益。为了缓解这一问题,在改进版本中,进一步对风格转换样本应用LSR[25],以便在训练中对其标签进行培训期间对其labels进行柔和分布(softly distributed)。
本文提出的相机风格自适应方法CamStyle有三个优点:
首先,它可以被视为一个数据增强方案,以平滑相机风格的差异。它减少了CNN过度拟合的影响。
第二,通过整合相机信息,它有助于学习具有相机不变性的行人特征。
最后,它是无监督的,由CycleGAN保证,有很好的应用潜力。
综上所述,本文有以下贡献:
- 用于re-id数据增强的普通相机风格转换模型。在少数相机系统中,提升可达到17.1%;
- 在re-id训练中,对风格转换后的样本进一步应用LSR。在全相机系统中,观察到一致的提升。
2. Related Work
Deep learning person re-identification.
很多深度学习方法[33,30,29,3,20]已经在person re-id中被提出。在[33]中,输入图像对分别被分成三个重叠的水平部分,并通过一个siamese CNN模型使用余弦距离来学习它们的相似性。后来,Wu等人[30]通过使用较小的卷积核来增加网络的深度,以获得鲁棒性特征。此外,Varior等人[29]将long short-term memory (LSTM)模型合并到一个可以连续处理图像部分的连体网络中,以便记忆空间信息,以提高深层特征的识别能力。
另一个有效的策略是分类模型,它充分利用了re-id labels[37、31、24、15、23]。Zheng等人[37]提出ID-discriminative embedding (IDE) 训练re-id模型作为图像分类,其从ImageNet[14]预训练模型进行微调。Wu等人[31]通过将手工制作的特征合并到CNN特征中,提出特征融合网络Feature Fusion Net (FFN)。最近,Sun等人[24]使用奇异向量分解迭代地优化FC特征并生成正交权重。
当CNN模型与训练样本数量相比过于复杂时,可能会发生过拟合。针对这一问题,提出了几种数据增强和正则化方法。在[19]中,Niall等人利用背景和线性变换生成各种样本,提高网络的泛化程度。最近,Zhong等人[39]随机擦除输入图像中的矩形区域,这防止模型的过拟合并使模型对遮挡具有鲁棒性。Zhu等人[40]从独立的数据集中随机选择假阳性样本(PseudoPositive samples)作为额外的训练样本来训练re-id CNN,以降低过拟合的风险。更多与此工作相关的,Zheng等人[38]使用DCGAN[21]生成未标记的样本,并为它们分配统一的标签分布以规范网络。与[38]相比,本文工作中的风格转换样式样本是从具有相对可靠标签的真实数据生成的。
Generative Adversarial Networks.
生成对抗网络Generative Adversarial Networks(GANs)[6]近年来取得了令人瞩目的成功,特别是在图像生成方面[21]。最近,GANs还被应用于图像到图像的转换image-to-image translation[10,41,18],风格转换style transfer[5,11]和跨域图像生成cross domain image generation[2,26]。Isola等人[10]应用条件GANs来学习从输入到输出图像的映射,以便图像到图像的转换应用。[10]的主要缺点是它需要成对的相应图像作为训练数据。为了解决这一问题,Liu和Tuzel[18]提出了一种耦合生成对抗网络(CoGAN),通过使用权重共享网络来学习跨域的联合分布。最近,CycleGAN[41]在[10]中引入了基于“pix2pix”框架的循环一致性,以学习没有成对样本的两个不同域之间的图像转换。风格转换和跨域图像生成也可以看作是图像到图像的转换,其中输入图像的风格(或域)在保留原始图像内容的同时被转换到另一个风格(或域)。在[5]中,通过对图像的内容和风格进行分离和重组,引入了一种风格转换方法。Bousmalis等人[2]引入无监督的GAN框架,将图像从源域转换到目标域中的模拟图像。相似性,在[26]中,Domain Transfer Network (DTN)是在保留原始身份的同时,通过合并多类GAN loss来生成unseen domain的图像。与以前主要考虑生成样本质量的方法不同,本工作的目的是使用风格转换样本来提高re-ID的性能。
3. The Proposed Method
在本节中,我们首先简要回顾3.1节中的CycleGAN[41]。然后,我们将在第3.2节中使用CycleGAN描述camera-aware数据生成过程。LSR的baseline和训练策略分别在第3.3节和第3.4节中描述。总体框架如图3所示。
3.1. CycleGAN Review
给定两个来自两个不同域的数据集A和B, x i ∈ A x_{i}\in A xi∈A , y i ∈ B y_{i}\in B yi∈B
![]()
CycleGAN的目标是学习映射函数,G:A→B使得G(A)的图像分布和B的图像分布是难以区分的。CycleGAN包含两个映射函数G:A→B和F:B→A,同样,F:B→A使得F(B)与A的分布类似。 D A D_{A} DA和 D B D_{B} DB是对抗判别器。CycleGAN应用GAN框架来共同训练生成和判别模型。整个CycleGAN损失函数为:
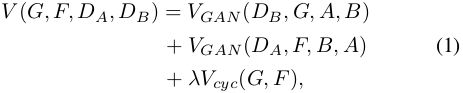
其中, V G A N V_{GAN} VGAN映射函数和判别器的损失函数, V c y c ( G , F ) V_{cyc}(G,F) Vcyc(G,F)是循环一致性损失,使得F(G(x))约等于x和G(F(y))约等于y,也就是说每个图片经过循环映射能够得到恢复。λ是 V G A N V_{GAN} VGAN和 V c y c V_{cyc} Vcyc之间重要性的惩罚项。更多关于CycleGAN的细节见[41]。
3.2. Camera-aware Image-Image Translation
本文使用CycleGAN生成新的训练样本:不同相机风格的图片被认为是不同的域domains。通过CycleGAN,本文对每对相机学习一个图像到图像的模型。为了保持输入输出图片颜色的一致性,在公式(1)中加入了identity mapping loss[41],使得生成器在使用目标域的真实图片作为输入时,能够近似于identity mapping。identity mapping loss可以表示为:

具体的,对于训练图片,使用CycleGAN对每对相机生成camera-aware风格转换模型。按照[41]中的训练策略,所有图片被resize到256×256。我们使用与CycleGAN相同的架构来实现camera-aware风格转换网络。包含9个残差块和4个卷积,判别器discriminator为70×70PatchGANs[10]。
使用学习的CycleGAN模型,对于每个相机下的训练图片,我们生成L-1个新的训练图片,其风格和对应相机相似(如图2所示),并将生成的图像称为style-transferred image或fake image。通过这种方式,训练集被增强为原始图像和风格转换图像的组合。由于每个风格转换的图像保留了原始图像的内容,因此新样本与原图像是相同的标签。
Discussions
如图4所示,所提出的数据增强方法的工作机制主要包括:
real images和fake (style-transferred) images之间的相似数据分布;- 保留fake images的ID标签。一方面,fake填补了real数据点之间的空白,并在特征空间中略微扩展了类边界。这保证了在嵌入学习期间,增强的数据集通常支持更好地描述类分布。另一方面,支持使用监督学习supervised learning[37],这是一种不同于[38]的机制,它利用未标记的GAN图像进行正则化。
3.3. Baseline Deep Re-ID Model
将real images和fake images作为输入,使用ID-discriminative embedding (IDE)[37]训练模型。使用Softmax loss,IDE将re-ID训练视为图像分类任务。网络如图3所示。所有输入图像resize为256×128。使用ResNet-50[7]作为主干,并遵循[37]中的训练策略对ImageNet预训练模型进行微调。丢弃了最后的1000维分类层并添加了两个全连接层。第一个FC层“FC-1024”输出1024维,然后是bn[9]、relu和dropout[22]。添加“FC-1024”遵循[24]中的做法,从而提高了精度。第二个FC层的输出是C维的,其中C是训练集中的类数。
3.4. Training with CamStyle
本节讨论了使用CamStyle的训练策略。当我们同等看待real和fake时,方法叫vanilla version。另一方面,考虑fake带来的噪声问题,加入label smooth regularization (LSR)[25],叫作full version。
Vanilla version
在vanilla版本中,新训练集中(real+fake)所有样本被同等看待,即每一个样本仅属于单个id。在训练中,在每个mini-batch中随机选取M个real images和N个fake images。损失函数为:

其中, L R L_{R} LR, L F L_{F} LF表示交叉熵损失cross-entropy loss,其可表示为:

其中,C是类的数量。p(c)是属于label c的输入的预测概率,p(c)由softmax归一化得到,
![]()
q(c)表示gt分布。因为每个人在新的训练集中只属于一个id。所以 q(c) 可被定义为:

因此交叉熵可以写为:
![]()
因为real和fake数据在分布上的相似性,在few cameras情况下,vanilla version能够提升baseline IDE正确率。
Full version
style-transferred images能够增加样本量,但也引入了噪声。在少数相机系统下,由于缺乏数据,所以vanilla version能够缓解过拟合。但在更多的相机下,数据足够多时,过拟合问题不再是主要问题了,风格转换带来的噪音问题开始出现。
转换噪声主要来源于:
- CycleGAN并不是一个完美的转换模型,因此在图片生成过程中会发生错误;
- 由于本身的遮挡和检测错误,在real数据中存在噪音样本,转化这些噪音样本可能产生更多的噪音样本。
图4是real和fake数据在二维空间上的深层特征可视化的一些示例。大多数生成的样本分布在原始图像周围,当转换错误发生时(图4©、(d)),fake样本将是一个噪声样本并且远离真实分布。当real image是噪声样本时(图4(b)、(d)),它远离具有相同标签的图像,因此生成的样本也会产生噪声。

为了缓解这个问题,提出LSR[25]方法,对于生成了图片的label,加入一个平滑因子 ε \varepsilon ε,最终label为:

此时的交叉熵可以写为:

对于real images,不使用LSR,因为它们的标签本身能够正确匹配。同时实验也证明了full-camera系统下,在real images上添加LSR并不能提升表现(见4.4小节)。所以仅在style-transferred images上使用LSR,设置 ϵ = 0.1 \epsilon=0.1 ϵ=0.1,loss为: L F = L L S R ( ϵ = 0.1 ) L_{F}=L_{LSR}(\epsilon=0.1) LF=LLSR(ϵ=0.1)
PS:其实就是加一个平滑因子 ϵ \epsilon ϵ,使得生成图像和原型图像是相同ID的概率接近于1但又不等于1。
Discussions
最近,Zheng等人[38]建议使用label smoothing regularization for outliers (LSRO)通过DCGAN[21]生成未标记样本。在[38]中,由于生成的图像没有标签,因此将均匀的标签分布分配给生成的样本,即 L L S R ( ϵ = 1 ) L_{LSR}(\epsilon=1) LLSR(ϵ=1)。与LSRO相比,本文系统有两个不同之处:
- 根据相机风格生成fake images。CycleGAN的使用确保了生成的图像仍然是人的主要特征(图5提供了一些可视化比较)。
- 本文系统中的标签更可靠。使用LSR来处理一小部分不可靠数据,而LSRO则用于没有标签可用的情况。

PS:图1(b)可以看到CycleGAN转化的结果,可以看到样本的Camera Style被迁移过去了。原来绿衣服的人迁移过去变成蓝色,但他们是同一个人,属于同一个id,外观不一样是因为相机所处的光线环境不一致。很显然,这种bias对Re-ID影响是很大的,而通过CycleGAN可以减小这种bias。
4. Experiment
4.1. Datasets
数据使用的是Market-1501[36]和DukeMTMC-reID[38]。
4.2. Experiment Settings
Camera-aware style transfer model
根据第3.2小节,分别为Market-1501和DukeMTMC-reID训练 C 6 2 = 15 C^{2}_{6}=15 C62=15和 C 8 2 = 28 C^{2}_{8}=28 C82=28的CycleGAN模型。在训练期间,将所有输入图像的大小resize为256×256,并使用Adam优化器[12]从头开始训练模型,λ=10。设置batch size=1,Generator的学习率learning rate=0.0002,Discriminator在前30个epoch学习率为learning rate=0.0001,其余20个epoch的学习率线性降为零。在camera-aware风格转换步骤中,每个训练图像生成L−1(Market-1501:5,DukeMTMC-reID:7)个fake训练图像。
Baseline CNN model for re-ID
遵循[37]中的训练策略来训练baseline。将所有图像resize为256×128。在训练过程中,对输入图像进行随机裁剪和水平翻转。dropout设为p=0.5。使用ResNet-50[7]作为主干backbone,其中第二个全连接层分别具有751和702个单元用于Market-1501和DukeMTMC-reID。batch size=128。对于resnet-50基础层,学习率从0.01开始,对于两个新添加的全连接层,学习率从0.1开始。学习率在40个epoch后除以10,总共训练了50个epoch。使用SGD来训练re-ID模型。在测试时,提取pool5层的输出作为图像描述符(2048-dim),并使用Euclidean计算图像之间的相似性。
Training CNN with CamStyle
training mini-batch中,随机选择样本比例设置为M:N=3:1,因为fake images的数量比real images多,因此在每个epoch中,我们使用所有的real images 并随机选取 N M × 1 L − 1 \frac{N}{M}×\frac{1}{L-1} MN×L−11比例的fake images。
4.3. Parameter Analysis
CamStyle的参数 M N \frac{M}{N} NM对结果的影响如下图:

当在每个mini-batch中使用比real(M:N <1)更多的fake时,rank-1略微提高了1%。当M:N> 1时,rank-1有超过2%的提升。当M:N=3:1时,实现最佳性能。
4.4. Variant Evaluation
Baseline evaluation
为了充分展示CamStyle的有效性,本文的baseline系统分别由2、3、4、5、6号Market-1501相机和2、3、4、5、8号DukeMTMC-reID相机组成。例如,在一个有3个相机的系统中,训练和测试集都有3个相机。在图8中,随着相机数量的增加,rank-1准确率增加。这是因为:
- 有更多的训练数据可用
- 当数据库中存在更多ground truths时,更容易找到一个rank-1真实匹配。
在full-camera (6 for Market-1501 and 8 for DukeMTMC-reID)baseline系统中,在Market-1501上的rank-1为85.6%,在DukeMTMC-reID上的rank-1为72.3%。

Vanilla CamStyle improves the accuracy of few-camera systems
首先在图8和表1中评估vanilla方法(无LSR)的有效性。有两个观察结果。
- 首先,在有2个相机的系统中,Vanilla CamStyle比baseline CNN有显著提升。在Market-1501的2个相机数据下,提升幅度达到了+17.1%(从43.2%提高到60.3%)。DukeMTMC-reID的2个相机数据下,rank-1从45.3%提高到54.8%。这表明,由于缺乏训练数据,少量相机系统容易过拟合,且本文方法表现出很好的性能提升。
- 其次,随着系统中相机数量的增加,vanilla CamStyle的提升幅度越来越小。例如,在Market-1501上的6摄像头系统中,rank-1的提高仅为+0.7%。这表明:1)在整个系统中,过拟合问题变得不那么严重;2)CycleGAN带来的噪声开始对系统精度产生负面影响。
LSR is effective for CamStyle
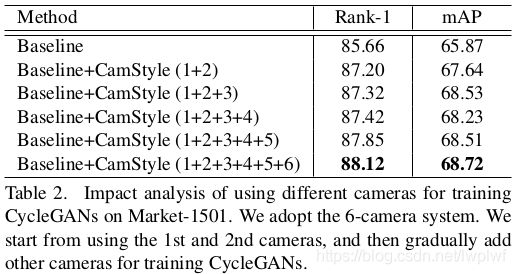
如前文所述,当在具有3个相机的系统中进行测试时,Vanilla CamStyle相比2个相机系统实现的提升更少。图8和表1表明,在fake images上使用LSR loss实现了比交叉熵cross-entropy更高的性能。如表1所示,在Market-1501全相机系统下,使用风格转换数据的交叉熵将rank-1提高到86.31%。在fake数据上用LSR替换交叉熵将rank-1提高到了88.12%。
特别地,图8和表1显示仅在real data上使用LSR对full-camera系统没有太大帮助,甚至会降低性能。因此,具有LSR的CamStyle在baseline上的提升这一事实并不仅仅归因于LSR,而是LSR与fake images之间的相互作用。通过这个实现,证明了在fake images上使用LSR的必要性。
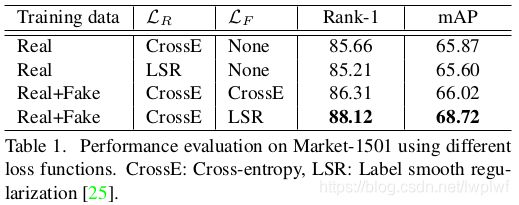
The impact of using different cameras for training camera-aware style transfer models
表2表明,使用更多的相机来训练camera-aware风格转换模型,rank-1从85.66%提高到了88.12%。特别是,即使只使用第1个和第2个相机来训练,本文方法也能获得rank-1 +1.54%的提升。此外,使用5个相机训练时,rank-1=87.85%,比使用6个低0.27%。这表明,即使使用一部分相机来训练camera-aware风格转换模型,本文方法也可以产生与所有相机大致相同的结果。
CamStyle is complementary to different data augmentation methods.
为了进一步验证CamStyle,将它与两种数据增强方法,随机翻转+随机裁剪(RF + RC)和随机擦除(RE)[39]进行比较。RF+RC是CNN训练中[14]的常用技术,用于提高图像翻转和目标转换的鲁棒性。RE旨在实现遮挡的不变性。
如表3所示,当不使用数据增强时,rank-1=84.15%。当仅使用RF+RC、RE、或CamStyle是,rank-1分别为85.66%、86.83%和85.01%。此外,如果将CamStyle与RF+RC或RE结合使用,相比单独使用,各种组合下都得到了提升。三种方法一起使用时,可以实现最佳性能。因此,虽然3种截然不同的数据增强方法都集中在CNN不变性的不同方面,但实验结果表明,CamStyle与其它两种方法完全互补。

4.5. Comparison with the state-of-the-art methods
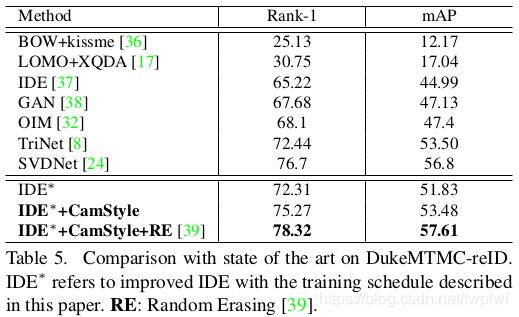
表4、5中本文方法分别与Market-1501和DukeMTMC-reID上的最新方法进行了比较。首先,使用本文的baseline训练策略,作者在两个数据集上获得了强大的baseline(IDE*)。具体,IDE在Market-1501和DukeMTMC-reID上的rank-1分别为85.66%和72.31%。与已发布的IDE实现[24, 38, 37]相比,IDE在Market-1501上是最佳的rank-1。
然后,当在IDE*上应用CamStyle时,在Market-1501上rank-1=88.12%,比PDF[23],TriNet[8]和DJL[16]更高,在DukeMTMC-reID上rank-1=75.27%。另一方面,mAP在Market-1501上比TriNet[8]略低0.42%,在DukeMTMC-reID上低于SVDNet[24]3.32%。
进一步将CamStyle与随机擦除RE数据增强相结合[39](RF + RC已经在基线中实现),最终rank-1在Market-1501上为89.49%,在DukeMTMC-reID上为78.32%。

5. Conclusion
本文提出了CamStyle,一种用于深度person re-id的相机风格自适应方法camera style adaptation。使用CycleGAN为每对相机学习camera-aware风格转换模型,这些模型用于从原始图像生成新的训练图像。real images和style-transferred images构成了新的训练集。此外,为了减轻CycleGAN引起的噪声增加,在生成的样本上应用label smooth regularization (LSR)。 Market-1501和DukeMTMC-reID数据集上的实验表明,本文方法可以有效地减少过拟合的影响,并且与LSR结合使用时,比baselines都有所提升。此外,本文方法还是对其它数据增强技术的补充。