hadoop客户端远程调用yarnwindow和Linux版本安装
文章目录
- window(个人已经验证成功)
- 1、 下载
- 1.1、 hadoop(apache)
- 1.2、 winutils.exe和hadoop.dll下载
- 2、 安装
- 2.1、 下载好了压缩包,只需要把对应版本的 winutils.exe和hadoop.dll移到自己下载的hadoop路径的bin目录下即可,正常的话就是完成了。
- 2.2、 在系统环境变量里面的系统设置,添加HADOOP_HOME,路径是你解压hadoop-2.6.0.tar.gz的路径
- 2.3、 再在系统环境配置里面找到Path进行添加bin和sbin路径
- LINUX (个人已经验证成功)
- 1. 下载资源
- 2. 配置Linux文件
- ubuntu(未验证,提供个参考链接)
- 实践代码
- 建立hdfs测试文件
- MapperOne
- ReduceOne
- JobSubmitter(window)
- JobSubmitter(Linux)
- pom.xml
- log4j.properties
- 执行main方法就可以正常打印了。
特别重要,hadoop客户端安装的版本一定要和你开发的软件idea安装的版本一致,可以高于集群的版本,我测试过2.10.0的版本,集群是2.6.0的版本。
window(个人已经验证成功)
1、 下载
window版本安装参考文档:
https://blog.csdn.net/MercedesQQ/article/details/16885115?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.edu_weight&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.edu_weighthttps://blog.csdn.net/chenzhongwei99/article/details/72518303
hadoop官网:http://hadoop.apache.org/
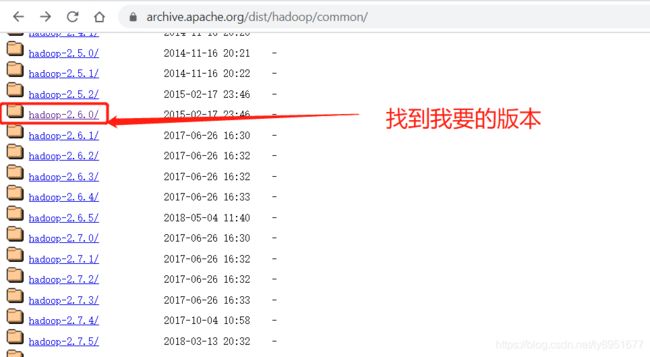
历史版本:https://archive.apache.org/dist/hadoop/common/
我要的2.6.0版本:https://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz1
1.1、 hadoop(apache)



1.2、 winutils.exe和hadoop.dll下载
下载链接:
==https://download.csdn.net/download/ly8951677/12569339
本人找了好久资源也在csdn上传了(以上超链接),有分捧个分场,没分捧个人场。
也可以去github下载:https://github.com/steveloughran/winutils
2、 安装
2.1、 下载好了压缩包,只需要把对应版本的 winutils.exe和hadoop.dll移到自己下载的hadoop路径的bin目录下即可,正常的话就是完成了。

2.2、 在系统环境变量里面的系统设置,添加HADOOP_HOME,路径是你解压hadoop-2.6.0.tar.gz的路径

2.3、 再在系统环境配置里面找到Path进行添加bin和sbin路径
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin

验证是否成功,使用键盘快捷键:win+r,输入cmd:

执行以下命令
C:\Users\TT>cd D:\WorkingProgram\hadoop-2.6.0\etc\hadoop
C:\Users\TT>d:
D:\WorkingProgram\hadoop-2.6.0\etc\hadoop>hadoop fs -ls /
Found 62 items
d--------- - S-1-5-21-2461075959-685466935-2156076090-1000 S-1-5-21-2461075959-685466935-2156076090-513 4096 2018-12-31 10:09 /$RECYCLE.BIN
drwxrwx--- - SYSTEM NT AUTHORITY\SYSTEM 0 2017-12-04 14:01 /AliWorkbenchData
drwx------ - Administrators S-1-5-21-3628364441-319672399-1304194831-513 4096 2020-06-02 10:10 /BaiduNetdiskDownload
在这过程中遇到了一些情况,和大家分享下,不同机器环境不同异常
##打开cmd执行以下命令,去验证hadoop是否可以正常运行
C:\Users\TT>cd D:\WorkingProgram\hadoop-2.6.0\etc\hadoop
C:\Users\TT>d:
D:\WorkingProgram\hadoop-2.6.0\etc\hadoop>hadoop fs -ls /
Error: JAVA_HOME is incorrectly set.
异常:==Error: JAVA_HOME is incorrectly set.==是由于java_home没有配置。简单的方法就去手动指定jdk路径就好。
修改hdoop-evn.cmd文件window系统,Linux系统是修改:hadoop-env.sh文件。我习惯修改前先备份文件,有啥事改文件名就可以了。

我的jre安装路径是:C:\Program Files\Java\jre1.8.0_201
查询命令可以在cmd控制台输入:java -verbose

然后就可以更改了。
##原来的
set JAVA_HOME=%JAVA_HOME%
##改为以下,这里特别注意==PROGRA~1代替Program Files==
set JAVA_HOME=C:\PROGRA~1\Java\jre1.8.0_201
这里特别注意PROGRA~1代替Program Files

LINUX (个人已经验证成功)
参考资源:
https://www.linuxidc.com/linux/2012-06/63560.htm
1. 下载资源
和window一样
2. 配置Linux文件
[root@slave01 ~]# vim /root/.bashrc
#最后一行末尾添加自己的hadoop解压出来的路径。我把解压到/data/program目录了,顺便改了文件夹名称。
alias hadoop='/data/program/hadoop/bin/hadoop'
#保存退出文件编辑,执行文件配置生效命令
[root@slave01 ~]# source /root/.bashrc
##完成,测试是否成功,随便在哪个目录
[root@slave01 ~]# hadoop classpath
/data/program/hadoop/etc/hadoop:/data/program/hadoop/share/hadoop/common/lib/*:/data/program/hadoop/share/hadoop/common/*:/data/program/hadoop/share/hadoop/hdfs:/data/program/hadoop/share/hadoop/hdfs/lib/*:/data/program/hadoop/share/hadoop/hdfs/*:/data/program/hadoop/share/hadoop/yarn/lib/*:/data/program/hadoop/share/hadoop/yarn/*:/data/program/hadoop/share/hadoop/mapreduce/lib/*:/data/program/hadoop/share/hadoop/mapreduce/*:/contrib/capacity-scheduler/*.jar
##也可以访问远程的大数据集群,前提是网络都通的情况下。
[root@slave01 ~]# hadoop fs -ls hdfs://master:8082/
##这样就可以了。完美

ubuntu(未验证,提供个参考链接)
https://blog.csdn.net/j3smile/article/details/7887826?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-10.edu_weight&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-10.edu_weight
实践代码
开发环境:
IDE: IDEA2020.1.2
(我试过20201.0版本,执行时hadoop依赖包找不到,本来就有了。查了资料说是idea版本问题,后来升级到1.2,果然成功了。)
系统版本:window 10 旗舰版
jdk版本:jdk1.8.0_161
maven环境
集群hadoop:cdh15.15.1
客户端hadoop:apache的hadoop-2.6.0==(这里的hadoop版本一定要和开发环境的hadoo-client版本一致,要不会有异常执行不了。切记,切记,切记)==
总共就三个类,MapperOne、ReduceOne、Jobsubmitter
建立hdfs测试文件
##现在hadoop集群上面操作
cd /data/
vim /test.log
##填入内容
nihao wolaile chif
hello word
##保存退出
hdfs dfs -mkdir /wordcount/input/
hdfs dfs -put test.log /wordcount/input/
MapperOne
package com.test.service;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MapperOne extends Mapper<LongWritable, Text, Text, IntWritable>
{
private static final IntWritable one = new IntWritable(1);
private Text words = new Text();
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.words.set(itr.nextToken());
context.write(this.words, one);
}
}
}
ReduceOne
package com.test.service;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class ReduceOne extends Reducer<Text, IntWritable, Text, IntWritable>
{
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException
{
int count = 0;
Iterator iterator = values.iterator();
while (iterator.hasNext()) {
IntWritable value = (IntWritable)iterator.next();
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
JobSubmitter(window)
package com.test.controller;
import com.test.service.MapperOne;
import com.test.service.ReduceOne;
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobSubmitter
{
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {
String hdfsUri = "hdfs://BdataMaster01:8020";
System.setProperty("HADOOP_USER_NAME", "hdfs");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", hdfsUri);
//这四行是提交到yarn那边的配置,去掉的话就是使用默认:mapreduce.app-submission.cross-platform false,在本地hadoop环境运行的,不用提交到yarn可以把下面的yarn值,和hostname去掉。
conf.set("mapreduce.framework.name" ,"yarn");
conf.set("yarn.resourcemanager.hostname", "BdataMaster01");
//若是在winddow客户端运行,需要修改为true,默认false。
conf.set("mapreduce.app-submission.cross-platform", "true");
//若是在hadoop集群,可以不用加这个,默认都是找得到这些信息的。要加的话再集群上面随便一台机子的命令台上敲打:hadoop classpath,然后进行复制就可以了
conf.set("yarn.application.classpath","/etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop/lib/*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop/.//*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-hdfs/./:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-hdfs/lib/*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-hdfs/.//*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-yarn/lib/*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-yarn/.//*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/.//*");
Job job = Job.getInstance(conf);
job.setJobName("TT_window");
//测试过,不setJar包也可以,指定class,setJarByClass是行的。
// job.setJarByClass(JobSubmitter.class);
job.setJar("D:/WorkingProgram/ideworkspace/Hadoop-Client/MapReduce-Client-01/target/MapReduce-Client-01-1.0-SNAPSHOT.jar");
job.setMapperClass(MapperOne.class);
job.setReducerClass(ReduceOne.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path outPut = new Path("/wordcount/output");
FileSystem fs = FileSystem.get(new URI(hdfsUri), conf, "hdfs");
if (fs.exists(outPut)) {
fs.delete(outPut, true);
}
// /user/hive/warehouse/jg_users/jgallusers.log
// FileInputFormat.addInputPath(job, new Path("/wordcount/input/test_jop.log"));
FileInputFormat.setInputPaths(job,new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job, outPut);
job.setNumReduceTasks(1);
boolean res = job.waitForCompletion(true);
System.out.println("jobid==========="+job.getJobID().toString());
System.exit(res ? 0 : 1);
}
}
JobSubmitter(Linux)
package com.test.controller;
import com.test.service.MapperOne;
import com.test.service.ReduceOne;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobSubmitter
{
public static void mainLinux(String[] args) throws IOException, URISyntaxException, InterruptedException, ClassNotFoundException {
String hdfsUri = "hdfs://BdataMaster01:8020";
System.setProperty("HADOOP_USER_NAME", "hdfs");
System.setProperty("hadoop.home.dir", "/");
Configuration conf = new Configuration();
conf.set("fs.defaultFS", hdfsUri);
//这四行是提交到yarn那边的配置,去掉的话就是使用默认:mapreduce.app-submission.cross-platform false,在本地hadoop环境运行的。
conf.set("mapreduce.framework.name" ,"yarn");
conf.set("yarn.resourcemanager.hostname", "BdataMaster01");
//若是在hadoop集群,可以不用加这个,默认都是找得到这些信息的。要加的话再集群上面随便一台机子的命令台上敲打:hadoop classpath,然后进行复制就可以了
conf.set("yarn.application.classpath","/etc/hadoop/conf:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop/lib/*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop/.//*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-hdfs/./:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-hdfs/lib/*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-hdfs/.//*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-yarn/lib/*:/opt/cloudera/parcels/CDH-5.15.2-1.cdh5.15.2.p0.3/lib/hadoop/libexec/../../hadoop-yarn/.//*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/.//*");
// conf.set("mapreduce.app-submission.cross-platform", "true");
Job job = Job.getInstance(conf);
job.setJobName("TT_LINUX");
job.setJarByClass(JobSubmitter.class);
// job.setJar("D:/WorkingProgram/ideworkspace/Hadoop-Client/MapReduce-Client-01/target/MapReduce-Client-01-1.0-SNAPSHOT.jar");
job.setMapperClass(MapperOne.class);
job.setReducerClass(ReduceOne.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path outPut = new Path("/wordcount/output");
FileSystem fs = FileSystem.get(new URI(hdfsUri), conf, "hdfs");
if (fs.exists(outPut)) {
fs.delete(outPut, true);
}
// /user/hive/warehouse/jg_users/jgallusers.log
// FileInputFormat.addInputPath(job, new Path("/wordcount/input/test_jop.log"));
FileInputFormat.setInputPaths(job,new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job, outPut);
job.setNumReduceTasks(1);
boolean res = job.waitForCompletion(true);
System.out.println("jobid==========="+job.getJobID().toString());
System.exit(res ? 0 : 1);
}
}
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>Hadoop-ClientartifactId>
<groupId>com.testgroupId>
<version>1.0-SNAPSHOTversion>
parent>
<modelVersion>4.0.0modelVersion>
<artifactId>MapReduce-Client-01artifactId>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.6.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-jar-pluginartifactId>
<version>2.6version>
<configuration>
<archive>
<manifest>
<addClasspath>trueaddClasspath>
<useUniqueVersions>falseuseUniqueVersions>
<classpathPrefix>lib/classpathPrefix>
<mainClass>com.snm.controller.JobSubmittermainClass>
manifest>
archive>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-dependency-pluginartifactId>
<version>3.0.0version>
<executions>
<execution>
<id>copy-dependenciesid>
<phase>packagephase>
<goals>
<goal>copy-dependenciesgoal>
goals>
<configuration>
<outputDirectory>${project.build.directory}/liboutputDirectory>
configuration>
execution>
executions>
plugin>
plugins>
build>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
properties>
project>
log4j.properties
# priority :debug> Method: %l ]%n%p:%m%n
#debug log
log4j.logger.debug=debug
log4j.appender.debug=org.apache.log4j.DailyRollingFileAppender
log4j.appender.debug.DatePattern='_'yyyy-MM-dd'.log'
log4j.appender.debug.File=./log/debug.log
log4j.appender.debug.Append=true
log4j.appender.debug.Threshold=DEBUG
log4j.appender.debug.layout=org.apache.log4j.PatternLayout
log4j.appender.debug.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss a} [Thread: %t][ Class:%c >> Method: %l ]%n%p:%m%n
#warn log
log4j.logger.warn=warn
log4j.appender.warn=org.apache.log4j.DailyRollingFileAppender
log4j.appender.warn.DatePattern='_'yyyy-MM-dd'.log'
log4j.appender.warn.File=./log/warn.log
log4j.appender.warn.Append=true
log4j.appender.warn.Threshold=WARN
log4j.appender.warn.layout=org.apache.log4j.PatternLayout
log4j.appender.warn.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss a} [Thread: %t][ Class:%c >> Method: %l ]%n%p:%m%n
#error
log4j.logger.error=error
log4j.appender.error = org.apache.log4j.DailyRollingFileAppender
log4j.appender.error.DatePattern='_'yyyy-MM-dd'.log'
log4j.appender.error.File = ./log/error.log
log4j.appender.error.Append = true
log4j.appender.error.Threshold = ERROR
log4j.appender.error.layout = org.apache.log4j.PatternLayout
log4j.appender.error.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss a} [Thread: %t][ Class:%c >> Method: %l ]%n%p:%m%n
#log level
#log4j.logger.org.mybatis=DEBUG
#log4j.logger.java.sql=DEBUG
#log4j.logger.java.sql.Statement=DEBUG
#log4j.logger.java.sql.ResultSet=DEBUG
#log4j.logger.java.sql.PreparedStatement=DEBUG
执行main方法就可以正常打印了。
