系统设计 | 设计限流器
本文根据educative课程整理的学习笔记,侵删
题目
设计限流服务(限制范围:集群内的某个API),根据用户请求数量来限制用户请求
难度:easy
核心考点:几种限流算法
限流算法的目的就是T时间内控制事件数量不超过N,如果超过N则拒绝;
结论:从限制准确性和存储成本两个角度,我们选用了方案3,带计数器的滑动窗口算法;
1. 朴素计数器
- 维护一个计数器count和起始时间startTime,count表示[startTime … curTime]的请求数;startTime过期后,重新设置startTime,并重置count;
假定一个user限制每分钟请求3次;我需要维护一个hash,key=userID,value={count, startTime};收到一个请求后,rate limiter有如下步骤
`# step 1
if userID not in hash:
hash[userID] = {1, current_time}
accept req
# step 2
`if userID in hash and current_time - hash[userID].startTime >= 1min:
# 赋值startTime
hash[userID] = {1, current_time}
accept req
# step 3
if userID in hash and current_time - hash[userID].startTime < 1min:
if hash[userID].count < 3:
accept req
hash[userID].count++
else:
reject req
问题
- 不连续导致的精确度问题:每T时间清零计数导致限制不准确;有可能T内出现2N个事件;这个图,应该在0min加一个事件,这样m4发生的时候,才会清空startTime,
举例:两个T时间段,[T1, T2) 和 [T2, T3),如果第一段时间的后半段[T1 + T/2, T2)出现N个事件,第二段时间前半段[T2, T2 + T/2)出现N个事件,则[T1 + T/2, T2 + T/2)时间内出现2N个事件;
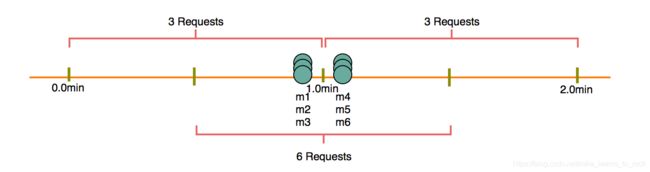
这个算法实际限制的是T时间内出现N ~ 2N事件
- 还有其他问题么?需要仔细
2. 存储问题
按照存储一百万用户信息来计算,分析每个字段的存储空间
userID:8 bytes
epoch:4 bytes (int32 0 ~ 2 Billion)
count: 2 bytes(short 0 ~ 65K)
hash-table:overhead 大概20 bytes
total = (8 + 4 + 2 + 20)bytes * 1 million = 34MB
- epoch的存储可以精简么?
- 还需要存储其他的么?考虑并发场景
这种方法元数据存储占用并不高,存储和N无关
这很容易适用于一台服务器; 我们不希望所有的流量都路由到一台机器。另外,如果我们假设速率限制为每秒10个请求,限制器服务会到1000万个QPS !这对于单个服务器来说是太多了。实际上,我们可以假设我们将在分布式场景中使用Redis或Memcached类型的解决方案。我们将在远程Redis服务器中存储所有数据,所有限流器服务将读取(并更新)这些服务器,然后服务或限制任何请求。简言之,限流器服务做成无状态的;压力转移到Redis服务器;
2.滑动窗口算法
如果我们可以跟踪每个用户的每个请求,我们可以维护一个滑动窗口。我们可以将每个请求的时间戳存储在散列表的“value”字段的Redis排序集中。
user1 : {UnixTime1, UnixTime2, UnixTime3}
- 存储每个请求的时间戳,按照时间戳有序,每来一个请求,查询队列首的时间戳T,if gap <= T - curTime 弹出 else 计算队列中元素数量size;size < N 接收请求 else 丢弃;
存储空间
userID: 8 bytes
UnixTime: 4 bytes
sortedSet: overhead 20 bytes
hashTable: overhead 20 bytes
total = (8 + 4N + 20N + 20) bytes * 1 million = (24N + 28) MB
空间复杂度 O(N),如果N=500,例如用户配置,1小时内限制500个,存储空间需要12GB,存储是个劣势;
3. 带计数器的滑动窗口算法
你能想到优化的方向么?我刚开始局限在精确的timestamp里;我是这样思考的:
step1: 方向肯定是去除UnixTime的存储,但是去除UnixTime,我们就需要存储一段时间T内的次数;
step2:但是如果T过大,限制就不准确,出现算法1的情况;那么如果将T缩小呢,例如用户限制1小时的,我们存储每分钟的请求次数;就可能存储从0 - 59分钟,每分钟的次数;每次只需要根据sum(count per minute)来计算最近一小时内的N;user1 : {UnixTime1 : 1, UnixTime2 : 0, UnixTime3 : 5 }
存储
userID: 8 bytes
UnixTime for minutes: 8 bytes
count : 2 bytes
value hash table: overhead 20 bytes
total hash table: overhead 20 bytes
total = (8 + (8 + 2 + 20) * 60 + 20) * 1 million = 1.8 GB
相比于简单的滑动窗口,存储空间节约了,(12 - 1.8) / 12 = 85%
扩展性
分区sharding
我们可以根据“UserID”进行切分,以分发用户的数据。对于容错和复制,我们应该使用一致的哈希。
如果我们想为不同的API设置不同的节流限制,我们可以选择对每个用户每个API进行切分。以网址缩短器为例;对于每个用户或IP,我们可以为createURL()和deleteURL() api设置不同的速率限制器。
如果我们的API是分区的,一个实际的考虑可能是为每个API碎片也设置一个单独的(稍微小一些的)速率限制器。让我们以我们的URL缩短器为例,我们希望限制每个用户每小时创建不超过100个短URL。假设我们的createURL() API使用基于散列的分区,那么我们可以对每个分区进行速率限制,允许用户在每分钟创建不超过3个短url,同时每小时创建100个短url。
缓存
我们的系统可以从缓存最近的活动用户中获得巨大的好处。应用程序服务器可以在访问后端服务器之前快速检查缓存是否具有所需的记录。通过只更新缓存中的所有计数器和时间戳,我们的速率限制器可以从写回缓存中显著获益。对永久存储器的写操作可以在固定的时间间隔内完成。通过这种方式,我们可以确保速率限制器向用户请求添加的延迟最小。读取总是可以先到达缓存;这将是非常有用的,一旦用户已经达到他们的最大限制和速率限制器将只读取数据没有任何更新。
对于我们的系统来说,LRU是一种合理的缓存清除策略。
限制IP和user
让我们来讨论一下使用这些方案的利弊:
IP: 基于IP的节流最大的问题是当多个用户共享一个公共IP时,就像在网吧或使用同一网关的智能手机用户一样。一个坏用户可能会导致其他用户的节流。另一个问题可能出现在缓存基于ip的限制,因为有大量的IPv6地址可供黑客从甚至一台计算机,这是微不足道的,使服务器运行的内存跟踪IPv6地址!
用户:在用户身份验证之后,可以对api进行速率限制。通过身份验证后,将向用户提供一个令牌,用户将随每个请求传递该令牌。这将确保我们将对具有有效身份验证令牌的特定API进行评级限制。但是,如果我们必须对登录API本身进行评级限制呢?这种速率限制的缺点是,黑客可以通过输入错误的凭据来对用户执行拒绝服务攻击;之后,实际用户将无法登录。
附录
啥是限流器
系统过载时,为了服务仍然能正常响应,需要限制(throttle)一些请求;
概括地说,限流器的功能是限制实体(用户/机器/ip等)在T时间内可以处理的事件数量;
举几个例子:
- 用户每秒只能发一个请求
- 用户每天只能认证失败三次
- 一个ip每天只能创建20个用户
为啥需要限流器
从三个角度谈限流器的价值:
- 技术价值:提升服务稳定性,消除尖刺,防DOS等;
- 安全价值:防止账户被盗取等;
- 营销价值:可以提高收入。通过限制用户行为可以引导用户升级付费套餐;
工程思考
- 需要一个中控服务,维护着
- 实时性如何保证?影响到正常服务的latency;那就不要每次都上报,提前给机器1分配几个quota,每个机器有个小池子;
限流的实现方式
-
计数器
-
队列算法
2.1 朴素队列算法:丢弃后面的所有请求;
2.2 带权重的优先队列算法:高优先级队列权重较高 -
漏斗算法
优点:
缺点: