scrapy-redis案例(一)爬取中国红娘相亲网站
前言:本案例将分为三篇。
第一篇,使用scrapy框架来实现爬取中国红娘相亲网站。
第二篇,使用scrapy-redis 简单的方式爬取中国红娘相亲网站。(使用redis存储数据,请求具有持续性,但不具备分布式)
第三篇,使用scrapy-redis 分布式的方法爬取中国红娘相亲网站。
(1)准备工作
爬取网站地址:
http://www.hongniang.com/index/search?sort=0&wh=0&sex=2&starage=0&province=0&city=0&marriage=0&edu=0&income=0&height=0&pro=0&house=0&child=0&xz=0&sx=0&mz=0&hometownprovince=0
网页内容如下:我们想爬取所有相亲的 女用户。(男士的照片是在不是很好看,就爬女士的吧)
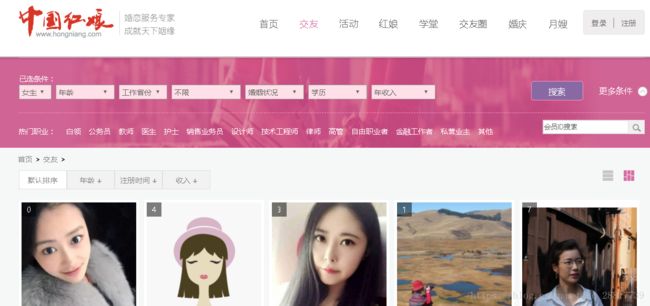
由于将要使用scrapy 中的 crawlSpider。需要使用正则匹配页面中的网址。
我们关注的网址有两个:分页的网址 和 用户的个人信息页面的网址

用户个人主页的网址:
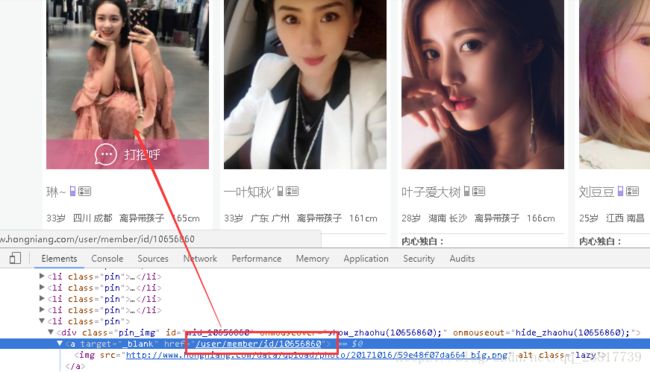
(2)使用scrapy shell 测试提取需要拦截的链接(分页和用户个人中心的链接)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据。
启动cmd命令行:
scrapy shell "爬取的网址"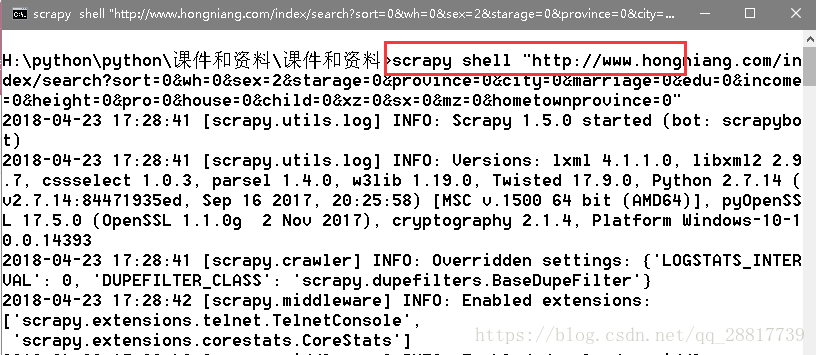
成功响应后,设置导入LinkExtractor:
from scrapy.linkextractors import LinkExtractor输入拦截的正则规则-分页网址:
page_lx = LinkExtractor(allow=('index/search\?.*&page=\d+'))
page_lx.extract_links(response)self_lx = LinkExtractor(allow=('user/member/id/\d+'))
self_lx.extract_links(response)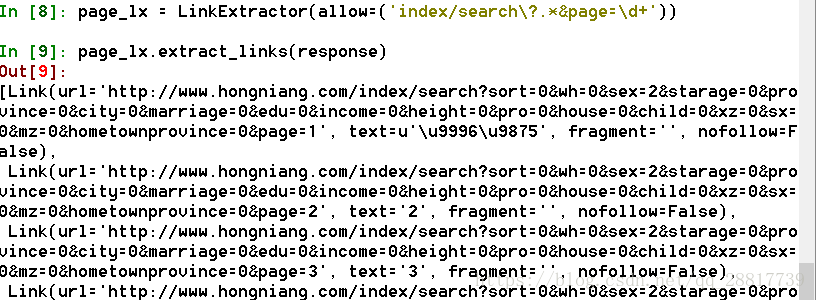
个人中心的网址同理:
self_lx = LinkExtractor(allow=('user/member/id/\d+'))
self_lx.extract_links(response)(3)使用xpath分析需要爬取的数据项
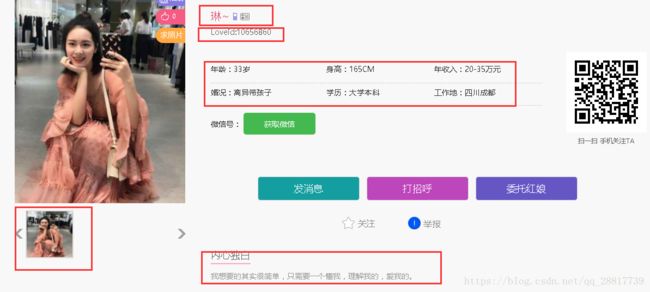
查看用户的个人信息,大致爬取的数据项有这几个:
建议使用 goole chome浏览器的xpath 插件,来尝试爬取规则,下面是我的爬取规则:
用户名称
//div[@class="info1"]/div[@class="name nickname"]/text()
用户id
//div[@class="info1"]/div[@class="loveid"]/text()
用户的照片
//div[@id="tFocus-btn"]/ul/li/img/@src
用户的详细资料。 去除最后一个 微信号:
例子:年龄:27岁
婚况:未婚
身高:165CM
学历:硕士
年收入:15-20万元
工作地:浙江杭州
微信号: 获取微信
//div[@class="info2"]/div/ul/li/text()
内心独白
//div[@class="info5"]/div[@class="text"]/text()
(4)开始编写scrapy 工程
到这一块我就不啰嗦了。直接展示命令和代码。
【1】创建工程:
scrapy startproject hongniang【2】修改settings.py 文件
USER_AGENT = "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
from scrapy import Item,Field
class HongniangItem(Item):
"""
中国红娘网站 女用户 简单字段
"""
#用户名称
nickname = Field()
#用户id
loveid = Field()
#用户的照片
photos = Field()
#用户年龄
age = Field()
#用户的身高
height = Field()
#用户是否已婚
ismarried = Field()
#用户年收入
yearincome = Field()
#用户的学历
education = Field()
#用户的地址
workaddress= Field()
#用户的内心独白
soliloquy = Field()
#用户的性别
gender = Field()
【4】创建crawlspider 文件
scrapy genspider -t crawl hongniangspider hongniang.com编写该文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from hongniang.items import HongniangItem
class HongniangspiderSpider(CrawlSpider):
name = 'hongniangSpider'
allowed_domains = ['hongniang.com']
start_urls = ['http://www.hongniang.com/index/search?sort=0&wh=0&sex=2&starage=0&province=0&city=0&marriage=0&edu=0&income=0&height=0&pro=0&house=0&child=0&xz=0&sx=0&mz=0&hometownprovince=0']
#中国红娘index页面的分页
page_lx = LinkExtractor(allow=('index/search\?.*&page=\d+'))
#个人详细的信息
self_lx = LinkExtractor(allow=('user/member/id/\d+'))
#规则
rules = (
Rule(page_lx,follow=True),
Rule(self_lx,callback='parse_item',follow=False)
)
def parse_item(self, response):
item = HongniangItem()
# 用户名称
item['nickname'] = self.get_nickname(response)
# 用户id
item['loveid'] = self.get_loveid(response)
# 用户的照片
item['photos'] = self.get_photos(response)
# 用户年龄
item['age'] = self.get_age(response)
# 用户的身高
item['height'] = self.get_height(response)
# 用户是否已婚
item['ismarried'] = self.get_ismarried(response)
# # 用户年收入
item['yearincome'] = self.get_yearincome(response)
# # 用户的学历
item['education'] = self.get_education(response)
# # 用户的地址
item['workaddress'] = self.get_workaddress(response)
# 用户的内心独白
item['soliloquy'] = self.get_soliloquy(response)
# 用户的性别
item['gender'] = self.get_gender(response)
print item
yield item
def get_nickname(self,response):
nickname = response.xpath('//div[@class="info1"]/div[@class="name nickname"]/text()').extract()[0]
if len(nickname)>0:
nickname = nickname.strip()
else:
nickname = "NULL"
return nickname
def get_loveid(self, response):
loveid = response.xpath('//div[@class="info1"]/div[@class="loveid"]/text()').extract()[0]
if len(loveid) > 0:
loveid = loveid.strip()
else:
loveid = "NULL"
return loveid
def get_photos(self, response):
photos = response.xpath('//div[@id="tFocus-btn"]/ul/li/img/@src').extract()
if len(photos) > 0:
pass
else:
photos = "NULL"
return photos
def get_age(self, response):
age = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[0]
if len(age) > 0:
age = age.strip()
else:
age = "NULL"
return age
def get_height(self, response):
height = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[2]
if len(height) > 0:
height = height.strip()
else:
height = "NULL"
return height
def get_ismarried(self, response):
ismarried = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[1]
if len(ismarried) > 0:
ismarried = ismarried.strip()
else:
ismarried = "NULL"
return ismarried
def get_yearincome(self, response):
yearincome = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[4]
if len(yearincome) > 0:
yearincome = yearincome.strip()
else:
yearincome = "NULL"
return yearincome
def get_education(self, response):
education = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[3]
if len(education) > 0:
education = education.strip()
else:
education = "NULL"
return education
def get_workaddress(self, response):
workaddress = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[5]
if len(workaddress) > 0:
workaddress = workaddress.strip()
else:
workaddress = "NULL"
return workaddress
def get_soliloquy(self, response):
soliloquy = response.xpath('//div[@class="info5"]/div[@class="text"]/text()').extract()[0]
if len(soliloquy) > 0:
soliloquy = soliloquy.strip()
else:
soliloquy = "NULL"
return soliloquy
def get_gender(self, response):
return "女"这里说明一些内容:
比如用户的照片可能有多张,直接存放成了集合:
response.xpath('//div[@id="tFocus-btn"]/ul/li/img/@src').extract()取出的是全部
取用户的详细资料,比如身高,体重等信息,取出来是一个集合,就按集合的下标取。
education = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[3]到这里,基本的代码编写就没有了,可以进行测试了。
(5)测试运行scrapy工程
scrapy crawl hongniangSpider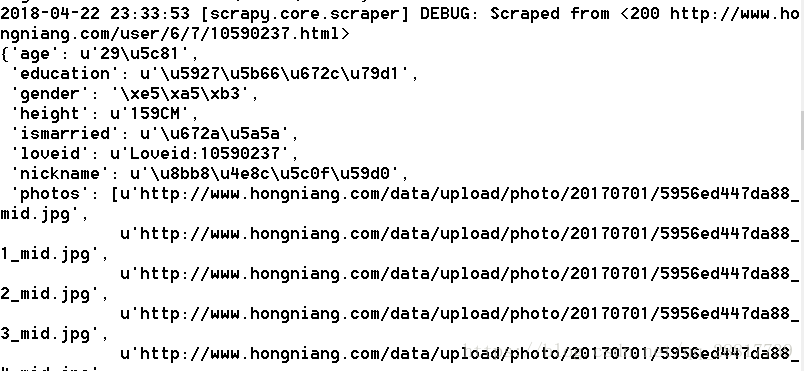
看到数据基本都提取出来了。
(6)总结
本工程只是常见的crawlspider,并没有使用到scrapy-redis,但是基础的爬虫都已经实现了。下一篇我们将该项目改为 scrapy-redis 的工程。
源码参考:https://github.com/gengzi/hongniang