Linux内核0.11——内核体系结构
Linux内核体系结构
linux内核主要由五部分组成:进程调度模块、内存管理模块、文件系统模块、进程间通信模块、网络接口模块。

如上图包括了各个部分的依赖关系,也大概表明了其在内核目录中的分布,其中进程调度模块是比较重要的一部分,所有模块都和它存在着依赖关系,相当于一个计算机资源的总管家。
内存管理和使用
这一部分不太好理解,建议多看几遍书,这里说一些我对书上的理解。
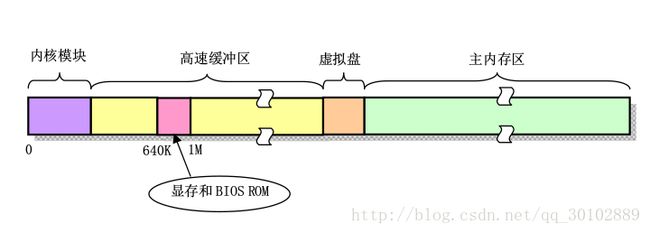
从上面这个物理内存分布中不难看出,并不是所有物理内存都是可用的(对于普通用户和上层应用开发来说),这就是为什么我们买电脑的时候人家说是4G的运行内存,而实际上开机之后你能用的总是那么多,远远不足4G。
所以说计算机的物理内存是远远不够用的,于是就产生了几种内存管理机制:分段系统、分页系统。分页是可选的,由系统编程人员决定,linux系统则是同时采用了这两种机制。
内存地址空间概念
想要搞懂linux内存管理,首先要弄清楚几个概念,不然那些什么虚拟地址、逻辑地址会把你搞得头昏。
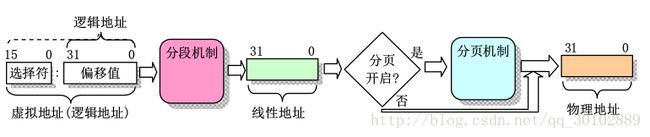
- 虚拟地址:由段选择符和段内偏移地址组成,因为这两部分并没有直接指向物理内存,需要经过分段变换机制(具体后面会说)才对应到物理内存,所以叫虚拟地址。虚拟地址空间包括GDT全局地址空间和LDT局部地址空间,选择符占13个bit,还有1bit是区分GDT or LDT,所以一共有2的14次方16384个选择符,若每个段取最大4G寻址空间,则整个虚拟地址空间有4 x 16384 = 64G。
- 逻辑地址:一般是指程序代码段限长内的偏移地址,一般程序员只需知道逻辑地址,因为分段分页机制对于他们是透明的,由系统编程人员管理,所以一些资料上对虚拟地址和逻辑地址不区分。
- 线性地址:虚拟到物理地址之间变换的中间层,也就是逻辑地址加上段选择符就是线性地址,如果不经分页机制,就直接得到的线性地址就是物理地址。
在linux0.11内核中,为每个进程分配了64M的虚拟内存空间,因此程序逻辑地址是0x0000000-0x4000000
好,那为什么要搞这些乱七八糟的又分段又分页的机制呢,整个物理内存就那么多,还要被系统占用一部分,windows用户还会说经常有流氓软件在后台运行占用内存和网络流量时不时出现内存占用率达到90以上的情况。
可是为什么我们还能在资源这么紧缺的情况下一边打撸一边看电影呢,答案就是虚拟内存系统。举个例子,你从北京到上海不需要很长的铁轨就能顺利完成任务,比如我们可以将后面的铁轨铺到前面,只要你够快够准。学过操作系统的应该会更了解虚拟内存机制(其实就是在进程暂时不用内存的时候给其他进程用,用一会再还回来嘛,或者再找别的进程借。),这个虚拟内存机制充分利用了CPU的地址总线,就拿上面的段来说,一个段最大4G空间,所以总的虚拟内存空间会比实际物理地址空间要大很多。
当然了真正的实现没这么简单,只是一个比喻。
分段机制
- 实时模式下寻址一个内存地址用一个段值加上一个段内偏移,段值存放在段寄存器(如ds),段长固定为64KB,偏移值存放在任一个可用于寻址的寄存器(如si),通过这两个寄存器的值就可以计算处实际地址
保护模式下段寄存器存放的不再是段基址,而是一个段描述符表中某一描述符项在表中的索引值,该描述符项中包含段基址、段长(可变,定义最大长度4G)、段的访问特权级别等。
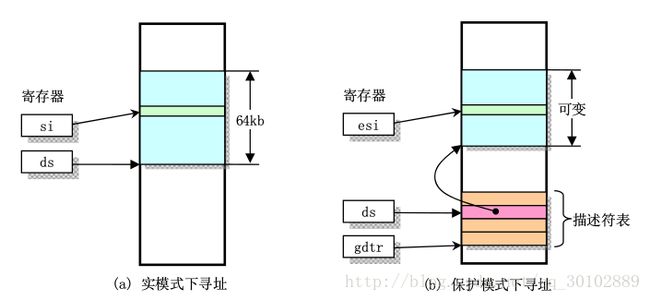
保存描述符项的描述符表有三种类型:
- GDT全局描述符表
- IDT 中断描述符表
- LDT局部描述符表
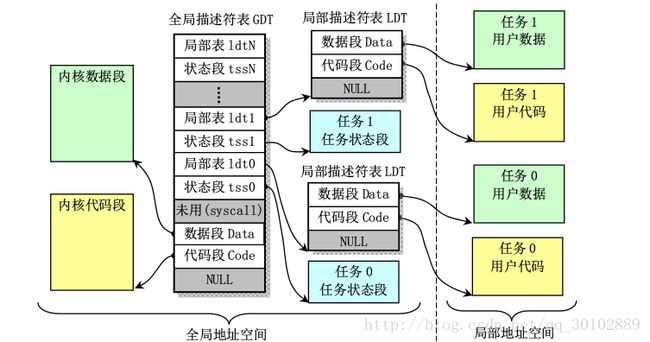
GDT和LDT构成了整个虚拟地址空间,为了能够寻址这三个表,在gdtr、idtr、ldtr三个寄存器中分别存放了表基址和限长。
分页机制
上面说过线性地址如果不经过分页转换,那得到的就是物理地址,下面这张图告诉我们如果采用分页机制,线性地址是怎么转换的:
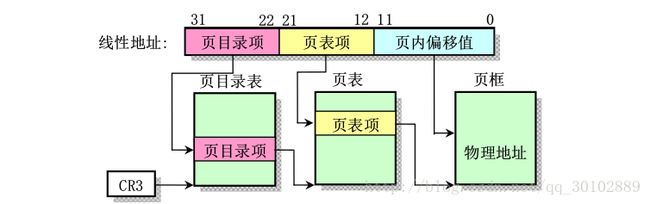
CR3保存页目录表基址在物理内存中的基址
内存分页管理机制主要原理就是,CPU将整个线性内存地址分为4096个字节为一页的内存页面,其实现机制从上图可以看出和分段机制类似,但没那么完善。在80x86体系结构中如果采用分页机制,需要将CR0的高位也就是bit31置位。
在80386中采用了分页管理,每个页目录表项或页表项格式基本相同都占4个字节,每个页目录表或页表必须只能包含1024个页表项,因此一个页目录表项或页表项占用4 x 1024个字节,也就是一个页面。
换句话说,一个页表项可以映射一个页面(也就是4096个字节=4KB),一个页表呢包含1024个表项,一个页目录表项包含1024个表项,就是说一个页目录表可以映射1024x1024x4KB=4GB的线性地址,也就是整个线性地址就可以用一个页目录表项映射了,神奇吧。
由于linux0.11中内核和所有任务都共用一个页目录表,所以所有的映射函数都是一样的,为了防止不互相干扰,二者必须从虚拟地址映射到线性地址的不同位置。
在0.11中每个进程最大可用虚拟地址空间为64MB,全局描述符表有256个表项,2项空闲2项系统使用,每个进程使用2项,也就是此时系统最多容纳(256-4)/2=126个任务,虚拟地址范围126x64MB=8GB。但0.11中人工定义的最大任务数是64个,所以全部线性地址空间为64x64MB=4GB。
篇幅限制就先把分段分页的机制的理解写在这里,后面还有一些内存管理的知识需要大家自己多看一下,这些基本的机制搞懂了后面的应用扩展就没什么问题了。
中断机制
当设备向处理器发出服务请求时(中断请求IRQ),处理器在结束当前指令后会立即应答并转向设备的相关服务程序(中断服务程序ISR),这个服务程序执行完成后会立即返回之前被中断的服务,这个方式称为中断方法。
对于linux内核来说,中断信号分为:软件中断(异常)、硬件中断,每个中断由0-255之间的数字标识,对于int0-int31(0x00-0x1f)是由Intel公司固定设定或保留使用的,属于软中断,Intel称为异常(通常还分为故障fault和陷阱traps)。剩下的int32-int255(0x20-0xff)可由用户自己设定。
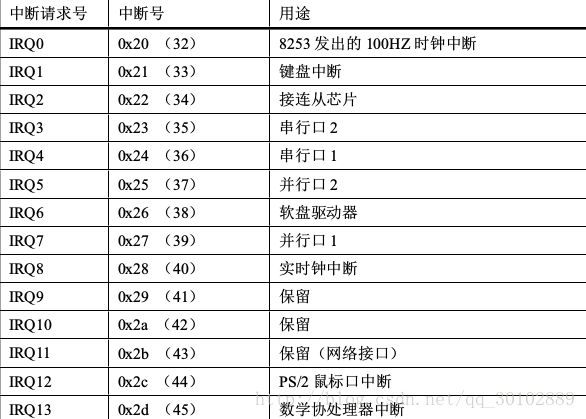
在BIOS执行初始化操作时会通过硬件设置中断向量(4字节)来提供中断服务,而后在系统引导加载内核时还会通过设置中断向量表来重新设置中断向量。对于linux会在加载内核之前的setup.s中重新初始化硬件,在head.s中设置一张中断向量表(中断描述符表IDT),完全抛弃了BIOS的中断设置。
如果中断的概念还不知道的话,一定要好好了解一下,很重要
Linux的系统调用
系统调用接口
系统调用(syscalls)是内核与上层应用通信的唯一接口。从中断机制中可知,用户程序通过调用中断int 0x80,并在eax寄存器中指定系统调用功能号,就可以使用内核和系统硬件资源了。不过一般应用程序都是通过C库函数间接使用内核系统调用。比如:
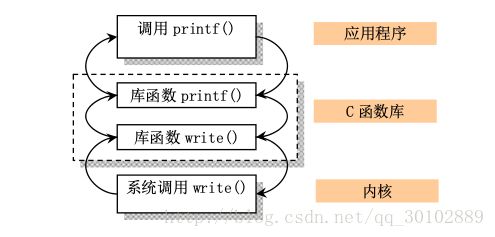
而这些系统调用功能号定义在include/unistd.h中,并且与include/linux/sys.h中定义的系统调用指针数组表sys中的sys_call_table[]的索引值一一对应。
下面列出部分源码,可以看出所以内核系统调用处理函数都是以”sys_”开头的。
/*
* /include/unistd.h
*/
#define __NR_setup 0 /* used only by init, to get system going */
#define __NR_exit 1
#define __NR_fork 2
#define __NR_read 3
#define __NR_write 4
#define __NR_open 5
#define __NR_close 6
#define __NR_waitpid 7
#define __NR_creat 8
#define __NR_link 9
#define __NR_unlink 10
#define __NR_execve 11
#define __NR_chdir 12
#define __NR_time 13
#define __NR_mknod 14
#define __NR_chmod 15
#define __NR_chown 16
#define __NR_break 17
#define __NR_stat 18
#define __NR_lseek 19
#define __NR_getpid 20
...
...
/*
* /include/linux/sys.h
*/
extern int sys_setup();
extern int sys_exit();
extern int sys_fork();
extern int sys_read();
extern int sys_write();
extern int sys_open();
extern int sys_close();
extern int sys_waitpid();
extern int sys_creat();
extern int sys_link();
extern int sys_unlink();
extern int sys_execve();
extern int sys_chdir();
extern int sys_time();
extern int sys_mknod();
extern int sys_chmod();
extern int sys_chown();
extern int sys_break();
extern int sys_stat();
extern int sys_lseek();
...
...
fn_ptr sys_call_table[] = { sys_setup, sys_exit, sys_fork, sys_read,
sys_write, sys_open, sys_close, sys_waitpid, sys_creat, sys_link,
sys_unlink, sys_execve, sys_chdir, sys_time, sys_mknod, sys_chmod,
sys_chown, sys_break, sys_stat, sys_lseek, sys_getpid, sys_mount,
sys_umount, sys_setuid, sys_getuid, sys_stime, sys_ptrace, sys_alarm,
sys_fstat, sys_pause, sys_utime, sys_stty, sys_gtty, sys_access,
sys_nice, sys_ftime, sys_sync, sys_kill, sys_rename, sys_mkdir,
sys_rmdir, sys_dup, sys_pipe, sys_times, sys_prof, sys_brk, sys_setgid,
sys_getgid, sys_signal, sys_geteuid, sys_getegid, sys_acct, sys_phys,
sys_lock, sys_ioctl, sys_fcntl, sys_mpx, sys_setpgid, sys_ulimit,
sys_uname, sys_umask, sys_chroot, sys_ustat, sys_dup2, sys_getppid,
sys_getpgrp, sys_setsid, sys_sigaction, sys_sgetmask, sys_ssetmask,
sys_setreuid,sys_setregid };
系统调用处理过程
当应用程序通过库函数向内核发送一个中断请求int 0x80时,就开始执行一个系统调用,系统调用号在寄存器eax中,参数在ebx、ecx、edx中(最多三个),处理中断过程的程序是kernel/system_call.s中的system_call
_system_call:
cmpl $nr_system_calls-1,%eax
ja bad_sys_call
push %ds
push %es
push %fs
pushl %edx
pushl %ecx # push %ebx,%ecx,%edx as parameters
pushl %ebx # to the system call
movl $0x10,%edx # set up ds,es to kernel space
mov %dx,%ds
mov %dx,%es
movl $0x17,%edx # fs points to local data space
mov %dx,%fs
#每项4字节,因此调用地址位_sys_call_table+%eax*4得到被调用处理函数的地址
call _sys_call_table(,%eax,4)
pushl %eax
movl _current,%eax
cmpl $0,state(%eax) # state
jne reschedule
cmpl $0,counter(%eax) # counter
je reschedule
内核在unistd.h中定义了宏函数_syscalln(),n代表参数个数,每个系统调用的宏都有2+n*2个参数,第一个是返回类型,第二个是系统调用名,后面即是参数。
#define _syscall3(type,name,atype,a,btype,b,ctype,c) \
type name(atype a,btype b,ctype c) \
{ \
long __res; \
__asm__ volatile ("int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c))); \
if (__res>=0) \
return (type) __res; \
errno=-__res; \
return -1; \
}
例如我们在程序中可以直接调用_syscall3(int, read, int, fd, char*, buf, int, n)而不通过库函数做中介,展开就是:
int read(int fd, char *buf, int n)
{
long __res;
__asm__volatile(
"int $0x80"
: "a" (__res)
: "0" (__NR_read), "b"((long)(fd)), "c" ((long)(buf)), "d" ((long)(n));
if (__res>0)
return int __res;
errno -__res;
return -1;
}嵌入汇编语句以功能号__NR_read(3)执行linux系统中断调用0x80,该中断调用在eax(__res)寄存器中返回实际读取字节数,若出错将出错号存入全局变量errno中并返回-1。
Linux进程控制
进程(process)是一个执行中的程序实例。
任务数据结构
内核中的进程称为任务task,用户空间的程序称为进程。
内核一直在维护一个进程表对进程进行管理,linux中是一个task_struct任务结构指针(include/linux/sched.h),一般称为进程控制块PCB或进程描述符PD。主要保存进程当前运行的状态信息、信号、进程号、父进程号、运行时间、正在使用的文件、本任务的局部描述符、任务状态段信息(之前提到过的TSS)。
struct task_struct {
/* these are hardcoded - don't touch */
long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
long signal;
struct sigaction sigaction[32];
long blocked; /* bitmap of masked signals */
/* various fields */
int exit_code;
unsigned long start_code,end_code,end_data,brk,start_stack;
long pid,father,pgrp,session,leader;
unsigned short uid,euid,suid;
unsigned short gid,egid,sgid;
long alarm;
long utime,stime,cutime,cstime,start_time;
unsigned short used_math;
/* file system info */
int tty; /* -1 if no tty, so it must be signed */
unsigned short umask;
struct m_inode * pwd;
struct m_inode * root;
struct m_inode * executable;
unsigned long close_on_exec;
struct file * filp[NR_OPEN];
/* ldt for this task 0 - zero 1 - cs 2 - ds&ss */
struct desc_struct ldt[3];
/* tss for this task */
struct tss_struct tss;
};当一个进程正在执行时,CPU中所有寄存器值、进程状态、堆栈中内容称为进程上下文。当内核需要切换进程时就需要保存当前进程的上下文以便恢复,linux中进程上下文就保存在这个任务数据结构中。
进程运行状态
进程的生存期内的进程状态如下,进程状态保存在任务结构中的state字段中
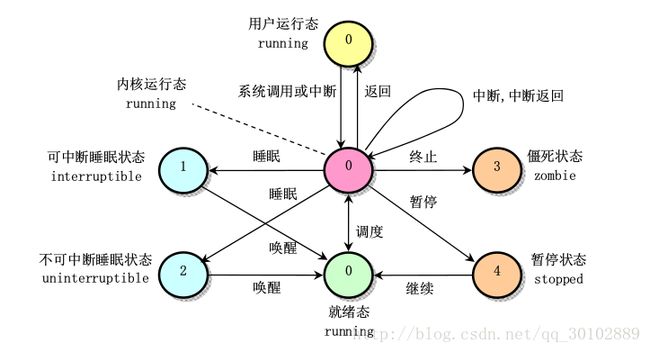
僵死状态:当进程已经停止运行,但其父进程还没调用wait()询问其状态时,该进程处于僵死状态,为了父进程还能获取其信息,此时子进程还需保留着任务数据结构
进程初始化
Linux系统中堆栈的使用
- 系统引导初始化时临时使用的堆栈;
- 进入保护模式后提供内核程序初始化使用的堆栈;
- 每个任务通过系统调用执行内核程序时使用的堆栈,称为任务的内核态堆栈;
- 任务在用户态执行的堆栈,位于任务逻辑地址空间末端。
初始化阶段
- 开机初始化(bootsect.s, setup.s)
bootsect代码被ROM BIOS引导加载到物理内存0x7c00时并没有设置堆栈段,直到boostsect被移动到0x9000:0才将堆栈寄存器SS设置为0x9000,堆栈指针寄存器为0xff00,所有堆栈顶在0x9000:0xff00
entry start
start:
mov ax,#BOOTSEG
mov ds,ax
mov ax,#INITSEG
mov es,ax
mov cx,#256
sub si,si
sub di,di
rep
movw
jmpi go,INITSEG
go: mov ax,cs
mov ds,ax
mov es,ax
! put stack at 0x9ff00.
mov ss,ax
mov sp,#0xFF00 ! arbitrary value >>512
! load the setup-sectors directly after the bootblock.
! Note that 'es' is already set up.
- 进入保护模式时(head.s)
自此进入保护模式,此时堆栈段设置为内核数据段0x10,esp指向user_stack数组顶端,保留一页内存(4K)作为堆栈使用
——-未完
linux-0.11文件系统
内核的运行肯定离不开文件系统的支持,对于前面介绍的linux0.11就包含了两个映像文件:bootimage、rootimage。一个启动引导文件包含引导扇区代码、操作系统加载程序和内核执行代码,另一个则是根文件系统的映像,这两个合起来就是一个系统盘了。
是linux文件系统一般是extn(n=2,3,4),其中包括操作系统的一些规定目录、配置文件、设备驱动、等等,具体就是根目录下的那些子目录,可以看一下linux根目录主要结构。
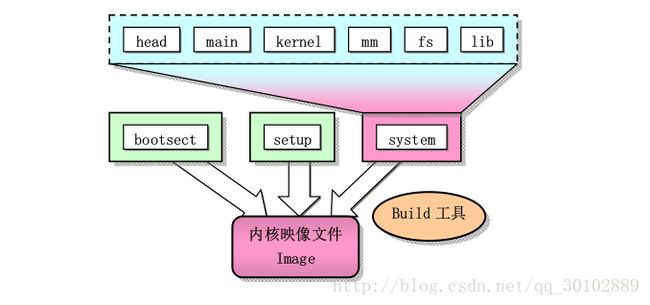
linux-0.11内核目录结构

内核系统与应用程序的关系
大家应该都见过这几个词:API、系统调用、库函数
首先API即所谓的库函数,而系统调用是内核与外界接口的最高层,在内核中每个系统调用都由一个宏来标识(前面提到过),一个库函数可能与一个或多个系统调用(比如sys_open)对应来完成相应的操作(比如fopen),虽然系统调用会比库函数效率高,但是库函数具有移植性,而且还有较好的容错能力。
比如说POSIX标准,对于它来说无论操作系统提供的系统调用多不同,只要遵循这个API标准,他就是可移植的。
Makefile
详细注释就不在这里叙述了。