一、tf.data.Dataset.from_tensor_slices,它有三种用法,可以传入tensor、元组以及字典。下面就举几个例子:
- 直接传入tensor,有一点需要注意的是,它是按照传入的tensor的第0维进行划分以产生数据集

- 传入元组
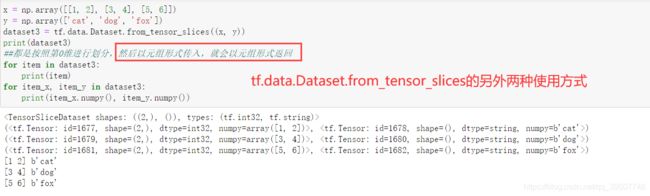
- 传入字典

二、使用from_tensor_slices生成的dataset的一些属性方法,apply、as_numpy_iterator、
- repeat和batch,这里的dataset就是上面的dataset

- interleave,这里的dataset就是上面的dataset


- apply
apply(
transformation_func
)
dataset = tf.data.Dataset.range(100)
def dataset_fn(ds):
return ds.filter(lambda x: x < 5)
dataset = dataset.apply(dataset_fn)
list(dataset.as_numpy_iterator())
输出:[0,1,2,3,4]
dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3])
for element in dataset:
print(element)
输出:
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=int32)
dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3])
for element in dataset.as_numpy_iterator():
print(element)
输出:
1
2
3
dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3])
print(list(dataset.as_numpy_iterator()))
输出:[1,2,3]
dataset = tf.data.Dataset.from_tensor_slices({'a': ([1, 2], [3, 4]),
'b': [5, 6]})
list(dataset.as_numpy_iterator()) == [{'a': (1, 3), 'b': 5},
{'a': (2, 4), 'b': 6}]
输出:True
dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3])
dataset = dataset.filter(lambda x: x < 3)
list(dataset.as_numpy_iterator())
输出:[1,2]
def filter_fn(x):
return tf.math.equal(x, 1)
dataset = dataset.filter(filter_fn)
list(dataset.as_numpy_iterator())
输出:[1]
'''
buffer_size:表示dataset中有多少个元素
reshuffle_each_iteration:表示dataset使用repeat时,后面的元素要不要也打乱
'''
shuffle(
buffer_size, seed=None, reshuffle_each_iteration=None
)
dataset = tf.data.Dataset.range(3)
dataset = dataset.shuffle(3, reshuffle_each_iteration=True)
dataset = dataset.repeat(2)
输出:[1,0,2,1,2,0]
dataset = tf.data.Dataset.range(3)
dataset = dataset.shuffle(3, reshuffle_each_iteration=False)
dataset = dataset.repeat(2)
输出:[1,0,2,1,0,2]
'''
作用是跳过dataset的前count个值,只取后面的值
'''
skip(
count
)
dataset = tf.data.Dataset.range(10)
dataset = dataset.skip(7)
list(dataset.as_numpy_iterator())
输出:[7,8,9]