linux堆笔记(一)——堆相关数据结构
堆相关的数据结构
看了ctfwiki上堆相关的部分内容所写笔记。
堆的基本操作
malloc(size_t n)
- size_t在32位系统下是4字节,在64位系统上是8字节,size_t是无符号的,所以如果传入一个负数会得到一个很大的数字
- 当malloc(0)的时候,malloc返回一个最小快,这个块的大小在
- 32位系统上是16bytes
- 64位系统上是24或32bytes
free(void* p)
- 当p为空指针时,free不执行任何操作
- 当p已经被释放后再次被释放则会出现问题(double free)。
内核中各模块的空间分布图
32系统中的空间分布图如下:
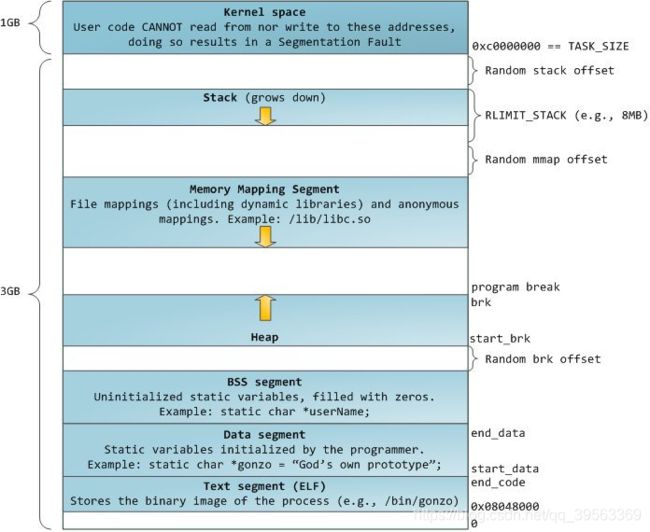
32位解释一下:
0x00000000-0xc0000000是供各个进程使用,称为用户空间,而0xc0000000-0xffffffff是kernel space也就是内核空间,用户无法访问。因为每个进程可以通过系统调用进入内核,因此,Linux内核由系统内的所有进程共享。
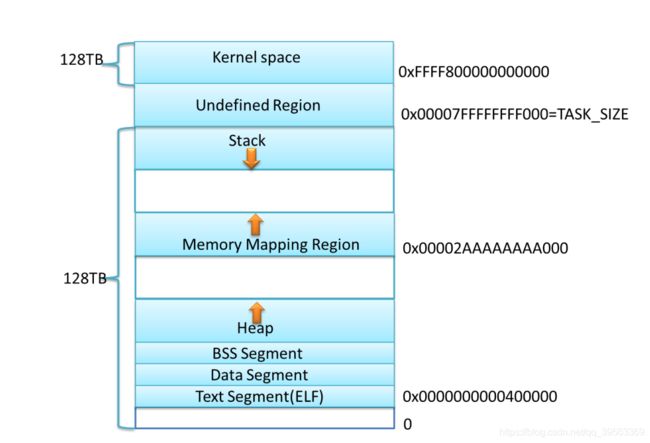
64位如下
堆的数据结构
chunk
由malloc函数申请的内存为chunk,chunk的结构都是相同的,只不过根据自己是否被释放,它们的表现形式有所不同
/*
This struct declaration is misleading (but accurate and necessary).
It declares a "view" into memory allowing access to necessary
fields at known offsets from a given base. See explanation below.
*/
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
对chunk结构的解释
-
struct malloc_chunk*是定义指针,定义的变量大小在32位系统占4个字节,在64位占8个字节。 -
INTERNAL_SIZE_T:被定义为size_t,在32位系统上是32位无符号整数(4bytes),在64位系统上是64位无符号整数(8bytes)
-
prev_size:前一个chunk空闲则记录了前一个chunk的大小,如果前一个chunk不空闲,那么这里存储的就是前一个chunk最后的数据.
这里的前一个chunk指较低地址的的chunk
prev_size如何得到前一个chunk的大小呢?
用当前chunk的地址指针减去前一个地址指针值就得到了。
- size:当前chunk的大小,chunk的大小必须是2*SIZE_SZ的整数倍,如果不满足会被强制转换为2*SIZE_SZ的整数倍。
- SIZE_SZ的定义:
#define SIZE_SZ (sizeof (INTERNAL_SIZE_T))
也就是说,SIZE_SZ在32位系统下是4个字节大小,在64位系统下是8个字节大小- 接上面,由于每个chunk的大小必须是2*SIZE_SZ的整数倍,所以在32位系统下最小的chunk是16个字节大小,64位系统下最小的chunk是24个字节或32个字节大小。8个字节=>8的整数倍是的用二进制表示是 1000*n,所以低三位始终为0,对堆块大小没影响。于是设计人员选择拿低三位当标志位使用,从高到低分别表示:
- NON_MAIN_ARENA:记录当前chunk是否不属于主线程,1代表不属于,0代表属于
- IS_MAPPED:记录当前chunk是否由mmap分配
- PREV_INUSE:记录前一个chunk块是否被分配,1代表被分配,0代表没有被分配。当一个 chunk 的 size 的 P 位为 0 时,说明前一个chunk空闲,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲 chunk 之间的合并。
堆中第一个被分配的chunk的size字段的PREV_INUSE都会被置为1,以便于禁止访问前面的非法内存
-
fd、bk
- chunk被分配后从fd开始是用户的数据
- chunk未被分配时
- fd指向前一个空闲chunk(指链表中的前一个,物理地址可能不相邻)
- bk指向后一个空闲chunk
-
fd_nextsize, bk_nextsize
只有在chunk空闲时才是用,只用于large chunk- fd_nextsize:指向前一个与当前chunk大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适 chunk 时挨个遍历。
chunk结构总结
- 在分配状态时,只有前2个字段和user data内容
- 在空闲时chunk放到空闲链表中,才有了fd、bk等内容
- fd_nextsize和bk_nextsize只有在large chunk时才需要考虑
与chunk相关的宏定义
chunk 与 mem 指针头部的转换
chunk指的是chunk的首地址,mem指的是用户数据的首地址,中间差了一个chunk header(也就是PREV_SIZE和SIZE,大小是2*SIZE_SZ)
/* conversion from malloc headers to user pointers, and back */
#define chunk2mem(p) ((void *) ((char *) (p) + 2 * SIZE_SZ))
#define mem2chunk(mem) ((mchunkptr)((char *) (mem) -2 * SIZE_SZ))
最小chunk的大小
/* The smallest possible chunk */
#define MIN_CHUNK_SIZE (offsetof(struct malloc_chunk, fd_nextsize))
这里求了chunk结构体开头到fd_nextsize的偏移,也就是说,最小chunk包含2个INTERNAL_SIZE_T和2个struct malloc_chunk*,一共4*SIZE_SZ,所以32位占16字节大小,64位占32字节大小,用代码测试一下
#include 32位运行结果
0x883b008
0x883b018
0x883b028
0x883b038
说明32位下最小的chunk大小是16字节
64位运行结果是
0x1c14010
0x1c14030
0x1c14050
0x1c14070
说明64位最小的chunk大小是0x20也就是32个字节
获取 chunk size
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
/* Get size, ignoring use bits */
#define chunksize(p) (chunksize_nomask(p) & ~(SIZE_BITS))
/* Like chunksize, but do not mask SIZE_BITS. */
#define chunksize_nomask(p) ((p)->mchunk_size)
也就是取结构体中的size然后与上0b000,把低三位清0
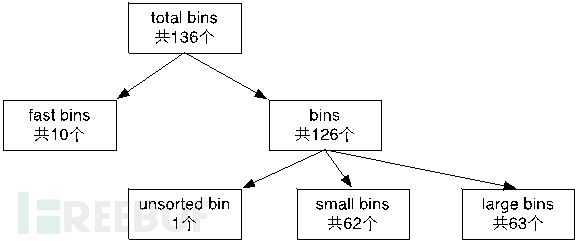
bin
ptmalloc把空闲的堆分成四种,分别是fast bins,small bins,large bins,unsorted bin
相似大小的 chunk 会用双向链表链接起来。也就是说,在每类 bin 的内部仍然会有多个互不相关的链表来保存不同大小的 chunk。
对于 small bins,large bins,unsorted bin 来说,ptmalloc 将它们维护在同一个数组中。这些 bin 对应的数据结构在 malloc_state 中,如下
#define NBINS 128
/* Normal bins packed as described above */
mchunkptr bins[ NBINS * 2 - 2 ];
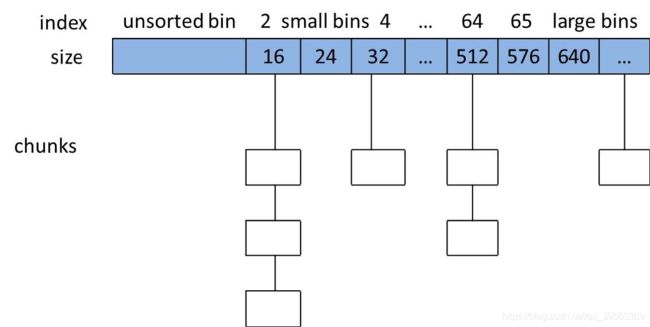
按顺序依次是:
- 索引为1处是unsorted bin,存储的chunk没有排序
- 索引从2到63的bin称为small bin,同一个 small bin 链表中的 chunk 的大小相同。两个相邻索引的 small bin 链表中的 chunk 大小相差的字节数为 2 个机器字长,即 32 位相差 8 字节,64 位相差 16 字节。
- small bins 后面的 bin 被称作 large bins,索引为64到126。large bins 中的每一个 bin 都包含一定范围内的 chunk,其中的 chunk 按 fd 指针的顺序从大到小排列。相同大小的 chunk 同样按照最近使用顺序排列。
- fastbins单独记录在一个fastbinsY数组中,个数为10,chunk size为16到80字节的chunk就叫做fast chunk
fastbins
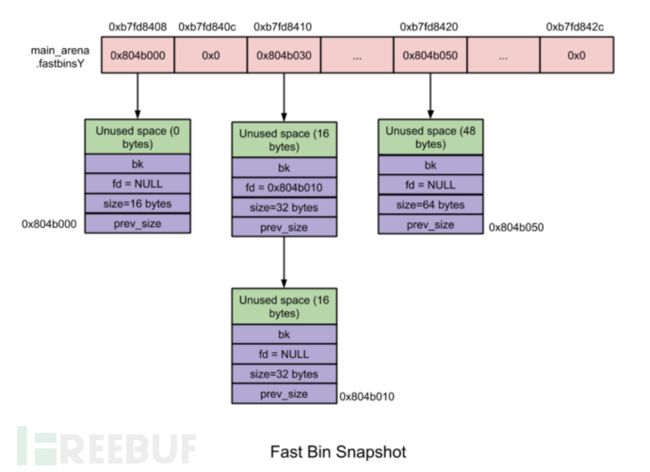
- 使用LIFO(后入先出)算法,添加操作(free内存)就是将新的fast chunk加入链表尾,删除操作(malloc内存)就是将链表尾部的fast chunk删除。
- chunk size:10个fast bin中所包含的fast chunk size是按照步进8字节排列的,即第一个fast bin中所有fast chunk size均为16字节,第二个fast bin中为24字节,依次类推。在进行malloc初始化的时候,最大的fast chunk size被设置为80字节(chunk unused size为64字节),因此默认情况下大小为16到80字节的chunk被分类到fast chunk
- 不会对free chunk进行合并操作。鉴于设计fast bin的初衷就是进行快速的小内存分配和释放,因此系统将属于fast bin的chunk的P(未使用标志位)总是设置为1,这样即使当fast bin中有某个chunk同一个free chunk相邻的时候,系统也不会进行自动合并操作,而是保留两者。虽然这样做可能会造成额外的碎片化问题,但瑕不掩瑜。
- malloc(fast chunk)操作:即用户通过malloc请求的大小属于fast chunk的大小范围(注意:用户请求size加上16字节就是实际内存chunk size)。在初始化的时候fast bin支持的最大内存大小以及所有fast bin链表都是空的,所以当最开始使用malloc申请内存的时候,即使申请的内存大小属于fast chunk的内存大小(即16到80字节),它也不会交由fast bin来处理,而是向下传递交由small bin来处理,如果small bin也为空的话就交给unsorted bin处理:
- free(fast chunk)操作:这个操作很简单,主要分为两步:先通过chunksize函数根据传入的地址指针获取该指针对应的chunk的大小;然后根据这个chunk大小获取该chunk所属的fast bin,然后再将此chunk添加到该fast bin的链尾即可。整个操作都是在_int_free函数中完成。
unsorted bin
当释放较小或较大的chunk的时候,如果系统没有将它们添加到对应的bins中,系统就将这些chunk添加到unsorted bin中。
- unsorted bin的个数: 1个。unsorted bin是一个由free chunks组成的循环双链表。
- Chunk size: 在unsorted bin中,对chunk的大小并没有限制,任何大小的chunk都可以归属到unsorted bin中。这就是前言说的特例了,不过特例并非仅仅这一个,后文会介绍。
small bin
- chunk size:从16到504字节(64位系统的话是从32字节到1008字节)
- free(small chunk):当释放small chunk的时候,先检查该chunk相邻的chunk是否为free,如果是的话就进行合并操作:将这些chunks合并成新的chunk,然后将它们从small bin中移除,最后将新的chunk添加到unsorted bin中
large bin
- 一是同一个large bin中每个chunk的大小可以不一样,但必须处于某个给定的范围(特例2) ;二是large chunk可以添加、删除在large bin的任何一个位置
- 在这63个large bins中,前32个large bin依次以64字节步长为间隔,即第一个large bin中chunk size为512~575字节,第二个large bin中chunk size为576 ~ 639字节。紧随其后的16个large bin依次以512字节步长为间隔;之后的8个bin以步长4096为间隔;再之后的4个bin以32768字节为间隔;之后的2个bin以262144字节为间隔;剩下的chunk就放在最后一个large bin中。如下表所示。
| 组 | 数量 | 公差 |
|---|---|---|
| 1 | 32 | 64B |
| 2 | 16 | 512B |
| 3 | 8 | 4096B |
| 4 | 4 | 32768B |
| 5 | 2 | 262144B |
| 6 | 1 | 不限制 |
- free和合并操作:类似于small bin。
- malloc操作:初始化完成之前的操作类似于small bin,这里主要讨论large bins初始化完成之后的操作。首先确定用户请求的大小属于哪一个large bin,然后判断该large bin中最大的chunk的size是否大于用户请求的size(只需要对比链表中front end的size即可)。如果大于,就从rear end开始遍历该large bin,找到第一个size相等或接近的chunk,分配给用户。如果该chunk大于用户请求的size的话,就将该chunk拆分为两个chunk:前者返回给用户,且size等同于用户请求的size;剩余的部分做为一个新的chunk添加到unsorted bin中。
4种bin的总结

Top Chunk
- 只有当其他的chunk都不合适的时候,才会用它
- 如果它非常大的话,释放后会返还给操作系统
- top chunk 就是处于当前堆的物理地址最高的chunk
- top chunk 的 prev_inuse 比特位始终为 1,否则其前面的 chunk 就会被合并到 top chunk 中
- 初始情况下,我们可以将 unsorted chunk 作为 top chunk
unlink
unlink用来从空闲链表管理器ptmalloc2中取出一个元素(chunk),在以下函数中会用到。
malloc
- 从恰好大小合适的large bin 中获取chunk
- 从比请求的chunk所在的bin大的bin中取chunk
注意fastbin和smallbin没有使用unlink,这里我的理解是unlink是从链表中间取使用的(如果不对希望师傅在评论区指点一下)?small bin和fast bin每个索引位置对应的链表上的chunk的大小是固定的,只需要定位到索引的位置然后从链表尾部取一个(因为这个索引上的一条链表上的元素一样大),而large bin同一个索引上的一排链表中的chunk在一个大小范围内浮动,并不完全相同,为了取一个跟所请求的size一模一样大小的chunk,可能需要从中间unlink一个chunk,所以用到了unlink函数。
free
- 后向合并,合并物理相邻低地址的空闲chunk
- 前向合并,合并物理相邻高地址空闲chunk(除了top chunk)
malloc_consolidate
- 后向合并,合并物理相邻低地址空闲 chunk。
- 前向合并,合并物理相邻高地址空闲 chunk(除了 top chunk)。
realloc
- 前向扩展,合并物理相邻高地址空闲 chunk(除了 top chunk)。
unlink的实现
unlink被实现为宏,把\去掉写成函数并代码格式化一下好看一点
/* Take a chunk off a bin list */
// unlink p
#define unlink(AV, P, BK, FD) {
// 由于 P 已经在双向链表中,所以有两个地方记录其大小,所以检查一下其大小是否一致。
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0))
malloc_printerr ("corrupted size vs. prev_size");
FD = P->fd;
BK = P->bk;
// 防止攻击者简单篡改空闲的 chunk 的 fd 与 bk 来实现任意写的效果。
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr (check_action, "corrupted double-linked list", P, AV);
else
{
FD->bk = BK;
BK->fd = FD;
// 下面主要考虑 P 对应的 nextsize 双向链表的修改
if (!in_smallbin_range (chunksize_nomask (P))
// 如果P->fd_nextsize为 NULL,表明 P 未插入到 nextsize 链表中。
// 那么其实也就没有必要对 nextsize 字段进行修改了。
// 这里没有去判断 bk_nextsize 字段,可能会出问题。
&& __builtin_expect (P->fd_nextsize != NULL, 0))
{
// 类似于小的 chunk 的检查思路
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0)
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0))
malloc_printerr (check_action,
"corrupted double-linked list (not small)",
P, AV);
// 这里说明 P 已经在 nextsize 链表中了。
// 如果 FD 没有在 nextsize 链表中
if (FD->fd_nextsize == NULL)
{
// 如果 nextsize 串起来的双链表只有 P 本身,那就直接拿走 P
// 令 FD 为 nextsize 串起来的
if (P->fd_nextsize == P)
FD->fd_nextsize = FD->bk_nextsize = FD;
else
{
// 否则我们需要将 FD 插入到 nextsize 形成的双链表中
FD->fd_nextsize = P->fd_nextsize;
FD->bk_nextsize = P->bk_nextsize;
P->fd_nextsize->bk_nextsize = FD;
P->bk_nextsize->fd_nextsize = FD;
}
}
else
{
// 如果在的话,直接拿走即可
P->fd_nextsize->bk_nextsize = P->bk_nextsize;
P->bk_nextsize->fd_nextsize = P->fd_nextsize;
}
}
}
}

可以看出, P 最后的 fd 和 bk 指针并没有发生变化,但是当我们去遍历整个双向链表时,已经遍历不到对应的链表了。这一点没有变化还是很有用处的,因为我们有时候可以使用这个方法来泄漏地址
- libc 地址
- P 位于双向链表头部,bk 泄漏
- P 位于双向链表尾部,fd 泄漏
- 双向链表只包含一个空闲 chunk 时,P 位于双向链表中,fd 和 bk 均可以泄漏
- 泄漏堆地址,双向链表包含多个空闲 chunk
- P 位于双向链表头部,fd 泄漏
- P 位于双向链表中,fd 和 bk 均可以泄漏
- P 位于双向链表尾部,bk 泄漏
参考文章
- ctfwiki
- Linux堆内存管理深入分析(上)
- Linux堆内存管理深入分析(下)