refinedet训练KITTI数据集(仅用于Car和Cyclist两种类别的检测)
参考:SSD: Single Shot MultiBox Detector 训练KITTI数据集(1) - Jesse_Mx的博客 - CSDN博客 https://blog.csdn.net/jesse_mx/article/details/65634482/
顺便说一下,我一直以为Cyclist是检测的自行车,后来检测的时候才发现原来检测的是骑自行车的人...
贴上create_list.sh以及create_data.sh中命令详解的链接:
基于caffe的SSD目标检测——训练集生成和lmdb文件的制作:https://blog.csdn.net/edogawachia/article/details/81669834
SSD中生成数据集索引的create_list.sh - qq_21368481的博客 - CSDN博客 https://blog.csdn.net/qq_21368481/article/details/82350331
(1)数据集的下载:The KITTI Vision Benchmark Suite http://www.cvlibs.net/datasets/kitti/index.php

点击之后登录邮箱 收到下载链接就可以下载啦!我的360安装浏览器老是下载失败,结果用极速浏览器下载好的(下载老是中断,继续下载就好了!360一旦中断就得重新下载,然后继续中断...)
必须注意一下,最好所有的过程都在一个系统要么windows或者linux系统下进行,否则在后面create_list的时候会产生格式问题。
这两个压缩包下载下来解压之后得到一个testing和training的文件夹
这是training种的内容,包含了训练图片和相应的.txt文件。
然后新建了一个KITTI文件为后面的数据转换做准备(需要将KITTI数据集转换成为VOC格式的数据集),目录如下
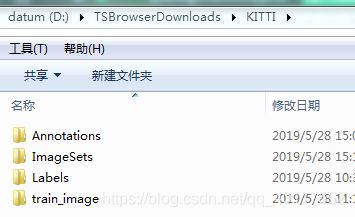
Annotations中存放转换后的.xml文件;ImageSets中新建了一个Main文件存放生成的训练验证等txt文件Labels和train_image是前面training中的内容。转换的主要目的就是为了得到Annotations和Main中的内容
转换成KITTI类别:(所有的代码都在参考链接中,只需要改一下路径就好)用到的工具是modify_annotations_txt.py
改路径

合并类别(将'Truck','Van','Tram'合并成为Car,忽略掉'Misc和'Pedestrian'(由于我只检测Car’,’Cyclist这两种类别物体所以其他的都忽略掉了)

转换之后每张图片都有相应的.txt但是如果没有‘Car’,’Cyclist’这两种类别物体的话,.txt就是空白文件
接下来是将txt标注信息转换成为xml格式(记得改路径):利用txt_to_xml.py

转换后的.xml和原本的VOC中的.xml有一点差别,这里需要留意一下,因为后面在检测refinedet精度时需要解析.xml文件,需要手动在代码中将转换后的KITTI.xml中没有的标注注释掉,否则会报错。
对了,在txt_to_xml.py中

这一行用来获取当前路径,原博主的当前工作路径就是数据集的存放路径,而我的不是,所以这里直接将cur_di的值改成自己数据集的存放路径就好了。像这样:
cur_dir='D:/TSBrowserDownloads/KITTI/'
接下来是生成训练验证测试集:使用create_train_test_txt.py工具。最终的结果如下所示

接下来可以利用create_list.sh和create_data.sh脚本生成相应的list和lmdb格式数据了。由于KITTI数据集中图片的格式是png而原本VOC数据集中的图片是jpg格式,在运行脚本之前记得将create_list.sh中的jpg换成png...下面是我改过之后的create_list.sh画线的地方添加了\r,至于为什么要添加这个符号就是因为我是用windows生成的训练验证测试集,然后用linux生成的list咯,这两个系统之间由于格式问题导致找不到图片和相应的.xml文件,但是自己在目录里明明找得到....一直以为是路径问题,然后我在这里花了一两周的时间.....(血一样的教训)

生成的list格式应该是这样的
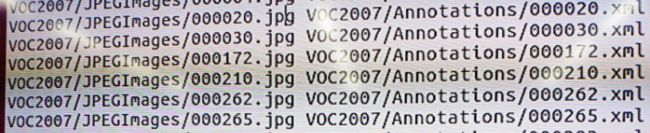
没加\r之前生成的格式是这样的,同时在create_data时还找不到路径

然后,在create_data.sh中有一个映射文件labelmap_voc.prototxt,这个映射文件里只能出现需要检测的种类,原来程序中是21(加上背景),去掉不需要检测的类别,像这样:
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "Car"
label: 1
display_name: "Car"
}
item {
name: "Cyclist"
label: 2
display_name: "Cyclist"
}
这里需要注意一下,原来VOC中的汽车是car,KITTI中的汽车是Car...在程序中改一下
在RefineDet/test/lib/datasets/pascal_voc.py中将
是改成self._classes = ('__background__', ‘Car', 'Cyclist')
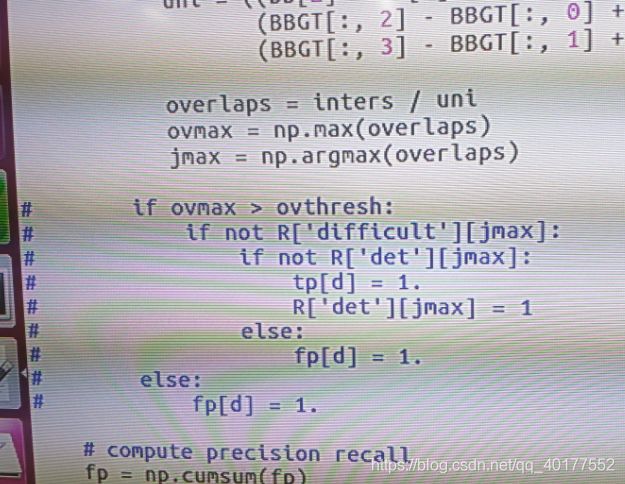
在RefineDet/test/lib/datasets/voc_eval.py中将在这些地方注释掉(前面说了,生成的.xml没有这些标注),如果不注释掉在测试精度的时候会提示没有某某属性,如果不将.jpg改成png则会出现找不到xxx.jpg的错误
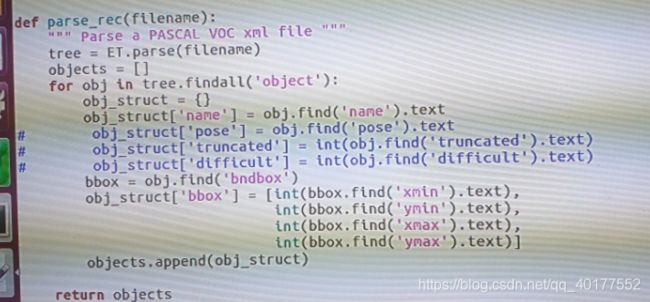
在RefineDet/test/refinedet_demo.py中将箭头处的.jpg改成.png

然后就可以测试精度以及检测(记得将RefineDet/examples/images/里用来演示demo的图片换成对应序号的png文件)。
检测结果如下:


嗯......昨天忘记修改refinedet_demo.py中的labelmap_voc.prototxt文件了(我自己新建了一个映射文件)...今天修改了之后再重新检测检测了一下:





实验还有很多不足的地方!!
最后的loss=2.85349(这是320的模型,但损失很大了!!),如果有路过的大佬还请指教一下,怎样能将loss降下去
总结一下,如果要检测某几种种类而不是原来程序中的21类的话,需要修改的地方:
(1).xml文件里只能出现需要检测的种类
(2)labelmap_voc.prototxt里只能出现需要检测的种类
(3)pascal_voc.py中只能出现需要检测的种类