user_namespace分析(1)
1 前言
Linux系统的安全体系文件权限管理是通过自主访问机制(Discretionary Access Control,DAC)实现的。自主访问机制指对象(比如程序、文件或进程等)的拥有者可以任意的修改或授予此对象相应的权限。Linux的UGO(User、Ggroup、Other)和ACL(Access Control List,访问控制列表)权限管理方式就是典型的自主访问机制。
Linux支持UGO和ACL权限管理方式,UGO将权限位信息存储在节点的权限中,ACL将权限位信息存储在节点的扩展属性中。不同的文件系统权限位的存储与处理方式不一样,具体的文件系统实现了文件权限的管理。
早期linux信任状模型非常简单,就是超级用户对普通用户模型。普通用户的很多操作如果需要root权限,要通过setuid实现。如果程序编写的不好,就可能被攻击者利用,获得系统的控制权。使用能力机制可以减小这种风险。系统管理员为了系统的安全可以剥夺root用户的能力,这样即使root用户也将无法进行某些操作。这个过程是不可逆的,也就是说如果一种能力被删除,除非重新启动系统,否则即使root用户也无法重新添加被删除的能力。
原来的linux系统只有一份用户管理的视图,user_ns的引入使得linux系统管理员可以给普通用户抽象出一份宿主机用户管理视图的子集,在此子集中的用户及其资源对其用户管理视图的感知如同子集就是独自拥有一台宿主机,其有自己的root用户。
本文分析了UGO和ACL权限管理方式和能力机制,在此基础上分析了user_namespace是怎么做到用户的虚拟化。
2 UGO文件权限管理
传统的linux文件系统的UGO权限管理方式在文件和目录上设置权限位,用来控制用户或用户组对文件或目录的访问。文件或目录文件创建时,文件系统会将文件类型、时间信息、权限信息、权限位信息等存入到文件的节点中。
2.1 文件的权限位分配
一个文件创建后,它具有读、写和执行三种操作方式,UGO权限管理方式将文件访问的操作者简单的分为三类:文件属主、同组用户和其他组用户。文件属主指创建文件的用户,他是文件的拥有者,它可以设置用户的读、写和执行权限。同组用户是指与文件属主是同一个用户组的用户。
UGO权限管理方式将文件的权限用3组分别为3位二进制位描述,并在最前面加上一位作为文件类型标识。每一组表示一类用户,其读、写、执行权限分别用一位表示,具有权限时,就将该位设置为1。读、写、执行权限分别用r、w、x表示。
例如,一个文件的权限列出如下:
-rwxr-xr-x 1 root root 12371 Jul 12 22:56 client
最前面一位‘-’,表示文件类型为普通文件。
第一组为“rwx”,表示文件属主具有读、写和执行权限。
第二组为“r-x”,表示同组的其他用户具有读与执行权限,但是没有写权限。
第三组为“r-x”,表示其他组用户具有读与执行权限,但是没有写权限。
在UGO权限管理方式中,第一个4位二进制组的第一位表示文件类型,这些文件类型详见下表:
描述符 |
文件类型 |
d |
目录 |
l |
符号链接 |
s |
套接字文件 |
b |
块设备文件 |
c |
字符设备文件 |
p |
命名管道文件 |
- |
普通文件 |
例如一个目录的权限位如下:
drwxr-xr-x 2 root root 4096Jul 5 04:41 Desktop
最前面一位是’d’,表示文件类型为目录。
目录和文件的权限位是一样的,但是目录与文件在权限定义上有一些区别,目录的读操作指列出目录中的内容,写操作指在目录中创建或删除文件,执行操作指搜索和访问目录。
2.2 改变权限的命令
用户缺省创建文件时,用户本身对这个文件有读写操作权限,其他用户对它具有读操作权限。用户缺省创建目录时,用户本身对目录有读、写和执行权限,同组用户有读和执行权限,其他组用户有执行权限。
用户可以使用命令chmod来改变权限位,只有用户是文件的所有者或者root用户,他才能有权限改变权限位。
命令chmod有符号模式和绝对模式,符号模式指用权限位的符号形式来设置新权限位,绝对模式指直接用权限位的二进制的数字形式设置权限位。
(1) chmod命令的符号模式
chmod命令的格式列出如下:
chmod [who] operator [permission] filename
who 的含义列出如下:
u 文件属主权限。
g 属组用户权限。
o 其他用户权限。
a 所有用户。
operator的含义列出如下:
+ 增加权限。
- 取消权限。
= 设定权限。
permission的含义列出如下:
r 读权限。
w 写权限。
x 执行权限。
s 文件属主和组set-ID。
t 粘性位。
i 给文件加锁,使其他用户无法访问。
u,g,o分别表示对文件属主、同组用户及其他组用户操作。
t sticky bit, 常用于共享文件,如:/tmp分区。设置t位之后,同组用户即使对文件有写操作权限,也不能删除文件。
举些例子如下:
chmod a-x temp//删除所有用户的执行权限
chmod og-w temp//删除同组用户和其他用户的写权限
(2) chmod 命令的绝对模式
chmod 命令绝对模式的一般形式为:
chmod [mode] file
其中mode是一个八进制数,表示权限位。在绝对模式中,每一个权限位用一个八进制数来代表,权限位说明如下:
0400 文件属主可读
0200 文件属主可写
0100 文件属主可执行
0040 同组用户可读
0020 同组用户可写
0010 同组用户可执行
0004 其他用户可读
0002 其他用户可写
0001 其他用户可执行
计算八进制权限的计算方式如下:
文件属主:rwx:4+2+1
同组用户:rwx:4+2+1
其他用户:rwx:4+2+1
例如:chmod 666 filename 所有用户都具有读和写的权限。
2.3 suid/guid
如果属主对文件设置了suid权限,那么其他用户在shell执行文件时也具有其属主的相应权限。如果属主是root用户,那么其他普通用户在执行文件时也具有root用户的权限。guid有相似的机制,执行相应文件的用户将具有该文件所属用户组的用户的权限。
设置suid的方法是将相应的权限位之前的那一位设置为4,设置guid的方法是将相应的权限位之前的那一位设置为2,如果同时设置suid和guid,将相应的权限位之前的那一位设置为4+2.设置suid或guid需要同时设置执行权限位。
例:设置suid
下面方法给文件test设置了suid,755表示文件属主具有读、写和执行的权限,同组用户和其他用户具有读和执行的权限。
chmod 4755 test
chmod u+s test
设置结果为:rws r-x r-x, 其中s表示设置了suid, 表示其他用户在shell执行test时具有属主权限。
例:同时设置suid和guid
下面方法给文件test设置了suid和guid位,711表示文件属主具有读、写和执行的权限,同组用户和其他用户具有执行的权限。
chmod 6711 test
设置结果为:rws --s --x。第一个s表示设置了suid,第二个s表示设置了guid位。
2.4 umask
umask命令用于设置umask值,通过设置umask值,可以为新创建的文件和目录设置缺省权限。Umask命令的形式如下:
umask nnn
其中nnn为umask的值,范围为000-777
umask值与创建时的权限位进行“与非”逻辑计算,相当于从权限位中去掉相应的位,得到缺省的权限位。
例如,umask值为002时,创建文件和目录的缺省权限分别为664和775.因为文件创建时为666,666与002进行“与非”逻辑运算后得到664。目录创建时权限为777,777与002进行“与非”逻辑运算后得到775。命令umask设置的方法如下:
umask 002
2.5 UGO权限检查分析
目前系统由于有多种安全策略,除了UGO的方式还有ACL和能力机制,系统已经将这些机制整合在一起做检查,耦合性较大,详见3.4.3节分析。
3 linux能力机制
早期linux信任状模型非常简单,就是超级用户对普通用户模型。普通用户的很多操作如果需要root权限,要通过setuid实现。如果程序编写的不好,就可能被攻击者利用,获得系统的控制权。使用能力机制可以减小这种风险。系统管理员为了系统的安全可以剥夺root用户的能力,这样即使root用户也将无法进行某些操作。这个过程是不可逆的,也就是说如果一种能力被删除,除非重新启动系统,否则即使root用户也无法重新添加被删除的能力。
3.1 能力的定义
能力机制相关结构列出如下(路径为include/linux/capaibility.h)
typedef struct kernel_cap_struct {
__u32 cap[_KERNEL_CAPABILITY_U32S];
} kernel_cap_t;
typedef struct __user_cap_data_struct {
__u32effective; //进程中有效的能力,是permitted的子集,允许的能力不一定有效
__u32permitted; //进程允许使用的能力
__u32inheritable; //能够被当前进程执行的程序继承的能力
} __user *cap_user_data_t;
每个进程的结构中有三个和能力相关的位图变量,列出如下(路径为include/linux/sched.h):
Struct task_struct{
…….
//进程信任值
const struct cred __rcu *cred;
}
struct cred{
……
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable;/* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capabilitybounding set */
}
每种能力由一位表示,1表示具有某种能力,0表示没有。因为_KERNEL_CAPABILITY_U32S=2,所以这三个能力变量最大只能表示64个能力。当进程进行操作时,检查任务结构中cap_effective的对应位是否有效,例如,如果一个进程要设置系统的时钟,linux的内核就会检查cap_effective的CAP_SYS_TIME位是否有效。能力的宏定义列出如下(路径为include/linux/capability.h):
CAP_CHOWN 0 //允许改变文件的所有权
CAP_DAC_OVERRIDE 1 //忽略对文件的所有DAC访问限制
CAP_DAC_READ_SEARCH 2 //忽略所有对读、搜索操作的限制
CAP_FOWNER 3 //忽略对文件拥有者的权限检查
CAP_FSETID 4 //忽略对文件setuid和setgid标志设置的限制
CAP_KILL 5 //产生信号时绕过权限检查
CAP_SETGID 6 //允许改变组ID
CAP_SETUID 7 //允许改变用户ID
CAP_SETPCAP 8 //允许向其他进程转移能力以及删除其他进程的能力
CAP_LINUX_IMMUTABLE 9 //允许修改文件的不可修改和只添加属性
CAP_NET_BIND_SERVICE 10 //允许绑定到小于1024的端口
CAP_NET_BROADCAST 11 //允许网络广播和多播访问
CAP_NET_ADMIN 12 //允许执行网络管理任务:接口、防火墙和路由等
CAP_NET_RAW 13 //允许使用原始套接字
CAP_IPC_LOCK 14 //允许锁定共享内存片段
CAP_IPC_OWNER 15 //忽略IPC所有权限检查
CAP_SYS_MODULE 16 //允许插入和删除内核模块
CAP_SYS_RAWIO 17 //允许对ioperm/iopl的访问
CAP_SYS_CHROOT 18 //允许使用chroot系统调用
CAP_SYS_PTRACE 19 //允许跟踪任何进程
CAP_SYS_PACCT 20 //允许配置进程记账
CAP_SYS_ADMIN 21 //允许执行系统管理任务:加载、卸载文件系统,配置磁盘配额,开、关交换设备和文件等
CAP_SYS_BOOT 22 //允许重新启动系统
CAP_SYS_NICE 23 //允许提升优先级,设置其他进程的优先级
CAP_SYS_RESOURCE 24 //忽略资源限制
CAP_SYS_TIME 25 //允许改变系统时钟
CAP_SYS_TTY_CONFIG 26 //允许配置TTY设备
CAP_MKNOD 27 //允许使用mknod系统调用
CAP_LEASE 28 //允许对文件进行租借
CAP_AUDIT_WRITE 29 //允许对审计进行写
CAP_AUDIT_CONTROL 30 //允许对审计进行控制
CAP_SETFCAP 31 //允许设置文件权能
CAP_MAC_OVERRIDE 32 //允许覆盖mac策略
CAP_MAC_ADMIN 33 //允许添加、修改mac策略等
CAP_SYSLOG 34 //允许配置syslog
CAP_WAKE_ALARM 35 //允许触发唤醒系统的操作
内核提供了两个系统调用,sys_capget和sys_capset用来得到或设置置顶PID或者所有进程的能力,这两个函数都是对task_struct的cred与权能相关的属性进行操作的。
在cred结构中有cap_bset设置初始进程的能力,赋值如下:cap_bset = CAP_FULL_SET。
Root用户可以删除系统的能力,但是不能再恢复被删除的能力,,只有init进程能够添加能力。通常,一个能力如果从能力边界集中被删除,那么只有系统重启才能够恢复。
3.2 能力机制操作函数集
Linux对权能的操作函数定义在操作函数集selinux_ops(路径为security\selinux\hooks.c),
列出关键部分如下:
static struct security_operationsselinux_ops = {
……
.ptrace_access_check= selinux_ptrace_access_check,//检查是否有执行ptrace的权能
.capget= selinux_capget,//返回有效权能、允许权能和可继承权能的能力值
.capset= selinux_capset,//给目标进程设置有效权能、允许权能和可继承权能的能力值
.capable= selinux_capable,//检查进程是否具有函数中的参数指定的权能
.syslog= selinux_syslog,//检查进程是否有管理syslog的权能
.vm_enough_memory= selinux_vm_enough_memory,//检查进程是否有系统管理员的权限去检查系统是否有足够的内存页
.netlink_send= selinux_netlink_send,//设置结构netlink_skb_parms的成员eff_cap为当前进程的有效权能
.bprm_set_creds= selinux_bprm_set_creds,//给进程设置能力集
.bprm_secureexec= selinux_bprm_secureexec,//检查当前进程uid与euid、gid与euid是否相等
……
};
进程运行时,通过检查进程的有效能力集cap_effective的能力位,判断进程是否具有相应的能力。检查能力的常用函数如下:
bool ns_capable(struct user_namespace *ns, int cap)
{
if(unlikely(!cap_valid(cap))) {
printk(KERN_CRIT"capable() called with invalid cap=%u\n", cap);
BUG();
}
if(security_capable(current_cred(), ns, cap) == 0) {
current->flags|= PF_SUPERPRIV;
return true;
}
return false;
}
3.3 应用程序运行时设置信任值
当用户在shell中键入一个命令时,为满足请求而装入系统的程序可以从shell接收一些命令行参数,例如:ls –l /home 以获得/home目录下的所有文件列表时,shell进程创建一个新进程来执行这个命令。这个新进程会将/bin/ls 可执行文件装入系统的线性空间,在此过程中从shell继承的大多数执行上下文都会被丢弃,但是三个单独的参数ls –l/home 依然会保持。其他的可执行文件的执行也是同样的道理。
Linux系统提供了一系列函数,这样的函数名以前缀exec开始,这些函数能将可执行文件所描述的新的上下文代替进程的上下文环境,换句话说,执行一个程序就是用这个程序的上下文来替换目前正在运行的进程的上下文,本文主要关注和权限相关的一些重要的部分,其他部分不做分析。
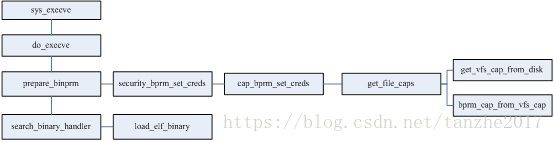
按函数执行顺序分析如下:
1、 sys_execve 接收三个参数,分别为文件名、命令行参数、环境变量;
2、 do_execve 接收三个参数,分别为文件名、命令行参数、环境变量;
3、 prepare_binprm 将可执行文件inode的信息填入linux_binprm,我们主要关注这部分的内容;
4、 search_binary_handler 主要调用load_elf_binary将可执行文件加载进进程的执行线性空间,开始执行。
关键函数详细分析如下:
int prepare_binprm(struct linux_binprm *bprm)
{
umode_t mode;
struct inode * inode =bprm->file->f_path.dentry->d_inode;
int retval;
mode = inode->i_mode;
if (bprm->file->f_op == NULL)
return -EACCES;
/* 清除上一次进程执行中的setuid和setgid的结果 */
bprm->cred->euid = current_euid();
bprm->cred->egid = current_egid();
if(!(bprm->file->f_path.mnt->mnt_flags & MNT_NOSUID)) {
/* 如果文件设置了suid的标记位 */
if (mode & S_ISUID) {
if(!kuid_has_mapping(bprm->cred->user_ns, inode->i_uid))
return -EPERM;
bprm->per_clear |=PER_CLEAR_ON_SETID;
bprm->cred->euid = inode->i_uid;
}
/*如果文件设置了sgid的标记位*/
if ((mode & (S_ISGID | S_IXGRP))== (S_ISGID | S_IXGRP)) {
if(!kgid_has_mapping(bprm->cred->user_ns, inode->i_gid))
return -EPERM;
bprm->per_clear |=PER_CLEAR_ON_SETID;
bprm->cred->egid =inode->i_gid;
}
}
/* 重新组织bprm的安全策略 ,我们重点分析该函数*/
retval = security_bprm_set_creds(bprm);
if (retval)
return retval;
bprm->cred_prepared = 1;
memset(bprm->buf, 0, BINPRM_BUF_SIZE);
return kernel_read(bprm->file, 0,bprm->buf, BINPRM_BUF_SIZE);
}
intcap_bprm_set_creds(struct linux_binprm *bprm)
{
const struct cred *old = current_cred();
struct cred *new = bprm->cred;
bool effective, has_cap = false;
int ret;
kuid_t root_uid;
effective = false;
ret = get_file_caps(bprm, &effective,&has_cap);//获取该可执行文件的扩展属性上的权能信息,如果有的话,将其重新组织填充bprm->cred
if (ret < 0)
return ret;
root_uid = make_kuid(new->user_ns, 0);//将user命名空间中的root转换为其所对应的系统全局的视图中的kuid
if (!issecure(SECURE_NOROOT)) {
/*
* If the legacy file capability is set, thendon't set privs
* for a setuid root binary run by a non-rootuser. Do set it
* for a root user just to cause least surpriseto an admin.
*/
if (has_cap &&!uid_eq(new->uid, root_uid) && uid_eq(new->euid, root_uid)) {
warn_setuid_and_fcaps_mixed(bprm->filename);
goto skip;
}
/*
* To support inheritance of root-permissionsand suid-root
* executables under compatibility mode, weoverride the
* capability sets for the file.
*
* If only the real uid is 0, we do not set theeffective bit.
*/
if (uid_eq(new->euid, root_uid) ||uid_eq(new->uid, root_uid)) {
/* pP' = (cap_bset & ~0) |(pI & ~0) */
new->cap_permitted =cap_combine(old->cap_bset,
old->cap_inheritable);
}
if (uid_eq(new->euid, root_uid))
effective = true;
}
skip:
/* Don't let someone trace a set[ug]id/setpcapbinary with the revised
*credentials unless they have the appropriate permit
*/
if ((!uid_eq(new->euid, old->uid) ||
!gid_eq(new->egid, old->gid) ||
!cap_issubset(new->cap_permitted, old->cap_permitted)) &&
bprm->unsafe & ~LSM_UNSAFE_PTRACE_CAP) {
/* downgrade; they get no more thanthey had, and maybe less */
if (!capable(CAP_SETUID)) {
new->euid = new->uid;
new->egid = new->gid;
}
//合并新、旧两个cap_permitted,即合并进程的cap_permitted和文件扩展属性上的cap_permitted。
new->cap_permitted =cap_intersect(new->cap_permitted,
old->cap_permitted);
}
new->suid = new->fsuid = new->euid;
new->sgid = new->fsgid = new->egid;
if (effective)
new->cap_effective =new->cap_permitted;
else
cap_clear(new->cap_effective);
bprm->cap_effective = effective;
/*
* Auditcandidate if current->cap_effective is set
*
* We donot bother to audit if 3 things are true:
* 1) cap_effective has all caps
* 2) we are root
* 3) root is supposed to have all caps(SECURE_NOROOT)
* Sincethis is just a normal root execing a process.
*
* Number1 above might fail if you don't have a full bset, but I think
* thatis interesting information to audit.
*/
if (!cap_isclear(new->cap_effective)) {
if (!cap_issubset(CAP_FULL_SET,new->cap_effective) ||
!uid_eq(new->euid, root_uid) || !uid_eq(new->uid, root_uid) ||
issecure(SECURE_NOROOT)) {
ret =audit_log_bprm_fcaps(bprm, new, old);
if (ret < 0)
return ret;
}
}
new->securebits &=~issecure_mask(SECURE_KEEP_CAPS);
return 0;
}
3.4 ACL权限管理
由于UGO权限管理方式只能对文件的属主、同组用户和其他用户进行权限管理,很难对每个用户或者用户组进行权限管理,这种局限性导致了ACL的产生。
ACL(AccessControl List,访问控制列表)对UGO权限管理方式进行了扩展,可以对任意的用户/组分配读、写、和执行操作权限。EXT2/EXT3/EXT4等文件系统都支持ACL。当设置了ACL属性并用命令ls –l查看文件时,ACL属性表现为UGO权限位末尾的“+”符号。为了让文件系统支持ACL,在挂在分区时需要添加参数“acl”。手动挂载的命令如下:mount –t ext3 –o rw,acl/dev/hda1/your_mount_point。
3.4.1 ACL权限管理命令
ACL权限管理使用命令getfacl查看ACL属性,使用setfacl设置ACL属性。下面分别说明这两个命令。
(1) 命令getfacl
用来显示文件名、所有者、组和访问控制列表。如果一个目录有缺省的ACL,它将显示缺省的ACL,非目录没有缺省的ACL。如果getfacl用于不支持ACL的文件系统,它将显示传统的UGO权限管理方式的权限位信息。
例如:命令getfacl获取文件test的ACL信息的方法如下:
getfacl test
#file:test
#owner:root
#group:root
user::rw-
group::r--
other::r--
(2) 命令setfacl
命令setfacl用来设置文件访问控制列表,命令格式如下:
setfacl [-bkndRLPvh] [{-m|-x }acl_spec] [-M|-X} acl_file]file …
其中,选项-m和-M表示修改ACL,-x和-X表示删除ACL条目。详细的说明请参考man文档。
如果在不支持ACL的文件体统使用命令setfacl,它将以最接近于ACL的权限修改权限位。例如,设置ACL的命令如下:
setfacl –m u:zhj:rw test
该命令表示对test文件,给用户zhj设置了读和写权限。使用命令ls –l查看,可发现权限位的末尾多出了个“+“号,它表示设置了ACL。命令ls –l结果如下:
-rw-rw-r--+ 1 root root 0 Aug 2214:55 test
再使用getfacl查看ACL信息,发现给zhj用户设置了读写权限,如下所示:
#file:test
#owner:root
#group:root
user::rw-
user:zhj:rw-
group::r—
other::r—
3.4.2 命令getfacl和setfacl机制分析
命令getfacl通过调用函数acl_get_file得到每个文件的ACL信息;命令setfacl通过调用函数acl_set_file设置文件的ACL信息。ACL信息存储在文件系统的节点的扩展属性中,不同类型的文件系统,节点数据以不同的形式存放于硬盘上。
函数acl_get_file调用文件系统的函数getxattr,从节点的扩展属性中得到ACL信息,然后转换成本地的ACL信息结构,最后,由命令getfacl将本地ACL信息结构转换成适合显示的格式显示在终端上。
命令acl_set_file将用户输入的信息转换成本地ACL信息结构,再将本地ACL信息结构转换成文件系统的ACL信息结构,然后将ACL信息更新到节点的扩展属性中。
由于函数acl_set_file和acl_get_file的机制类似,只是操作过程相反,因此,我们仅概要分析acl_get_file函数。函数acl_get_file得到一个文件的ACL数据,如果该节点存在扩展属性,它将调用文件系统的系统调用函数getxattr从扩展属性中获取ACL数据,如果扩展属性不存在,它将调用函数stat从节点的属性读取权限信息为数据,并调用acl_from_mode将它转化成acl数据。
3.4.3 文件系统检查ACL权限分析
文件系统的节点操作函数集vfs_ops含有操作许可函数指针permission,它指向具体文件系统的操作许可函数,用来检查文件或目录的操作权限。对于ext4文件系统来说,它没有注册自己的permission回调函数,那么他就调用通用的generic_permission,代码简要分析如下:
intgeneric_permission(struct inode *inode, int mask)
{
int ret;
/*进行UGO与ACL的权限位的检查,检查通过返回0,否则返回非0
ret = acl_permission_check(inode, mask);
if (ret != -EACCES)
return ret; //如果UGO或者ACL检查通过,函数返回,否则还需进行权能的判断才能确定检查结果。
if (S_ISDIR(inode->i_mode)) {
/*忽略文件的访问许可权的检查*/
if (inode_capable(inode,CAP_DAC_OVERRIDE))
return 0;
if (!(mask & MAY_WRITE))
if (inode_capable(inode,CAP_DAC_READ_SEARCH))
return 0;
return-EACCES;
}
/*
* 忽略文件的读写权限的检查
* 如果有执行位被设置,那么忽略可执行权限的检查
*/
if (!(mask & MAY_EXEC) ||(inode->i_mode & S_IXUGO))
if (inode_capable(inode,CAP_DAC_OVERRIDE))
return 0;
mask &= MAY_READ | MAY_WRITE | MAY_EXEC;
if (mask == MAY_READ)
if (inode_capable(inode,CAP_DAC_READ_SEARCH))
return 0;
return -EACCES;
}
static int acl_permission_check(structinode *inode, int mask)
{
unsigned int mode = inode->i_mode;
if (likely(uid_eq(current_fsuid(),inode->i_uid)))//如果当前进程的fsuid与文件的uid相等,mode右移6位得到文件所有者权限
mode >>= 6;
else {
if (IS_POSIXACL(inode) &&(mode & S_IRWXG)) {
int error = check_acl(inode,mask);//检查acl权限
if (error != -EAGAIN)
return error;
}
if (in_group_p(inode->i_gid))//如果文件的gid属于进程用户组,则mode右移3位得到组权限位
mode >>= 3;
}
if ((mask & ~mode & (MAY_READ |MAY_WRITE | MAY_EXEC)) == 0)
return 0;
return -EACCES;
}
如果该函数generic_permission返回0,则表示文件的访问权限检查通过,否则表示文件要求的访问权限未通过检查,返回permission deny。
每个文件系统都会有自己注册的inode_operations的permission回调函数用以对请求的对文件的操作进行访问权限的检查,如果某文件系统未注册permission回调函数,那么就会使用通用的generic_permission进行检查。每个文件系统由于实现机制不同,所有有不同的访问权限的检查方式,具体问题需要具体的分析。