理解逻辑回归中的ROC曲线和KS值
1.回归和分类任务
-
分类和回归都属于监督学习(训练样本带有信息标记,利用已有的训练样本信息学习数据的规律预测未知的新样本标签)
-
分类预测的结果是离散的(例如预测明天天气-阴,晴,雨)
-
回归预测的任务是连续的(例如预测明天的温度,23,24,25度)
分类中比较常用的是二分类(label结果为0或1两种)
2.逻辑回归不是回归
从名字来理解逻辑回归.在逻辑回归中,逻辑一词是logistics [lə’dʒɪstɪks]的音译字,并不是因为这个算法是突出逻辑的特性.
逻辑回归在分类上属于回归范畴,只不过它是利用回归的思路来做分类。
3.举个栗子
逻辑回归就是在用回归的办法做分类任务,先举个列子:最简单的二分类,结果是正例或者负例的任务.
3.1 一个二分类的栗子
按照多元线性回归的思路,我们可以先对这个任务进行线性回归,学习出这个事情结果的规律,比如根据人的饮食,作息,工作和生存环境等条件预测一个人"有"或者"没有"得恶性肿瘤,可以先通过回归任务来预测人体内肿瘤的大小,取一个平均值作为阈值,假如平均值为y,肿瘤大小超过y为恶心肿瘤,无肿瘤或大小小于y的,为非恶性.这样通过线性回归加设定阈值的办法,就可以完成一个简单的二分类任务.如下图:

上图中,红色的x轴为肿瘤大小,粉色的线为回归出的函数![]() )的图像,绿色的线为阈值.
)的图像,绿色的线为阈值.
预测肿瘤大小还是一个回归问题,得到的结果(肿瘤的大小)也是一个连续型变量.通过设定阈值,就成功将回归问题转化为了分类问题.但是,这样做还存在一个问题.
我们上面的假设,依赖于所有的肿瘤大小都不会特别离谱,如果有一个超大的肿瘤在我们的例子中,阈值就很难设定.加入还是取平均大小为阈值,则会出现下图的情况:

从上边的例子可以看出,使用线性的函数来拟合规律后取阈值的办法是行不通的,行不通的原因在于拟合的函数太直,离群值(也叫异常值)对结果的影响过大,但是我们的整体思路是没有错的,错的是用了太"直"的拟合函数,如果我们用来拟合的函数是非线性的,不这么直,是不是就好一些呢?
所以我们下面来做两件事:
-
找到一个办法解决掉回归的函数严重受离群值影响的办法.
-
选定一个阈值.
3.2 把函数掰弯
原来的判别函数我们用线性的y = [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4vTdRP2F-1571629173795)(https://private.codecogs.com/gif.latex?w%5E%7BT%7Dx)],逻辑回归的函数呢,我们目前就用sigmod函数,函数如下:

公式中,e为欧拉常数(是常数,如果不知道,自行百度),Z就是我们熟悉的多元线性回归中的,建议现阶段大家先记住逻辑回归的判别函数用它就好了.如果你不服,请参考:朱先生1994的博客(博客讲的很好).
就像我们说多元线性回归的判别函数为一样.追究为什么是他花费的经历会比算法本身更多.
sigmod函数的图像如下:
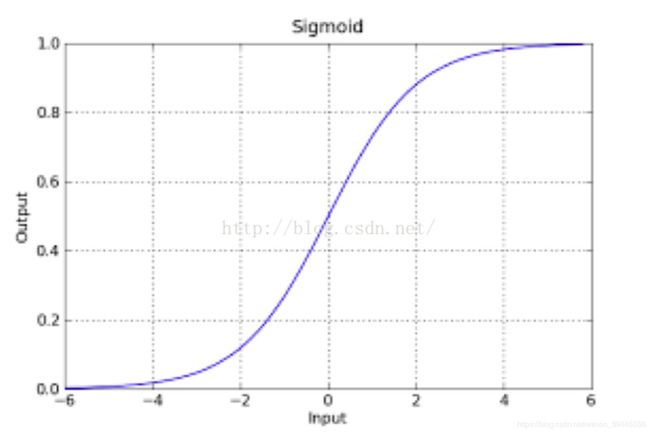
该函数具有很强的鲁棒性(鲁棒是Robust的音译,也就是健壮和强壮的意思),并且将函数的输入范围(∞,-∞)映射到了输出的(0,1)之间且具有概率意义.具有概率意义是怎么理解呢:将一个样本输入到我们学习到的函数中,输出0.7,意思就是这个样本有70%的概率是正例,1-70%就是30%的概率为负例.
再次强调一下,如果你的数学功底很好,可以看一下我上边分享的为什么是sigmod函数的连接,如果数学一般,我们这个时候没有必要纠结为什么是sigmod,函数那么多为什么选他.学习到后边你自然就理解了.
总结一下上边所讲:我们利用线性回归的办法来拟合然后设置阈值的办法容易受到离群值的影响,sigmod函数可以有效的帮助我们解决这一个问题,所以我们只要在拟合的时候把即y = 换成即可,其中
z=,也就是说g(z) = . 同时,因为g(z)函数的特性,它输出的结果也不再是预测结果,而是一个值预测为正例的概率,预测为负例的概率就是1-g(z).
函数形式表达:
P(y=0|w,x) = 1 – g(z)
P(y=1|w,x) = g(z)
P(正确) = * 为某一条样本的预测值,取值范围为0或者1.
到这里,我们得到一个回归函数,它不再像y=wT * x一样受离群值影响,他的输出结果是样本预测为正例的概率(0到1之间的小数).我们接下来解决第二个问题:选定一个阈值.
3.3 选定阈值
选定阈值的意思就是,当我选阈值为0.5,那么小于0.5的一定是负例,哪怕他是0.49.此时我们判断一个样本为负例一定是准确的吗?其实不一定,因为它还是有49%的概率为正利的.但是即便他是正例的概率为0.1,我们随机选择1w个样本来做预测,还是会有接近100个预测它是负例结果它实际是正例的误差.无论怎么选,误差都是存在的.所以我们选定阈值的时候就是在选择可以接受误差的程度.
我们现在知道了sigmod函数预测结果为一个0到1之间的小数,选定阈值的第一反应,大多都是选0.5,其实实际工作中并不一定是0.5,阈值的设定往往是根据实际情况来判断的.本小节我们只举例让大家理解为什么不完全是0.5,并不会有一个万能的答案,都是根据实际工作情况来定的.
0到1之间的数阈值选作0.5当然是看着最舒服的,可是假设此时我们的业务是像前边的例子一样,做一个肿瘤的良性恶性判断.选定阈值为0.5就意味着,如果一个患者得恶性肿瘤的概率为0.49,模型依旧认为他没有患恶性肿瘤,结果就是造成了严重的医疗事故.此类情况我们应该将阈值设置的小一些.阈值设置的小,加入0.3,一个人患恶性肿瘤的概率超过0.3我们的算法就会报警,造成的结果就是这个人做一个全面检查,比起医疗事故来讲,显然这个更容易接受.
第二种情况,加入我们用来识别验证码,输出的概率为这个验证码识别正确的概率.此时我们大可以将概率设置的高一些.因为即便识别错了又能如何,造成的结果就是在一个session时间段内重试一次.机器识别验证码就是一个不断尝试的过程,错误率本身就很高.
3.3 相关概念
机器学习中
True Positive Rate(真正率 , TPR)或灵敏度(sensitivity)
TPR = TP /(TP + FN)
正样本预测结果数 / 正样本实际数
False Positive Rate (假正率, FPR)
FPR = FP /(FP + TN)
被预测为正的负样本结果数 /负样本实际数
3.4 ROC,AUC,KS曲线
逻辑回归得到的结果是概率,那么就要取阈值来划分正负,这时候,每划一个阈值,就会产生一组FPR和TPR的值,然后把这组值画成坐标轴上的一个点,这样,当选取多组阈值后,就形成了ROC曲线(每次选取一个不同的阈值,我们就可以得到一组FPR和TPR,即ROC曲线上的一点)

ROC曲线是评判一个模型好坏的标准,AUC值就是ROC曲线下方的面积。图中画出的AUC=0.810就是这个模型能得出的最好的AUC值,其对应的阈值也是最好的划分。但是最好的阈值是不能通过这个图知道的,要通过KS曲线得出。
KS曲线的纵轴是表示TPR和FPR的值,就是这两个值可以同时在一个纵轴上体现,横轴就是阈值,,然后在两条曲线分隔最开的地方,对应的就是最好的阈值,也是该模型最好的AUC值,就比如是上图的AUC=0.810,下图中,一条曲线是FPR,一条是TPR。
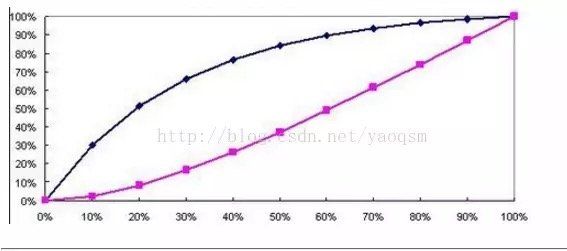
KS值就是max(abs(TPR-FPR)),即:TPR和FPR只差最大的那个值。
参考资料
对ROC和KS曲线的理解
https://blog.csdn.net/yaoqsm/article/details/78334920
真正率、假正率、真负率
https://blog.csdn.net/zyq11223/article/details/79085711
ROC曲线与KS曲线的理解
https://www.jianshu.com/p/07577d1f9fff
关于模型检验的ROC值和KS值的异同_ROC曲线和KS值
http://cda.pinggu.org/view/21012.html
通俗理解线性回归
https://blog.csdn.net/alw_123/article/details/82193535
逻辑回归(logistics regression)
https://blog.csdn.net/weixin_39445556/article/details/83930186