Pandas通过loc、iloc、Ix属性和boolean访问数据
数据访问 在pandas中进行数据访问和修改时是要借助DataFrame(数据帧)来进行的。在此模块中,
主要使用三种索引函数来进行数据访问:
(1)loc:标签索引,行和列的名称;
(2)iloc:整型索引(绝对位置索引);
(3)ix:iloc 和 loc 的整合。
比如这就是我们的基本数据:


import pandas as pd
data=[['China',1328474],['USA',302841],['Japan',127953],['India',1151751]]
df=pd.DataFrame(data,index=['a','b','c','d'],columns=['Country','Population(thousands)'])
print(df)loc--通过自定义索引获取数据,下面两种方法是等价的:
print(df.loc['a'])
print(df.loc['a'],:)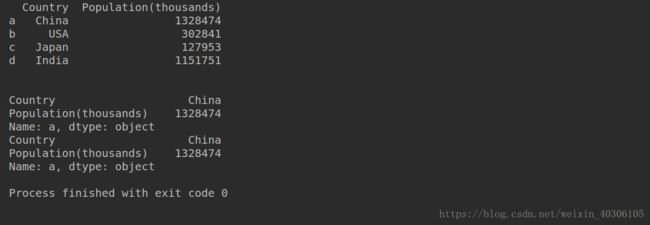
通过loc按列标签选取某列数据。
import pandas as pd #导入pandas库,取别名为pd
data=[['China',1328474],['USA',302841],['Japan',127953],['India',1151751]] #创建一个列表
df=pd.DataFrame(data,index=['a','b','c','d'],columns=['Country','Population(thousands)']) #指定了index
print(df)
print('\n')
print(df.loc[:,'Country'])在使用loc选取列的时候,不能省略行标签的指定,需要使用(:)用切片的方式表示所有行。

通过loc按行、列标签(先行后列)选取指定行和列的数据。
import pandas as pd #导入pandas库,取别名为pd
data=[['China',1328474],['USA',302841],['Japan',127953],['India',1151751]] #创建一个列表
df=pd.DataFrame(data,index=['a','b','c','d'],columns=['Country','Population(thousands)']) #指定了index
print(df)
print('\n')
print(df.loc['a':'c','Country'])
也可以在访问到数据的同时改变数据。
df.loc['c','Country']='None'
iloc--通过数字索引获取数据。iloc使用方法和loc基本一致,只不过iloc通过数字索引。
import pandas as pd #导入pandas库,取别名为pd
data=[['China',1328474],['USA',302841],['Japan',127953],['India',1151751]] #创建一个列表
df=pd.DataFrame(data,index=['a','b','c','d'],columns=['Country','Population(thousands)']) #指定了index
print(df)
print('\n')
print(df.iloc[2,1]) #第2行第1列(行和列都是从0数起)
ix--loc和iloc的结合。ix是loc和iloc的结合,可以混用数字和自定的标签进行索引。
import pandas as pd #导入pandas库,取别名为pd
data=[['China',1328474],['USA',302841],['Japan',127953],['India',1151751]] #创建一个列表
df=pd.DataFrame(data,index=['a','b','c','d'],columns=['Country','Population(thousands)']) #指定了index
print(df)
print('\n')
print(df.ix['c',1])
print(df.ix[2,'Population(thousands)'])第2行(从0数起)的行标签是c,第1列(从0数起)的列表签是Population(thousands)。所以在使用ix获取数据的时候,可以通过行标签也可以通过数字进行索引。
Boolean索引。除上面两种方法之外,还可以使用 DataFrame 中的Boolean索引来对数据进行访问。比如我们只想知道人口大于十亿的国家的数据,就可以使用Boolean索引。
import pandas as pd #导入pandas库,取别名为pd
data=[['China',1328474],['USA',302841],['Japan',127953],['India',1151751]] #创建一个列表
df=pd.DataFrame(data,index=['a','b','c','d'],columns=['Country','Population(thousands)']) #指定了index
print(df)
print('\n')
df_2=df['Population(thousands)']>1000000
print(df_2)
df_3=df[df['Population(thousands)']>1000000]
print(df_3)