redis缓存预热、缓存雪崩、缓存击穿、缓存穿透、缓存降级、缓存更新
目录
- 缓存预热
- 缓存雪崩
- 缓存击穿
- 缓存穿透
- 布隆过滤器(亿级数据过滤算法)
缓存预热
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
缓存预热就是在 redis 启动的时候,就开始往 redis 中写了数据,然后再给应用提供服务。而不是在应用访问的时候才开始往 redis 中写数据。
那么启动的时候,应该往 redis 中写入什么样的数据呢?
- 应该根据当天的具体的访问情况,进行实时的统计出访问量频率较高的数据,即热数据,比如热门商品,热门博客等,把这部分数据提前写入 redis集群中。我们不需要把所有的数据都写入 redis中,也没有这个必要,一是数据量会很大,写入的数据会很慢,二是访问量不大的数据也没有必要写入 redis 中。
- 如果热数据比较多的话,我们可以启动多个服务并行读取数据去写入 redis 集群,进行分布式的缓存预热。
- 当把热数据写入 redis 集群后,才开始对处提供服务。那么这样,大部分的请求都会走 redis 集群,而不需要访问 mysql 数据库。
怎么解决?
- 首先,通过 nginx + lua 的方式,把访问流量数据上报到 Kafka,也可以是其它的 mq 队列。
- 然后使用实时计算框架(如 storm 、spark streaming、flume)从 kafka中消费访问流量数据,实时计算出访问频率高的数据,这里统计出来的可能只会有编号信息,如商品编号或博客编号等。
- 最后,根据编号从 mysql 数据库中查询出具体的信息,写入 redis,开始提供服务。
还有一种解决思路:
- 直接写个缓存刷新页面,上线时手工操作下。
- 数据量不大,可以在WEB系统启动的时候加载。
- 定时刷新缓存,
缓存雪崩
缓存雪崩现象:假设有如下一个系统,高峰期请求为5000次/秒,4000次走了缓存,只有1000次落到了数据库上,数据库每秒1000的并发是一个正常的指标,完全可以正常工作,但如果缓存宕机了,或者缓存设置了相同的过期时间,导致缓存在同一时刻同时失效,每秒5000次的请求会全部落到数据库上,数据库立马就死掉了,因为数据库一秒最多抗2000个请求,如果DBA重启数据库,立马又会被新的请求打死了,这就是缓存雪崩。
解决方法
- 1、事前:redis高可用,主从+哨兵,redis cluster,避免全盘崩溃
- 2、事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL被打死
- 3、事后:redis持久化RDB+AOF,快速恢复缓存数据
- 4、缓存的失效时间设置为随机值,避免同时失效
缓存的失效时间设置为随机值
setRedis(key, value, time+Math.random()*10000);
如果Redis是集群部署,将热点数据均匀分布在不同的Redis库中也能避免全部失效。或者设置热点数据永不过期,有更新操作就更新缓存就好了(比如运维更新了首页商品,那你刷下缓存就好了,不要设置过期时间),电商首页的数据也可以用这个操作,保险。
参考链接:https://blog.csdn.net/qq_29373285/article/details/88544299
https://mp.weixin.qq.com/s/pHXOA8m23V6chO04yus1yA
缓存击穿
缓存击穿就是单个高热数据过期的瞬间,数据访问量较大,未命中redis后,发起了大量对同一数据的数据库访问,导致对数据库服 务器造成压力。应对策略应该在业务数据分析与预防方面进行,配合运行监控测试与即时调整策略,毕竟单个key的过期监控难度 较高,配合雪崩处理策略即可。
缓存击穿和缓存雪崩很相似,缓存雪崩是针对所有的key,缓存击穿针对的是某一个key
场景,假如秒杀一个商品的key,但是这个key过期了,对这个商品的并发量过高。缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案
- 1、
设置热点数据永远不过期。 - 2、
接口限流与熔断,降级。重要的接口一定要做好限流策略,防止用户恶意刷接口,同时要降级准备,当接口中的某些 服务
不可用时候,进行熔断,失败快速返回机制。 - 3、
布隆过滤器。bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是 否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小, - 4、
加互斥锁,互斥锁参考代码如下:
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Autowired
private Jedis jedis;
private final String MUTEX_KEY = "MUTEX_";
public String getData(String key) throws InterruptedException {
String value = stringRedisTemplate.opsForValue().get(key);
//缓存失效
if (StringUtils.isBlank(value)) {
//设置分布式锁,只允许一个线程去查询DB,同时指定过期时间为1min,防止del操作失败,导致死锁,缓存过期无法加载DB数据
if (tryLock(MUTEX_KEY + key, 60L)) {
//从数据库查询数据,将查询的结果缓存起来
value = getValueFromDB();
stringRedisTemplate.opsForValue().set(key, value);
//释放分布式锁
stringRedisTemplate.delete(MUTEX_KEY + key);
} else {
//当锁被占用时,睡眠5s继续调用获取数据请求
Thread.sleep(5000);
getData(key);}
}
return value;
}
/**
* redis实现分布式事务锁 尝试获取锁
*
* @param lockName 锁
* @param expireTime 过期时间
* @return
*/
public Boolean tryLock(String lockName, long expireTime) {
//RedisCallback redis事务管理,将redis操作命令放到事务中处理,保证执行的原子性
String result = stringRedisTemplate.opsForValue().getOperations().execute(new RedisCallback<String>() {
/**
* @param key 使用key来当锁,因为key是唯一的。
* @param value 请求标识,可通过UUID.randomUUID().toString()生成,解锁时通value参数可识别出是哪个请求添加的锁
* @param nx 表示SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作
* @param ex 表示过期时间的单位是秒
* @param time 表示过期时间
*/
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
return jedis.set(lockName, UUID.randomUUID().toString(), "NX", "EX", expireTime);
}
});
if ("OK".equals(result)) {
return true;
}
return false;
}
public String getValueFromDB() {
return "";
}
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户(黑客)不断发起请求,对系统进行恶意的攻击。
举个栗子:我们数据库的id都是从1自增的,如果发起id=-1的数据或者id特别大不存在的数据,这时的用户很可能是攻击者,这样的不断攻击导致数据库压力很大,严重会击垮数据库。
解决办法:
方法一:缓存穿透我会在接口层增加校验,比如用户鉴权,参数做校验,不合法的校验直接return,比如id做基础校验,id<=0直接拦截。
方法二:查询不到的数据也放到缓存,value为空,如 set -999 “”
方法三:Redis里还有一个高级用法布隆过滤器(Bloom Filter)`这个也能很好的预防缓存穿透的发生,他的原理也很简单,就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库中存在,不存在你return就好了,存在你就去查DB刷新KV再return。
https://mp.weixin.qq.com/s/STHQHR-byXZvIKOd-gcKwQ
布隆过滤器(亿级数据过滤算法)
一、先抛出一个问题爬虫系统中URL是怎么判重的?
你可能最先想到的是将URL放到一个set中,但是当数据很多的时候,放在set中是不现实的。
这时你就可能想到用数组+hash函数来实现了。
index = hash(URL) % table.length
即求出URL的hash值对数组长度取模,得到数组的下标,然后设置table[index] = 1,当然数组刚开始的元素都为0
这样每次有新的URL来的时候,先求出index,然后看table[index]的值,当为0的时候,URL肯定不存在,当为1的时候URL可能存在,因为有可能发生hash冲突。即第一次
hash(www.baidu.com) % table.length = 1,table[1]=1,第二次hash(www.javashitang.com) % table.length = 1,此时table[1]=1,系统会认为www.javashitang.com已经爬取过了,其实并没有爬取。
从上面的流程中我们基本可以得出如下结论:hash冲突越少,误判率越低
二、怎么减少hash冲突呢?
- 1、增加数组长度
- 2、优化hash函数,使用多个hash函数来判断
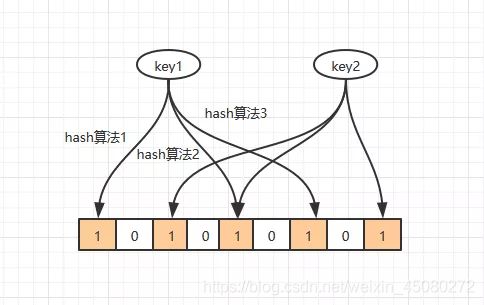
多个hash函数求得数组位置的值都为1时才认为这个元素存在,只要有一个为0则认为这个元素不存在。在一定概率上能降低冲突的概率。
那么hash函数是不是越多越好呢?当然不是了,hash函数越多,数组中1的数量相应的也会增多,反而会增加冲突。所以hash函数不能太多也不能太少。
你可能没意识到布隆过滤器的原理你已经懂了,只不过布隆过滤器存0和1不是用数组,而是用位,我们来算一下申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间,是不是很划算?
三、来总结一下布隆过滤器的特点
- 1、布隆过滤器说某个元素存在,其实有可能不存在,因为hash冲突会导致误判
- 2、布隆过滤器说某个元素不存在则一定不存在
四、使用场景
- 1、判断指定数据在海量数据中是否存在,防止缓存穿透等
- 2、爬虫系统判断某个URL是否已经处理过
五、手写一个布隆过滤器
public class MyBloomFilter {
// 位数组的大小
private static final int DEFAULT_SIZE = 2 << 24;
// hash函数的种子
private static final int[] SEEDS = new int[]{3, 13, 46};
// 位数组,数组中的元素只能是 0 或者 1
private BitSet bits = new BitSet(DEFAULT_SIZE);
// hash函数
private SimpleHash[] func = new SimpleHash[SEEDS.length];
public MyBloomFilter() {
for (int i = 0; i < SEEDS.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, SEEDS[i]);
}
}
// 添加元素到位数组
public void add(Object value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
// 判断指定元素是否存在于位数组
public boolean contains(Object value) {
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
// hash函数有一个计算出为false,则直接返回
if (!ret) {
return ret;
}
}
return ret;
}
// hash函数类
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(Object value) {
int h;
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));
}
}
public static void main(String[] args) {
Integer value1 = 13423;
Integer value2 = 22131;
MyBloomFilter filter = new MyBloomFilter();
// false
System.out.println(filter.contains(value1));
// false
System.out.println(filter.contains(value2));
filter.add(value1);
filter.add(value2);
// true
System.out.println(filter.contains(value1));
// true
System.out.println(filter.contains(value2));
}
}
六、利用Google的Guava工具库实现布隆过滤器
生产环境中一般不用自己手写的布隆过滤器,用Google大牛写好的工具类即可。
1、加入如下依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
// 创建布隆过滤器对象,最多元素数量为500,期望误报概率为0.01
BloomFilter<Integer> filter = BloomFilter.create(
Funnels.integerFunnel(), 500, 0.01);
// 判断指定元素是否存在
// false
System.out.println(filter.mightContain(1));
// false
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
// true
System.out.println(filter.mightContain(1));
// true
System.out.println(filter.mightContain(2));
七、用Redis中的布隆过滤器
Redis4.0以插件的形式提供了布隆过滤器。来演示一波
使用docker安装并启动
docker pull redislabs/rebloom
docker run -itd --name redis -p:6379:6379 redislabs/rebloom
docker exec -it redis /bin/bash
redis-cli
常用的命令如下
# 添加元素
bf.add
# 查看元素是否存在
bf.exists
# 批量添加元素
bf.madd
# 批量查询元素
bf.mexists
127.0.0.1:6379> bf.add test 1
(integer) 1
127.0.0.1:6379> bf.add test 2
(integer) 1
127.0.0.1:6379> bf.exists test 1
(integer) 1
127.0.0.1:6379> bf.exists test 3
(integer) 0
127.0.0.1:6379> bf.exists test 4
(integer) 0
布隆过滤器参考地址:
https://mp.weixin.qq.com/s/HGNopuxceCONkD6ucDBOJQ