FPN 特征金字塔网络
FPN(feature pyramid networks)
特征金字塔是多尺度目标检测系统中的一个基本组成部分。近年来深度学习目标检测却有意回避这一技巧,部分原因是特征金字塔在计算量和用时上很敏感(一句话,太慢)。这篇文章,作者利用了深度卷积神经网络固有的多尺度、多层级的金字塔结构去构建特征金字塔网络。使用一种自上而下的侧边连接,在所有尺度构建了高级语义特征图,这种结构就叫特征金字塔网络(FPN)。其在特征提取上改进明显,把FPN用在Faster R-CNN上,在COCO数据集上,一举超过了目前所有的单模型(single-model)检测方法。
低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
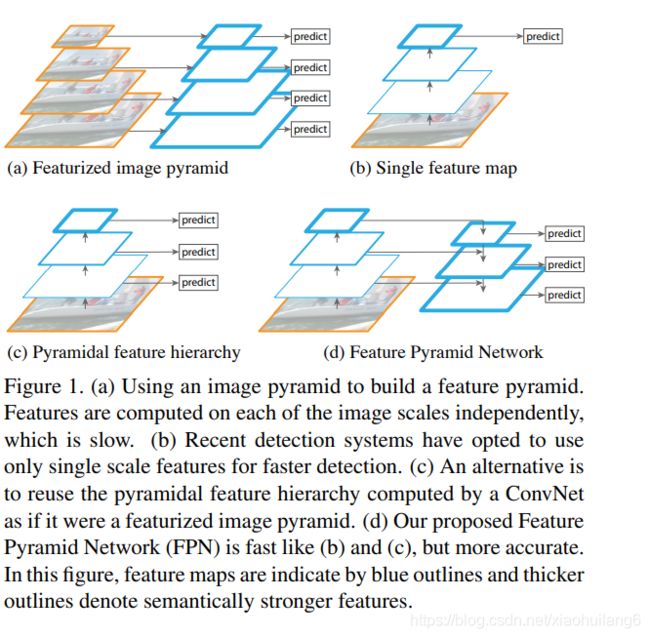
- 传统的图像金字塔任务是将不同尺度的图片进行特征提取(图a),主要使用人工提取特征,在人工提取特征的时代,大量使用特征化图像金字塔。但是这种做法变相的增加了训练数据,提高了运算耗时,所以这种做法已经很少被使用。
- 对于识别任务,工程特征已经被深度卷积网络(ConvNets)计算的特征大部分所取代。除了能够表示更高级别的语义,ConvNets不同层的特征图尺度也不同,从而有助于从单一输入尺度上计算的特征识别(图b)。但是这种做法的缺陷在于只使用了高分辨率特征,因为不同层之间的语义差别很大,最后一层主要都是高分辨率的特征,所以对于低分辨率的特征表现力不足。(SPP net,Fast RCNN,Faster RCNN)
- 接着为了改善上面的做法,一个很简洁的改进就是对不同尺度的特征图都进行利用,这也是SSD算法中使用的方法(图c)。理想情况下,SSD风格的金字塔将重复使用正向传递中计算的不同层次的多尺度特征图。但为了避免使用低层次特征,SSD会从偏后的conv4_3开始构建特征金字塔,这种做法没有对conv4_3之前的层进行利用,而这些层对于检测小目标很重要。
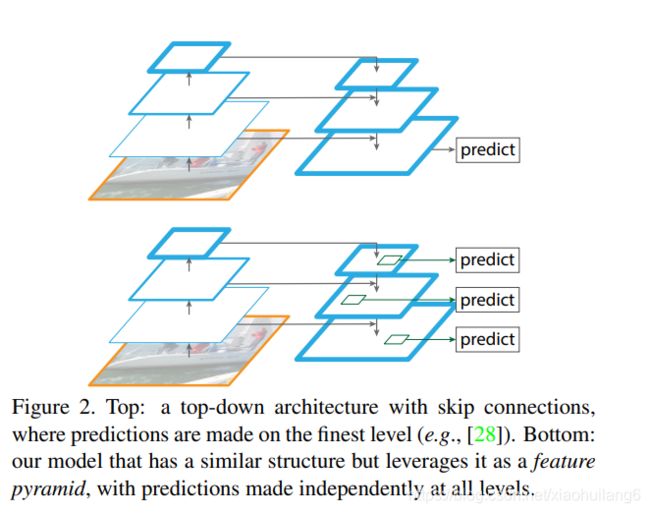
上面一个带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。
而下面一个网络结构和上面的类似,区别在于预测是在每一层中独立进行的。后面有这两种结构的实验结果对比,非常有意思,因为之前只见过使用第一种特征融合的方式。
不是对不同尺寸的特征图进行预测,而是将不同尺寸的特征图融合后进行预测.
网络结构
主网络是使用的ResNet,而特征图金字塔分成三个部分,一个自底向上的路径(左边),一个自顶向下的路径(右边)和中间的连接部分。

图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
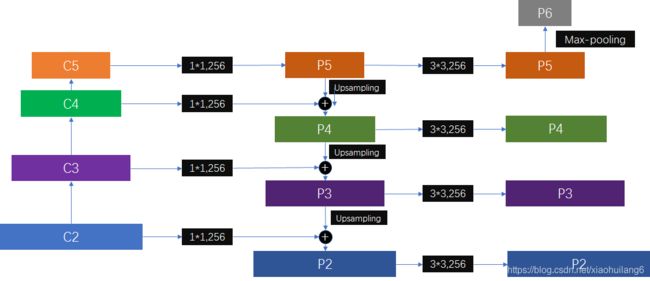
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
一方面将FPN放在RPN网络中用于生成proposal,原来的RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为32^2,64^2,128^2,256^2,512^2,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
结果分析
RPN模块,
不同尺度的ROI,使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?这里作者定义了一个系数Pk,其定义为:

224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么k = k0-1 = 5-1 = 4,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
评价标准采用AR,AR表示Average Recall,AR右上角的100表示每张图像有100个anchor,AR的右下角s,m,l表示COCO数据集中object的大小分别是小,中,大。feature列的大括号{}表示每层独立预测。

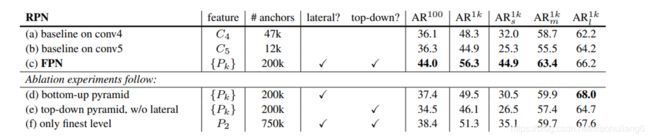
从(a)(b)(c)的对比可以看出FRN的作用确实很明显。另外(a)和(b)的对比可以看出高层特征并非比低一层的特征有效。
(d)表示只有横向连接,而没有自顶向下的过程,也就是仅仅对自底向上(bottom-up)的每一层结果做一个1*1的横向连接和3*3的卷积得到最终的结果,有点像Fig1的(c)。从feature列可以看出预测还是分层独立的。作者推测(d)的结果并不好的原因在于在自底向上的不同层之间的semantic gaps比较大。
(e)表示有自顶向下的过程,但是没有横向连接,即向下过程没有融合原来的特征。这样效果也不好的原因在于目标的location特征在经过多次降采样和上采样过程后变得更加不准确。
(f)采用finest level层做预测(参考Fig2的上面那个结构),即经过多次特征上采样和融合到最后一步生成的特征用于预测,主要是证明金字塔分层独立预测的表达能力。显然finest level的效果不如FPN好,原因在于PRN网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外(f)有更多的anchor,说明增加anchor的数量并不能有效提高准确率。

另一方面将FPN用于Fast R-CNN的检测部分。除了(a)以外,分类层和卷积层之前添加了2个1024维的全连接层。
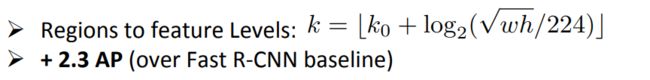

实验结果如表Table2,这里是测试Fast R-CNN的检测效果,所以proposal是固定的(采用Table1(c)的做法)。与Table1的比较类似,(a)(b)(c)的对比证明在基于区域的目标卷积问题中,特征金字塔比单尺度特征更有效。(c)(f)的差距很小,作者认为原因是ROI pooling对于region的尺度并不敏感。因此并不能一概认为(f)这种特征融合的方式不好。

将FPN用于Faster RCNN的实验结果如下表Table3。

下表Table4是和近几年在COCO比赛上排名靠前的算法的对比。注意到本文算法在小物体检测上的提升是比较明显的。
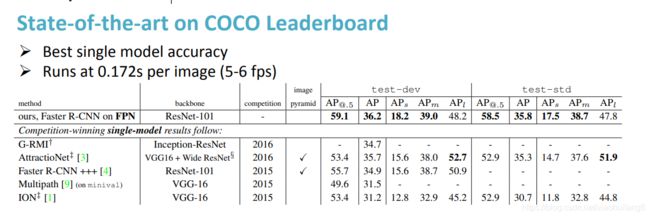
另外作者强调这些实验并没有采用其他的提升方法(比如增加数据集,迭代回归,hard negative mining)
原文链接:https://arxiv.org/abs/1612.03144v2
https://vision.cornell.edu/se3/wp-content/uploads/2017/07/fpn-poster.pdf
参考博客:https://blog.csdn.net/baidu_30594023/article/details/82623623
https://blog.csdn.net/jesse_mx/article/details/54588085