Linux块设备驱动(四)————块设备的数据结构与相关操作及I/O调度器
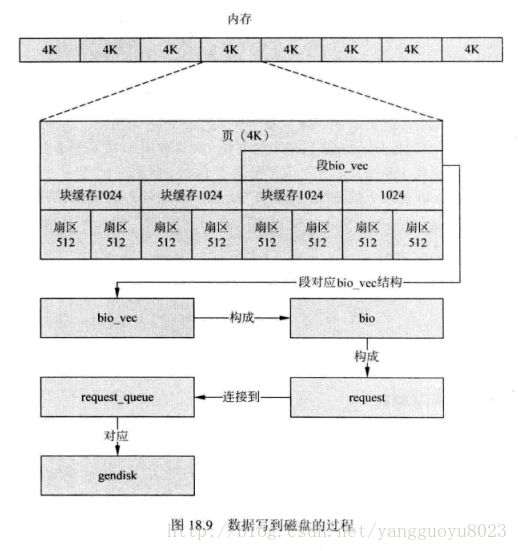
0、数据从内存到磁盘的过程
内存是一个线性的结构,Linux系统将内存分为页。一页最大可以是64KB,但是目前主流的系统页的大小都是4KB。每一页的数据会被先封装成一个段,用bio_vec表示。多个页会被封装成多个段,这些段被组成以一个bio_vec为元素的数组,这个数组用bio_io_vec表示。
bio_io_vec是bio中的一个指针。一个或者多个bio会组成一个request请求描述符。request将被连接到请求队列request_queue中,或者被合并到已经有的请求队列request_queue已有的request中。合并的条件是两个相邻的request请求所表示的扇区位置相邻。最后这个请求队列被处理,将数据写入磁盘。
1、块I/O请求(bio)
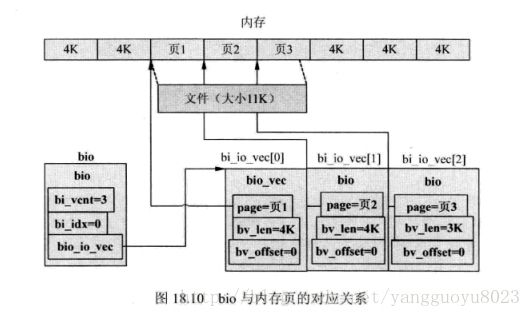
数据从内存到磁盘或者从磁盘到内存的过程,叫做I/O操作。内核使用一个核心数据结构来描述I/O操作。bio结构包含了一个段的数据(bio_io_vec),这个段的数据就是要操作的数据。
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
/*要传送的第一个扇区*/
sector_t bi_sector; /* device address in 512 byte
sectors */
/*下一个扇区*/
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev; /*bio对应的块设备*/
unsigned long bi_flags; /* status, command, etc */
unsigned long bi_rw; /* bottom bits READ/WRITE,
* top bits priority
*/
unsigned short bi_vcnt; /* how many bio_vec's */
unsigned short bi_idx; /* current index into bvl_vec */
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned short bi_phys_segments;
/* Number of segments after physical and DMA remapping
* hardware coalescing is performed.
*/
unsigned short bi_hw_segments;
unsigned int bi_size; /* residual I/O count */
/*
* To keep track of the max hw size, we account for the
* sizes of the first and last virtually mergeable segments
* in this bio
*/
unsigned int bi_hw_front_size;
unsigned int bi_hw_back_size;
unsigned int bi_max_vecs; /* max bvl_vecs we can hold */
struct bio_vec *bi_io_vec; /* the actual vec list */
bio_end_io_t *bi_end_io;
atomic_t bi_cnt; /* pin count */
void *bi_private;
bio_destructor_t *bi_destructor; /* destructor */
};
与bio相关的宏
/*于获取目前的页指针*/
bio_page(bio)
/*用于获取目前的页的偏移*/
bio_offset(bio)
bio_cur_sectors(bio) 2、请求结构(request)
几个连续的页面会组成一个bio结构,几个相邻的bio结构就会组成一个请求结构(request)。这样就不需要大幅度移动磁头了,节省了I/O操作的时间。
/*
* try to put the fields that are referenced together in the same cacheline
*/
/*请求结构request*/
struct request {
struct list_head queuelist; /*请求队列request_queue链表*/
struct list_head donelist;
request_queue_t *q;
unsigned int cmd_flags;
enum rq_cmd_type_bits cmd_type;
/* Maintain bio traversal state for part by part I/O submission.
* hard_* are block layer internals, no driver should touch them!
*/
/*要传送的第一个扇区号*/
sector_t sector; /* next sector to submit */
/*要传送的下一个扇区*/
sector_t hard_sector; /* next sector to complete */
unsigned long nr_sectors; /* no. of sectors left to submit */
unsigned long hard_nr_sectors; /* no. of sectors left to complete */
/* no. of sectors left to submit in the current segment */
unsigned int current_nr_sectors;
/* no. of sectors left to complete in the current segment */
unsigned int hard_cur_sectors;
struct bio *bio; /*指向第一个未完成的bio结构域*/
struct bio *biotail;/*请求链表中最后一个bio*/
struct hlist_node hash; /* merge hash */
/*
* The rb_node is only used inside the io scheduler, requests
* are pruned when moved to the dispatch queue. So let the
* completion_data share space with the rb_node.
*/
union {
struct rb_node rb_node; /* sort/lookup */
void *completion_data;
};
/*
* two pointers are available for the IO schedulers, if they need
* more they have to dynamically allocate it.
*/
void *elevator_private; /*指向I/O调度器的私有数据1*/
void *elevator_private2;/*指向I/O调度器的私有数据2*/
struct gendisk *rq_disk; /*指向请求所指向的磁盘*/
unsigned long start_time;
/* Number of scatter-gather DMA addr+len pairs after
* physical address coalescing is performed.
*/
unsigned short nr_phys_segments;/*请求的物理段数*/
/* Number of scatter-gather addr+len pairs after
* physical and DMA remapping hardware coalescing is performed.
* This is the number of scatter-gather entries the driver
* will actually have to deal with after DMA mapping is done.
*/
unsigned short nr_hw_segments;
unsigned short ioprio;
void *special;
char *buffer;
int tag;
int errors;
int ref_count;
/*
* when request is used as a packet command carrier
*/
unsigned int cmd_len;
unsigned char cmd[BLK_MAX_CDB];
unsigned int data_len;
unsigned int sense_len;
void *data;
void *sense;
unsigned int timeout;
int retries;
/*
* completion callback.
*/
rq_end_io_fn *end_io;
void *end_io_data;
};
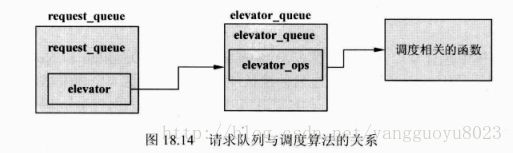
3、请求队列(request_queue)
请求队列主要是用来连接对同一块设备的多个request请求结构。还包含块设备所支持的请求类型信息、请求的个数、段的大小、硬件扇区数等与设备相关的信息。
/*内核将请求队列request_queue设计为一个双向链表,
链接request 请求*/
struct request_queue
{
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;/*连接到request结构,
表示待处理的请求*/
struct request *last_merge;
elevator_t *elevator; /*电梯调度算法的指针*/
/*
* the queue request freelist, one for reads and one for writes
*/
struct request_list rq;/*为分配请求描述符使用的数据结构*/
/*实现驱动程序处理请求的函数*/
request_fn_proc *request_fn;
/*将一个新的request请求插入请求队列中的方法*/
make_request_fn *make_request_fn;
prep_rq_fn *prep_rq_fn;
unplug_fn *unplug_fn;
merge_bvec_fn *merge_bvec_fn;
issue_flush_fn *issue_flush_fn;
prepare_flush_fn *prepare_flush_fn;
softirq_done_fn *softirq_done_fn;
/*
* Dispatch queue sorting
*/
sector_t end_sector;
struct request *boundary_rq;
/*
* Auto-unplugging state
*/
struct timer_list unplug_timer;
int unplug_thresh; /* After this many requests */
unsigned long unplug_delay; /* After this many jiffies */
struct work_struct unplug_work;
struct backing_dev_info backing_dev_info;
/*
* The queue owner gets to use this for whatever they like.
* ll_rw_blk doesn't touch it.
*/
void *queuedata;/*指向块设备驱动程序的私有数据的指针*/
/*
* queue needs bounce pages for pages above this limit
*/
unsigned long bounce_pfn;
gfp_t bounce_gfp;
/*
* various queue flags, see QUEUE_* below
*/
unsigned long queue_flags;
/*
* protects queue structures from reentrancy. ->__queue_lock should
* _never_ be used directly, it is queue private. always use
* ->queue_lock.
*/
spinlock_t __queue_lock;
spinlock_t *queue_lock;
/*
* queue kobject
*/
struct kobject kobj;
/*
* queue settings
*/
unsigned long nr_requests; /* Max # of requests */
unsigned int nr_congestion_on;
unsigned int nr_congestion_off;
unsigned int nr_batching;
unsigned int max_sectors;
unsigned int max_hw_sectors;
unsigned short max_phys_segments;
unsigned short max_hw_segments;
unsigned short hardsect_size;
unsigned int max_segment_size;
unsigned long seg_boundary_mask;
unsigned int dma_alignment;
struct blk_queue_tag *queue_tags;
unsigned int nr_sorted;
unsigned int in_flight;
/*
* sg stuff
*/
unsigned int sg_timeout;
unsigned int sg_reserved_size;
int node;
#ifdef CONFIG_BLK_DEV_IO_TRACE
struct blk_trace *blk_trace;
#endif
/*
* reserved for flush operations
*/
unsigned int ordered, next_ordered, ordseq;
int orderr, ordcolor;
struct request pre_flush_rq, bar_rq, post_flush_rq;
struct request *orig_bar_rq;
unsigned int bi_size;
struct mutex sysfs_lock;
};4、总结
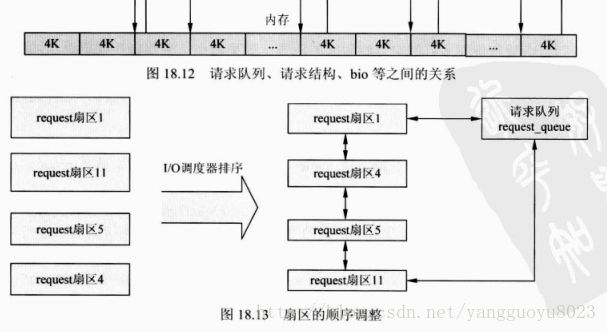
请求队列(request_queue)、请求结构(request)、bio等之间的关系

5、四种调度算法(电梯算法)
内核需要一种调度,使物理相邻的请求尽可能先后执行,这样就可以减少寻找扇区的时间,这种调度就叫做I/O调度。
预期算法(Anticipatory)、最后期限算法、CFQ完全公平队列算法、Noop无操作算法。