Faster-RCNN_TF实践及训练自己的数据集
1 代码位置,https://github.com/smallcorgi/Faster-RCNN_TF,具体依赖在该项目中明确有说明,这里在补充一下其它基本环境cuda 8.0、tensorflow-gpu==1.10.0、Python2.7
首先我的使用的机器只安装了cuda 9.0,后来又重新配置了一个cuda 8.0,这里的配置方式参见https://blog.csdn.net/yeler082/article/details/80943040
2 当代码准备好了,你需要运行一下测试demo.py文件,然后遇到文件下载问题。能问题不大,不能参见这个链接,可以在百度云下载,https://www.cnblogs.com/danpe/p/7840087.html,接着你就可以看到目标检测在给出的几张示例图片上的效果了。
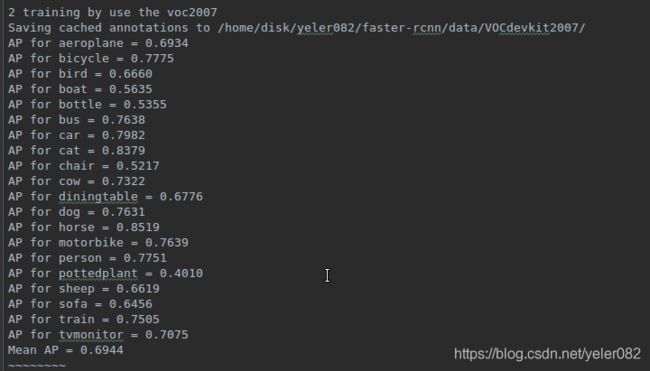
3 在pascal voc2007上做实验进行一遍训练,首先还是需要准备好数据集和预训练模型,具体准备方法按照github上的说明,下载npy预训练文件还是从上面的百度云下载。接着就可以执行训练脚本文件faster_rcnn_end2end.sh进行训练,训练结束,执行到test的时候会出现一直等待的问题,这里有解决办法https://www.cnblogs.com/danpe/p/7840087.html。下面是我重新训练的实验结果。
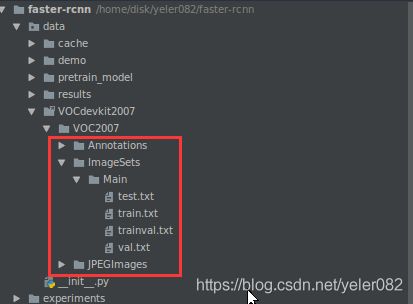
4 接下来就是训练自己的数据集,我们可以考虑两种办法,第一个就是将数据集生成voc的格式,第二种可以更改代码读取我们格式的数据集。由于我采用的数据集是自己生成的,相对来说第一种生成固定格式的更为简单,所以我采用第一种。关于定位需要的数据集内容如下,Annotations里面是位置框的标注信息;ImageSets里面的Main下有四个txt表示的是哪些文件参与做训练、验证及测试;JPEGImages里面存放所有训练和测试的图片(我用的图片格式是jpg)。
5 数据集准备好了,下一步就是修改源代码里面的类别信息,具体来讲就是对应好你的标签类别。
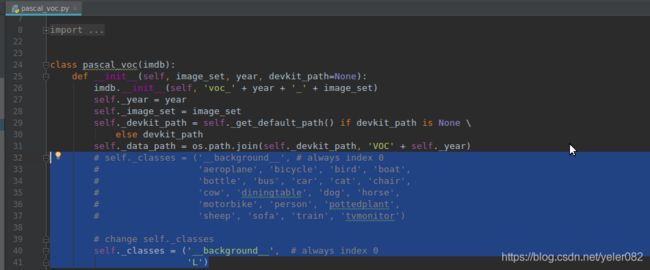
1. lib\datasets\pascal_voc.py中更改self._classes中的类别,添加自己的类名字“transform”,去掉你不要的标签类别
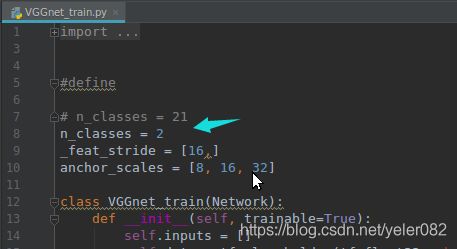
2 lib\networks中VGGnet_train.py和VGG_test.py中更改n_classes为自己的类的个数+1,这里我就用了2类
3. tools/demo.py中CLASSES的类别改为自己的类

接着执行脚本命令准备训练,注意:这里把标签转成小写,如果你的标签含有大写字母,可能会出现KeyError的错误,所以建议标签用小写字母。
我的训练标签里面有大写,就出现了这个错误,所以我将错误的代码做了如下修改,具体对应到pascal_voc.py文件。将被注释的一行换成下面的一行。

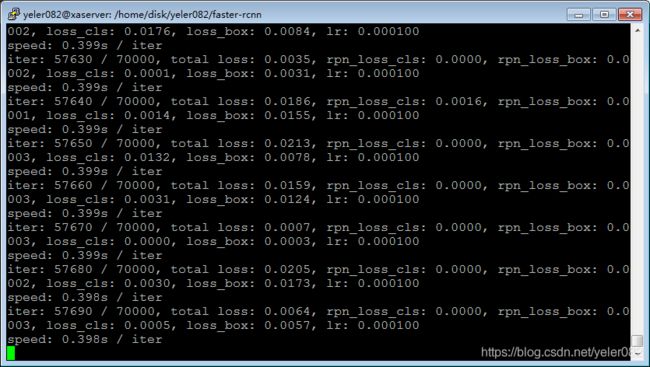
接着训练,能跑通,但是遇到了如下nan的运行时异常:
iter: 20 / 70000, total loss: nan, rpn_loss_cls: 0.6907, rpn_loss_box: nan, loss_cls: 0.0818, loss_box: 0.0000, lr: 0.001000
然后开始分析问题,由于我的左上角的坐标(x,y)可能是0,或者标定区域溢出图片范围;而faster-rcnn会对xmin,ymin,xmax,ymax进行减1操作,如果xmin为0,减去1后会变成65535。
接下来解决问题:
step 1:修改lib/datases/imdb.py,append_flipped_images()函数,修改如下,添加红框部分的内容

2、修改lib/datasets/pascal_voc.py,_load_pascal_annotation函数
将对Xmin,Ymin,Xmax,Ymax减一去掉,变为:

3、(可选,如果1和2可以解决问题,就没必要用3)修改lib/fast_rcnn/config.py,不使图片实现翻转,如下改为:
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = False
接着运行,就可以发现正常执行了。
训练完成以后,接着进行测试,遇到错误:
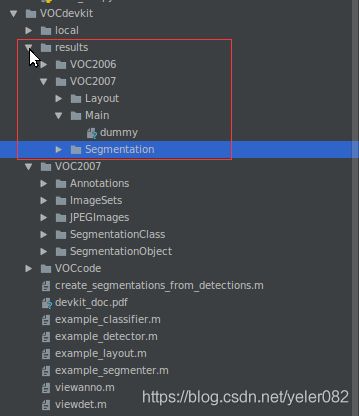
IOError: [Errno 2] No such file or directory: '/home/disk/yeler082/faster-rcnn/data/VOCdevkit2007/results/VOC2007/Main/comp4_6ce7e048-737f-4cfb-9dbf-490555a32f72_det_test_L.txt'
解决办法是将以前voc数据集中的results目录拷贝到自己生成数据集的对应位置。
接下来进行测试,发现一个单类别准确率还挺高的。
