云风协程库代码分析
一、什么是协程
协程,英文叫做 Coroutine,又称微线程、纤程,协程是一种用户态的轻量级线程。简单地说,协程就是在用户态对线程的模拟,我们都知道线程的调度是由操作系统内核完成的,而协程的调度是由用户代码完成的。
相比线程,协程有如下优势
- 协程切换在用户态完成,不需要进入内核态,没有线程切换的开销,效率更高
- 多个协程是在同一个线程中运行的,不存在多线程环境下的写变量冲突,因此不需要多线程的锁机制,执行效率高
当然,有优点就有缺点
- 多个协程在同一个线程中运行,如果不结合多线程就无法充分利用多核处理器的性能
二、云风协程库实现
2.1 基本功能
一个协程库需要对用户提供的最基本的三个功能是
- coroutine_new,创建一个协程
- coroutine_resume,唤醒一个协程
- coroutine_yield,挂起一个协程
我们都知道,操作系统内核在切换线程时,需要保存以及切换线程的上下文。同样,协程库在切换协程时,也需要保存以及切换协程的上下文。
切换上下文,听起来很麻烦,好在ucontext.h头文件提供了对上下文进行操作的函数,使得我们不必通过汇编代码来操作上下文。
2.2 ucontext
云风的协程库用到了ucontext中的以下四个函数
- 保存当前运行程序的上下文到ucp
#include typedef struct ucontext {
struct ucontext* uc_link;
sigset_t uc_sigmask;
stack_t uc_stack;
mcontext_t uc_mcontext;
...
} ucontext_t;
- 切换当前程序的上下文为ucp
#include - 保存当前上下文到oucp,并且换上下文为ucp
#include - 修改ucp指向的上下文的程序入口为func
#include - 上面这四个函数的源码清晰请看context源码分析,当然,就算不完全搞懂context的源码,也能看懂云风的协程库
2.3 协程和调度器的数据结构
- 协程的数据结构
struct coroutine {
coroutine_func func; // 函数指针,指向协程运行的函数
void *ud; // func的函数参数
ucontext_t ctx; // 协程的上下文
struct schedule * sch; // 协程所属的调度器
ptrdiff_t cap; // 协程的私有栈的空间大小
ptrdiff_t size; // 协程的私有栈的已用空间
int status; // 协程状态,可取值为COROUTINE_DEAD、COROUTINE_READY、COROUTINE_RUNNING、COROUTINE_SUSPEND
char *stack; // 协程的私有栈
};
- 调度器的数据结构
struct schedule {
char stack[STACK_SIZE]; // 协程的公有栈
ucontext_t main; // 调度器的上下文
int nco; // 调度器管理着多少个状态不为COROUTINE_DEAD的协程
int cap; // co数组的大小
int running; // 正在运行的协程的ID
struct coroutine **co; // 保存指向所有协程的指针的一维数组
};
- 上面两个数据结构中比较令人困惑的是每个协程都有自己的私有栈,那为什么还需要在调度器中定义一个公有栈呢?
- 其实这样做是为了节省空间,我们并不知道每个协程会用到多大的栈空间,如果给每个协程分配得太大,在协程数量较多的时候会造成严重的内存空间浪费;如果分配得太小,又会导致栈溢出
- 因此,在调度器中定义一个足够大的公有栈空间,所有协程都在这个公有栈上运行,当挂起协程时,保存当前的公有栈内容到协程的私有栈;唤醒协程时,把协程私有栈保存的内容复制到公有栈。这样做的话,协程的私有栈的大小就可以是动态,即是说,在挂起协程时,如果私有栈的大小不足以保存当前公有栈的内容,就重新分配一个更大的私有栈
- 这样就能给每个协程分配刚好满足需求的空间,就算开很多协程也不会造成大量的内存浪费
2.4 resume
void
coroutine_resume(struct schedule * S, int id) {
assert(S->running == -1);
assert(id >=0 && id < S->cap);
struct coroutine *C = S->co[id];
if (C == NULL)
return;
int status = C->status;
switch(status) {
case COROUTINE_READY:
getcontext(&C->ctx);
C->ctx.uc_stack.ss_sp = S->stack;
C->ctx.uc_stack.ss_size = STACK_SIZE;
C->ctx.uc_link = &S->main;
S->running = id;
C->status = COROUTINE_RUNNING;
uintptr_t ptr = (uintptr_t)S;
makecontext(&C->ctx, (void (*)(void)) mainfunc, 2, (uint32_t)ptr, (uint32_t)(ptr>>32));
swapcontext(&S->main, &C->ctx);
break;
case COROUTINE_SUSPEND:
memcpy(S->stack + STACK_SIZE - C->size, C->stack, C->size);
S->running = id;
C->status = COROUTINE_RUNNING;
swapcontext(&S->main, &C->ctx);
break;
default:
assert(0);
}
}
- 对于协程唤醒,分两种情况处理
- 如果协程还没有被运行过,即case COROUTINE_READY,就要先初始化协程的上下文,包含如下操作
- 设置栈指针,也就是sp了,学过汇编的小伙伴应该都知道
- 设置协程结束时,需要切换到S -> main上下文
- 设置协程的入口函数,我们看到是mainfunc,mainfunc函数中调用了C -> func,即用户注册的协程入口函数,源码如下
static void
mainfunc(uint32_t low32, uint32_t hi32) {
uintptr_t ptr = (uintptr_t)low32 | ((uintptr_t)hi32 << 32);
struct schedule *S = (struct schedule *)ptr;
int id = S->running;
struct coroutine *C = S->co[id];
C->func(S,C->ud);
_co_delete(C);
S->co[id] = NULL;
--S->nco;
S->running = -1;
}
- 如果协程已经被运行过了,即case COROUTINE_SUSPEND,只需要把私有栈复制到公有栈,再切换上下文就可以了
2.5 yield
- yield的实现很简单,保存当前公有栈的内容到私有栈,再切换上下文即可
void
coroutine_yield(struct schedule * S) {
int id = S->running;
assert(id >= 0);
struct coroutine * C = S->co[id];
assert((char *)&C > S->stack);
_save_stack(C,S->stack + STACK_SIZE);
C->status = COROUTINE_SUSPEND;
S->running = -1;
swapcontext(&C->ctx , &S->main);
}
- 其中_save_stack函数的实现比较特别,源码如下
static void
_save_stack(struct coroutine *C, char *top) {
char dummy = 0;
assert(top - &dummy <= STACK_SIZE);
if (C->cap < top - &dummy) {
free(C->stack);
C->cap = top-&dummy;
C->stack = malloc(C->cap);
}
C->size = top - &dummy;
memcpy(C->stack, &dummy, C->size);
}
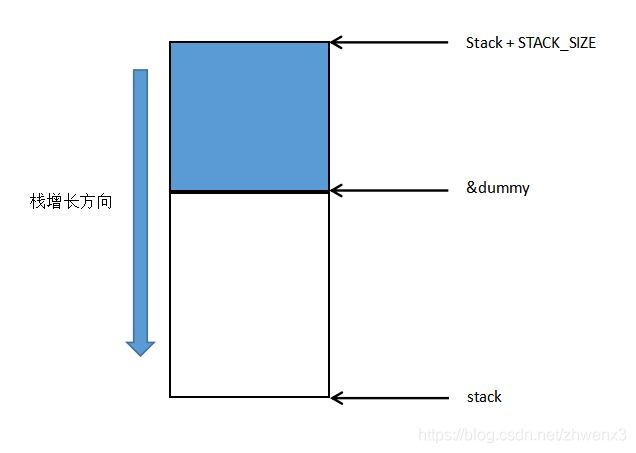
- 我们要复制公有栈的内容到私有栈,就必须得到当前的栈指针sp指向位置,不然就会复制了无用的内容
- 而_save_stack通过定义一个局部变量dummy得到当前sp的指向位置,这样做的原理是局部变量是保存在栈上的,而栈又是从高地址往低地址增长的,那么dummy的位置到S -> stack + STACK_SIZE即是我们需要保存的内容,图解如下
三、代码链接
云风协程库
我把云风协程库改成了C++版本,可读性更强,后续还会添加调度策略,如分时间片调度等