MySQL的存储过程原来还可以这样玩?(还不收藏)

什么是存储过程,存储过程能干吗?本篇博客给带大家学习下存储过程,并进行实战操作。(建议收藏)
一、什么是存储过程?
MySQL5.0版本开始支持的存储过程。
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
二、存储过程优缺点
2.1 优点
- 存储过程可封装,并隐藏复杂的商业逻辑。
- 存储过程可以回传值,并可以接受参数。
- 存储过程无法使用
- 存储过程无法使用select指定来运行,因为他是子程序,与查表,数据表或函数定义不同。
- 存储过程可以用在数据校验,强制实行商业逻辑等。
2.2 缺点
- 存储过程,往往定制化特定数据库上,因为支持的编程语言不同。当切换到其他厂商的数据系统时,需要重写原有的存储过程。
- 存储过程的性能调校撰写,受限于各种数据库系统。
三、存储过程有哪些特性
- 有输入输出参数,可以声明变量,有if/else, case,while等控制语句,通过编写存储过程,可以实现复杂的逻辑功能。
- 函数的普遍特性:模块化,封装,代码复用。
- 速度快,只有首次执行需经过编译和优化步骤,后续被调用可以直接执行,省去以上步骤。
四、实战操作
生成千万级数据量
实现思路:首先我们创建2张表一张表是存储真正的数据,另一种表创建内存表用来临时存储数据。我们使用存储过程效率会非常高。
4.1 创建内存表与普通表
#创建普通表
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT primary key comment '主键id',
`user_id` varchar(36) NOT NULL comment '用户id',
`user_name` varchar(30) NOT NULL comment '用户名称',
`phone` varchar(20) NOT NULL comment '手机号码',
`lan_id` int(9) NOT NULL comment '本地网',
`region_id` int(9) NOT NULL comment '区域',
`create_time` datetime NOT NULL comment '创建时间',
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
#创建内存表
CREATE TABLE `user_memory` (
`id` int(11) NOT NULL PRIMARY KEY AUTO_INCREMENT comment '主键id',
`user_id` varchar(36) NOT NULL comment '用户id',
`user_name` varchar(30) NOT NULL comment '用户名称',
`phone` varchar(20) NOT NULL comment '手机号码',
`lan_id` int(9) NOT NULL comment '本地网',
`region_id` int(9) NOT NULL comment '区域',
`create_time` datetime NOT NULL comment '创建时间',
KEY `idx_user_id` (`user_id`)
) ENGINE=MEMORY DEFAULT CHARSET=utf8mb4;
4.2 创建存储过程
4.2.1 创建生成N个随机数函数
#生成N个随机数字
DELIMITER $$
CREATE FUNCTION randNumber(N int) RETURNS VARCHAR(255)
begin
# 定义一个默认获取的值0-9
declare chars_str varchar(20) default '0123456789';
#将随机获取后得值保存在 return_str
DECLARE return_str varchar(255) DEFAULT '';
# 定义一个变量用来判断循环的参次数
DECLARE i INT DEFAULT 0;
WHILE i < n
DO
# 使用随机函数将 chars_str随机获取一个数字进行累加
SET return_str = concat(return_str, substring(chars_str, FLOOR(1 + RAND() * 10), 1));
#变量加1
SET i = i + 1;
END WHILE;
#最终结果返回
RETURN return_str;
END $$
DELIMITER;
4.2.2 生成手机号码
#生成随机手机号码
DELIMITER $$
CREATE FUNCTION genePhone() RETURNS varchar(20)
BEGIN
# 定义一个变量用来保存
DECLARE head char(3);
#定义一个变量用来保存最后生成的手机号
DECLARE phone varchar(20);
#定义一个变量用来存储常用的手机号开头
DECLARE bodys varchar(100) default "130 131 132 133 134 135 136 137 138 139 186 187 189 151 157";
#定义一个变量用来存储开始截取的手机开头
DECLARE starts int;
#随机获取一个手机号开头索引
SET starts = 1 + floor(rand() * 15) * 4;
#使用substring截取手机开头
SET head = trim(substring(bodys, starts, 3));
#将head与刚刚定义的存储过程进行拼接将最终的结果发值给phone
SET phone = trim(concat(head, randNumber(8)));
#数据返回
RETURN phone;
END $$
DELIMITER ;
4.2.3 生成随机的字符串
#创建随机字符串和随机时间的函数
DELIMITER $$
CREATE FUNCTION randString(N INT) RETURNS varchar(255) CHARSET utf8mb4
DETERMINISTIC
BEGIN
#定义一个字符串用来存储常用的字符与字母与数字
DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789!@#$%^&*()_+}{":?<,./>?;
#定义一个字符串将要返回的字符串
DECLARE return_str varchar(255) DEFAULT '' ;
#定义一个用来保存每个循环的次数
DECLARE i INT DEFAULT 0;
WHILE i < n DO
#随机从chars_str 获取一个字符串追加到return_str
SET return_str = concat(return_str, substring(chars_str, FLOOR(1 + RAND() * 79), 1));
SET i = i + 1;
END WHILE;
#最终结果返回
RETURN return_str;
END$$
DELIMITER;
4.2.4 向内存表中插入N条数据
# 创建插入内存表数据存储过程 入参N是多少就插入多少条数据
DELIMITER $$
CREATE PROCEDURE `add_user_memory`(IN N int)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i <= n) DO
INSERT INTO user_memory (user_id, user_name, phone, lan_id,region_id, create_time) VALUES (uuid(), randString(20), genePhone(), FLOOR(RAND() * 1000), FLOOR(RAND() * 100), NOW());
SET i = i + 1;
END WHILE;
END $$
DELIMITER ;
#循环从内存表获取数据插入普通表
#参数描述 n表示循环调用几次;count表示每次插入内存表和普通表的数据量
DELIMITER $$
CREATE PROCEDURE `add_user_memory_to_outside`(IN n int, IN count int)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i <= n) DO
CALL add_user_memory(count);
INSERT INTO user SELECT * FROM test_user_memory;
delete from ser_memory;
SET i = i + 1;
END WHILE;
END $$
DELIMITER ;
4.3 插入数据进行测试
#先调用存储过程往内存表插入一万条数据,然后再把内存表的一万条数据插入普通表
CALL add_user_memory(10000);
#一次性把内存表的数据插入到普通表,这个过程是很快的
INSERT INTO user SELECT * FROM user_memory;
#清空内存表数据
delete from user_memory;
select count(1) from user
#10000
#使用 add_user_memory_to_outside 生成千万数据量
call add_user_memory_to_outside(1000,10000)
#10010000
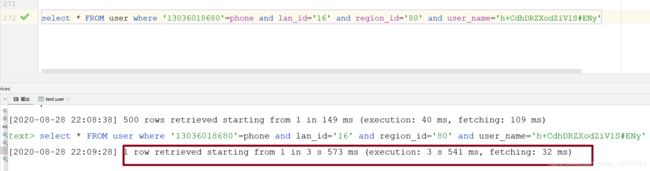
总结:本篇博客给大家讲解了什么是存储过程及他能干什么,如果MySQL中存储了大量数据的的话我们根据条件进行查询效率是非常慢的。在千万级数据量下我们查询一张条查询数据就需要3秒多的时间,往往在企业中查询一条数据需要好几秒的时间肯定是不行的,下一篇博客给大家讲解下如何让一条SQL语句在0.0几毫秒内查询到我们想要的数据。