Python数据挖掘处理完整项目及详细解释
对通话、短信以及上网记录的数据来预测风险用户
本文代码全部采用jupyter运行
先导入相关的包
# -*- coding: UTF-8 -*-
import pandas as pd
import numpy as np
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics, model_selection
from sklearn.model_selection import train_test_split
处理电话、短信以及上网记录的训练数据
uid_train = pd.read_csv('./new_data/train/uid_train.txt',sep='\t')
voice_train = pd.read_csv('./new_data/train/voice_train.txt',sep='\t',dtype={'start_time':np.str,'end_time':np.str})
sms_train = pd.read_csv('./new_data/train/sms_train.txt',sep='\t',dtype={'start_time':str})
wa_train = pd.read_csv('./new_data/train/wa_train.txt',sep='\t',dtype={'date':np.str})
处理电话、短信以及上网记录的测试数据
voice_test = pd.read_csv('./new_data/test/voice_test.txt',sep='\t', dtype={'start_time':np.str,'end_time':np.str})
sms_test = pd.read_csv('./new_data/test/sms_test.txt',sep='\t',dtype={'start_time':np.str})
wa_test = pd.read_csv('./new_data/test/wa_test.txt',sep='\t',dtype={'date':np.str})
合并电话、短信以及上网记录的训练数据和测试数据
uid_test = pd.read_csv('./new_data/test/uid_test.txt',sep='\t')
voice = pd.concat([voice_train,voice_test],axis=0)
sms = pd.concat([sms_train,sms_test],axis=0)
wa = pd.concat([wa_train,wa_test],axis=0)
数据去重。inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。
voice.drop_duplicates(inplace=True)
sms.drop_duplicates(inplace=True)
wa.drop_duplicates(inplace=True)
#输出查看结果
voice,sms,wa
输出的其中一部分结果


===================================================================
对用户短信记录进行特征工程处理
选取不同值来统计不同号码的主叫被叫数量,unstack将行数据转换为列数据,add_prefix新加行标签的前缀,reset_index重置索引
sms_head_0_count =sms.groupby(['vid'])['opp_head'].\
agg({'0': lambda x: np.sum(x.values == 0)}).add_prefix('sms_opp_head_').reset_index().fillna(0)
sms_head_0_count['sms_head_0_count_mean'] = \
sms_head_0_count.sms_opp_head_0 - np.mean(sms_head_0_count.sms_opp_head_0)
sms = sms[sms.opp_head != 0]
# 各用户所发送\接收短信号码统计
sms_in_out_unique = sms.groupby(['vid','in_out'])['opp_num'].\
nunique().unstack().add_prefix('sms_in_out_unique_').reset_index().fillna(0)
# 各个用户所接收不同短信号码的数量与其均值的差值
sms_in_out_unique['sms_in_out_unique-mean'] = \
sms_in_out_unique.sms_in_out_unique_1 - np.mean(sms_in_out_unique.sms_in_out_unique_1)
# 各个用户接收\发送不同的短信号码统计
sms_opp_num = sms.groupby(['vid'])['opp_num'].\
agg({'unique_count': lambda x: len(pd.unique(x)),'count':'count'}).add_prefix('sms_opp_num_').reset_index().fillna(0)
# 各个用于接收\发送短信号码与其均值的差值
sms_opp_num['sms_count-mean'] = \
(sms_opp_num.sms_opp_num_count - np.mean(sms_opp_num.sms_opp_num_count)).astype('float')
# 各个用户所接收\发送不同短信号码数量与均值的差值
sms_opp_num['sms_unique_count-mean'] = \
(sms_opp_num.sms_opp_num_unique_count - np.mean(sms_opp_num.sms_opp_num_unique_count)).astype('float')
# 各个用户重复接收\发送某些短信号码的数量
sms_opp_num['sms_opp_num_diff']=\
sms_opp_num.sms_opp_num_count - sms_opp_num.sms_opp_num_unique_count
# 各个用户不同的对号码前n位数量统计
sms_opp_head=sms.groupby(['vid'])['opp_head'].\
agg({'unique_count': lambda x: len(pd.unique(x))}).add_prefix('sms_opp_head_').reset_index().fillna(0)
print(sms_opp_head)
# 删除异常值
sms.opp_len = sms.opp_len.map(lambda x: -1 if (x==3 or x==6 or x>15) else x)
# 按照用户和对号码长度分类,计算不同用户不同长度号码下数量
sms_opp_len = sms.groupby(['vid','opp_len'])['vid'].\
count().unstack().add_prefix('sms_opp_len_').reset_index().fillna(0)
# 按照用户分类,统计不同用户对端号码数量
sms_opp_len_type = sms.groupby(['vid'])['opp_len'].\
agg({'unique_count': lambda x: len(pd.unique(x))}).add_prefix('sms_opp_len_type_').reset_index().fillna(0)
# 短信发送时间早晚分成3类
sms['sms_start_hour_time'] = \
(sms.start_time.str.slice(2, 4).astype('int') / 3).astype('int')
# 按照用户、发送时间段分类,并统计不同用户不同时间发送数量
sms_start_time = sms.groupby(['vid','sms_start_hour_time'])['vid'].\
count().unstack().add_prefix('sms_start_time_').reset_index().fillna(0)
# 对端号码100数量统计
sms_opp_head_100_count =sms.groupby(['vid'])['opp_head'].\
agg({'100': lambda x: np.sum(x.values == 1)}).add_prefix('sms_opp_head_').reset_index().fillna(0)
# 对端号码100与均值之差
sms_opp_head_100_count['sms_opp_head_100_count-mean'] = \
sms_opp_head_100_count.sms_opp_head_100 - np.mean(sms_opp_head_100_count.sms_opp_head_100)
# 对端号码非100数量
sms_opp_head_100_count['sms_opp_head_not_100_count'] = \
sms_opp_num.sms_opp_num_count - sms_opp_head_100_count.sms_opp_head_100
sms_opp_head_100_count['sms_opp_head_not_100_count-mean'] = \
sms_opp_head_100_count.sms_opp_head_not_100_count - np.mean(sms_opp_head_100_count.sms_opp_head_not_100_count)
# 发送日期分段
sms['sms_date'] = ((sms.start_time.str.slice(0, 2).astype('int')-1) / 5).astype('int')
# 不同用户不同发送日期段数量统计
sms_date_count = sms.groupby(['vid', 'sms_date'])['vid'].\
count().unstack().add_prefix('sms_date_').reset_index().fillna(0)
# 不同用户不同发送日期段数量统计
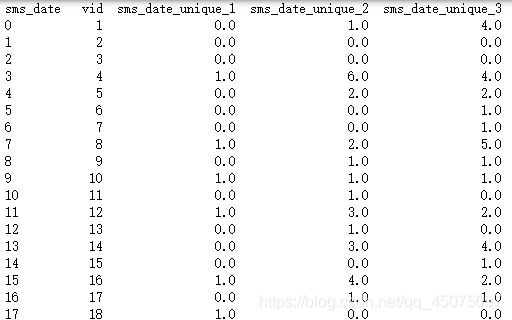
sms_date_count_unique = sms.groupby(['vid', 'sms_date'])['opp_num'].\
nunique().unstack().add_prefix('sms_date_unique_').reset_index().fillna(0)
print(sms_date_count_unique)
一部分输出打印的结果

===================================================================
对用户通话记录进行特征工程处理
#nunique输出个数,unique输出值
voice_in_out_unique = voice.groupby(['vid','in_out'])['opp_num'].\
nunique().unstack().add_prefix('voice_in_out_unique_').reset_index().fillna(0)
print("voice_in_out_count:" ,voice_in_out_unique.head(10))
#统计被叫号码和全部被叫号码平均值(mean)的差
voice_in_out_unique['voice_in_out_unique-mean']=\
voice_in_out_unique.voice_in_out_unique_1 - np.mean(voice_in_out_unique.voice_in_out_unique_1)
print("voice_in_out_mean:",voice_in_out_unique.head(10))
#统计统一用户的条件下,被叫数量次数和主叫数量次数的差值
voice_in_out_unique['voice_in_out_unique_diff'] = \
voice_in_out_unique.voice_in_out_unique_1 - voice_in_out_unique.voice_in_out_unique_0
print("diff:",voice_in_out_unique.head(10))
#按列操作(agg)统计不同号码主叫和被叫的数量以及总共播出和接入电话号码数量 在opp_num这列通过unique对电话取唯一值和不取唯一值做比较
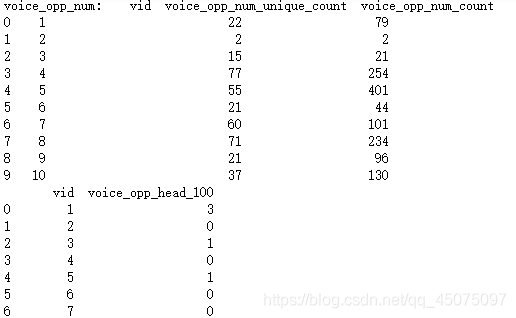
voice_opp_num = voice.groupby(['vid'])['opp_num'].\
agg({'unique_count': lambda x: len(pd.unique(x)),'count':'count'}).add_prefix('voice_opp_num_').reset_index().fillna(0)
print("voice_opp_num:",voice_opp_num.head(10))
#得到电话号码开头为100的数量
voice_opp_head_100_count = voice.groupby(['vid'])['opp_head'].\
agg({'100': lambda x: np.sum(x.values == 1)}).add_prefix('voice_opp_head_').reset_index().fillna(0)
print(voice_opp_head_100_count)
#统计号码开头为100和全部号码开头为100的平均值(mean)的差
voice_opp_head_100_count['voice_head_100_count-mean'] = \
voice_opp_head_100_count.voice_opp_head_100 - np.mean(voice_opp_head_100_count.voice_opp_head_100)
# 统计100开头 并按照主叫被叫分类
voice_in_out_head_100 = voice.groupby(['vid','in_out'])['opp_head'].\
agg({'100': lambda x: np.sum(x.values == 1)}).unstack().add_prefix('voice_in_out_head_').reset_index().fillna(0)
print("voice_head_100:",voice_in_out_head_100.head(10))
# 不是100的开头的电话号码数量
voice_opp_head_100_count['voice_head_of_not_100'] = \
voice_opp_num.voice_opp_num_count - voice_opp_head_100_count.voice_opp_head_100
# 不同电话号码开头数量
voice_opp_head = voice.groupby(['vid'])['opp_head'].\
agg({'unique_count': lambda x: len(pd.unique(x))}).add_prefix('voice_opp_head_').reset_index().fillna(0)
voice.call_type = voice.call_type.map(lambda x: 0 if (x > 3) else x)
# 每个用户拨打电话类型统计
voice_call_type = voice.groupby(['vid','call_type'])['vid'].\
count().unstack().add_prefix('voice_call_type_').reset_index()
print("voice_call_type:",voice_call_type.head(10))
# 每个用户拨打不同类型号码的数量
voice_call_type_unique = voice.groupby(['vid','call_type'])['opp_num'].\
nunique().unstack().add_prefix('voice_call_type_unique_').reset_index()
print(":voice_call_type_count:",voice_call_type_unique.head(10))
部分输出的结果


===================================================================
对用户网站、app记录数据进行特征工程处理
wa_name = wa.groupby(['vid'])['net_name'].agg({'unique_count': lambda x: len(pd.unique(x)),'count':'count'}).add_prefix('net_name_').reset_index().fillna(0)
wa_name['net_name_count-unique'] = wa_name.net_name_count - wa_name.net_name_unique_count
wa_name['net_name_count-mean'] = wa_name.net_name_count - np.mean(wa_name.net_name_count)
wa_name['net_name_unique_count-mean'] = wa_name.net_name_unique_count - np.mean(wa_name.net_name_unique_count)
wa['net_name_len'] = wa.net_name.str.len() / 4
wa.net_name_len = wa.net_name_len.map(lambda x: -1 if (x > 10) else x)
wa_name_len = wa.groupby(['vid', 'net_name_len'])['vid'].count().unstack().add_prefix('net_name_len_').reset_index().fillna(0)
visit_cnt = wa.groupby(['vid'])['vist_times'].agg(['std','max','median','mean','sum']).add_prefix('net_visit_times_').reset_index().fillna(0)
wa.visit_dura = wa.visit_time_long/60
visit_dura = wa.groupby(['vid'])['visit_time_long'].agg(['std','max','median','mean','sum']).add_prefix('net_visit_time_long_').reset_index().fillna(0)
wa.up_flow = wa.up_flow/1024
up_flow = wa.groupby(['vid'])['up_flow'].agg(['std','max','min','median','mean','sum']).add_prefix('net_up_flow_').reset_index().fillna(0)
wa.down_flos = wa.down_flos/1024
down_flow = wa.groupby(['vid'])['down_flos'].agg(['std','max','min','median','mean','sum']).add_prefix('net_down_flos_').reset_index().fillna(0)
wa_type = wa.groupby(['vid','watch_type'])['vid'].count().unstack().add_prefix('watch_type_').reset_index().fillna(0)
wa_type_unique = wa.groupby(['vid','watch_type'])['net_name'].nunique().unstack().add_prefix('watch_type_unique_').reset_index().fillna(0)
wa_date_up_flow = wa.groupby(['vid', 'date'])['up_flow'].agg(['std','max','min','median','mean','sum']).unstack().add_prefix('net_date_up_').reset_index().fillna(0)
wa_date_down_flow = wa.groupby(['vid', 'date'])['down_flos'].agg(['std','max','min','median','mean','sum']).unstack().add_prefix('net_down_flos_').reset_index().fillna(0)
wa_date_visit_cnt = wa.groupby(['vid', 'date'])['vist_times'].agg(['std','max','min','median','mean','sum']).unstack().add_prefix('net_date_vist_times_').reset_index().fillna(0)
wa_type_up_flow = wa.groupby(['vid', 'watch_type'])['up_flow'].agg(['std','max','min','median','mean','sum']).unstack().add_prefix('net_type_up_').reset_index().fillna(0)
wa_type_down_flow = wa.groupby(['vid', 'watch_type'])['down_flos'].agg(['std','max','min','median','mean','sum']).unstack().add_prefix('net_type_down_').reset_index().fillna(0)
wa_type_visit_cnt = wa.groupby(['vid', 'watch_type'])['vist_times'].agg(['std','max','min','median','mean','sum']).unstack().add_prefix('net_type_visit_cnt_').reset_index().fillna(0)
print(wa_type_visit_cnt)
部分输出的结果

===================================================================
训练数据
feature = [
voice_in_out, voice_in_out_unique,
voice_opp_num, voice_opp_head,
voice_opp_len, voice_opp_len_type, voice_call_type, voice_call_type_unique,
sms_opp_head_0_count,
sms_in_out, sms_in_out_unique,
sms_opp_num, sms_opp_head, sms_opp_len,sms_opp_len_type,
sms_start_time, sms_date_count,
wa_name,wa_name_len,
up_flow, down_flow, visit_dura, visit_cnt, wa_type,wa_type_unique
]
train_feature = uid_train
for feat in feature:
train_feature=pd.merge(train_feature, feat, how='left',on='vid').fillna(0)
test_feature = uid_test
for feat in feature:
test_feature=pd.merge(test_feature,feat,how='left',on='vid').fillna(0)
部分输出的结果

===================================================================
预测数据
import matplotlib.pyplot as plt
import seaborn as sns
import sys
dtrain = train_feature.drop(['vid','label'],axis=1)
dtrain_label = train_feature.label
dtest_vid = test_feature.vid
dtest = test_feature.drop(['vid','label' ],axis=1)
x_train, x_test, y_train, y_test = train_test_split(dtrain, dtrain_label, test_size=0.2, random_state=1)
model = XGBClassifier()
model.fit(x_train, y_train)
pre = model.predict_proba(x_test)
pre = pre[:,1]
fpr, tpr, th = metrics.roc_curve(y_test, pre)
auc = metrics.auc(fpr,tpr)
print("测试集的auc大小为")
print(auc)
pre_final = model.predict_proba(dtest)
print(pre_final[:,1])
with open('uid_test.txt','w') as f:
f.write('vid\tlabel\n')
for id, pre in zip(dtest_vid, pre_final[:,1]):
f.write(str(id)+'\t'+str(pre)+'\n')
部分输出结果

读取预测文件
uid_test = pd.read_csv('./uid_test.txt',sep='\t')
uid_test
部分输出结果
