通过源码来学习pandas中read_excel()函数的使用方法
本文参考了https://blog.csdn.net/xxd102401/article/details/100943179,https://blog.csdn.net/brucewong0516/article/details/79096633,如有侵权,可联系删除。
除了使用xlrd库或者xlwt库进行对excel表格的操作读与写,而且pandas库同样支持excel的操作;且pandas操作更加简介方便。
python : 3.7.6.final.0
pandas : 0.25.3
源码来截摘自于C:\Users\luoshixiang\AppData\Local\Programs\Python\Python37\Lib\site-packages\pandas\io\excel\_base.py
通过本文阅读源码自学,获得的将不仅仅是会使用一个函数@Appender(_read_excel_doc)
@deprecate_kwarg("skip_footer", "skipfooter")
def read_excel(
io,
sheet_name=0,
header=0,
names=None,
index_col=None,
usecols=None,
squeeze=False,
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skiprows=None,
nrows=None,
na_values=None,
keep_default_na=True,
verbose=False,
parse_dates=False,
date_parser=None,
thousands=None,
comment=None,
skip_footer=0,
skipfooter=0,
convert_float=True,
mangle_dupe_cols=True,
**kwds
):
for arg in ("sheet", "sheetname", "parse_cols"):
if arg in kwds:
raise TypeError(
"read_excel() got an unexpected keyword argument " "`{}`".format(arg)
)
if not isinstance(io, ExcelFile):
io = ExcelFile(io, engine=engine)
elif engine and engine != io.engine:
raise ValueError(
"Engine should not be specified when passing "
"an ExcelFile - ExcelFile already has the engine set"
)
return io.parse(
sheet_name=sheet_name,
header=header,
names=names,
index_col=index_col,
usecols=usecols,
squeeze=squeeze,
dtype=dtype,
converters=converters,
true_values=true_values,
false_values=false_values,
skiprows=skiprows,
nrows=nrows,
na_values=na_values,
keep_default_na=keep_default_na,
verbose=verbose,
parse_dates=parse_dates,
date_parser=date_parser,
thousands=thousands,
comment=comment,
skipfooter=skipfooter,
convert_float=convert_float,
mangle_dupe_cols=mangle_dupe_cols,
**kwds
)测试用数据
sheet1:
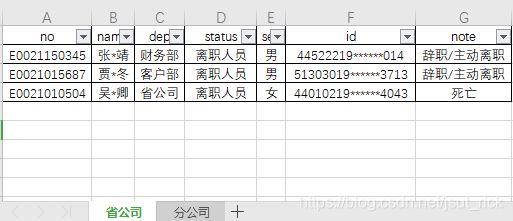
sheet2:

根据源码已有的文档对参数进行解释
io : excel文件路径,可以是URL,可用URL类型包括:http, ftp, s3和文件
>>> import pandas as pd
>>> file_path=r"C:/Users/luoshixiang/Desktop/data/jian.xlsx"
>>> jian=pd.read_excel(io=file_path) #这个会直接默认读取到这个Excel的第一个表单
>>> jian.head() #默认读取前5行的数据
no name dep status sex id note
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
1 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
2 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
sheetname : 可以是**str,int,list,或None,默认0,**字符是表示的是该表的名字,数字表示的是表的位置(从0开始),数字和字符是请求单个表格;列表形式的是请求多个表格.赋值为None是请求全部的表格
| 赋值 | 解释 |
| sheet_name = 0 (默认为0) | 第一张工作表作为DataFrame |
| sheet_name = 1 | 第二张工作表为DataFrame |
| sheet_name = “Sheet1” | 名字为"Sheet1"的表作为DataFrame |
| sheet_name = [0,1,“Sheet5”] | 第一张工作表,第二张工作表和名字为"Sheet5"的工作表作为字典结构的DataFrame |
| sheet_name = None | 所有的工作表作为字典结构的DataFrame |
>>> pd.read_excel(io=file_path,sheet_name=1)
no name dep status sex id note
0 E0021033660 杨*冲 福田分公司 离职人员 男 44510219******1217 辞职/主动离职
1 E0021033015 梁*颖 福田分公司 离职人员 男 44532119******0631 辞职/主动离职
2 E0021033220 朱*南 福田分公司 离职人员 女 23230219******762X 辞职/主动离职
3 E0021033459 周*奇 福田分公司 离职人员 女 42900119******722X 辞职/主动离职
4 E0021396505 李*锋 罗湖分公司 离职人员 男 34062119******1237 辞职/主动离职
5 E0021033139 林*妮 罗湖分公司 离职人员 女 44150219******2682 辞职/主动离职
6 E0021033093 刘*红 罗湖分公司 离职人员 女 44142119******0448 辞职/主动离职
7 E0021395102 王*莹 罗湖分公司 离职人员 女 22010219******1460 辞职/主动离职
8 E0021033338 周*霓 南山分公司 离职人员 女 44528119******444X 辞职/主动离职
>>> header:指定作为列名的行,默认0,即取第一行的值为列名。数据为列名行以下的数据;若数据不含列名,则设定 header = None
>>> pd.read_excel(io=file_path,sheet_name=0,header=0)
no name dep status sex id note
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
1 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
2 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
>>> pd.read_excel(io=file_path,sheet_name=0,header=1)
E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
0 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
1 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡names:指定列的名字,传入一个list数据,默认为None。如数据中不包含标题行,应使用header=None作为列名
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None)
no name dep status sex id note
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
1 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
2 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=['a','b','c','d','e','f','g'])
a b c d e f g
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
1 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
2 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡index_col : 指定列为索引列,默认None列(0索引)用作DataFrame的行标签
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,index_col=None)
no name dep status sex id note
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
1 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
2 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,index_col=0)
name dep status sex id note
no
E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,index_col=1)
no dep status sex id note
name
张*靖 E0021150345 财务部 离职人员 男 44522219******014 辞职/主动离职
贾*冬 E0021015687 客户部 离职人员 男 51303019******3713 辞职/主动离职
吴*卿 E0021010504 省公司 离职人员 女 44010219******4043 死亡usecols:int或list,默认为None
- 如果为None则解析所有列
- 如果为int则表示要解析的最后一列
- 如果为int列表则表示要解析的列号列表
- 如果字符串则表示以逗号分隔的Excel列字母和列范围列表(例如“A:E”或“A,C,E:F”)。范围包括双方。
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,usecols=[1,2])
name dep
0 张*靖 财务部
1 贾*冬 客户部
2 吴*卿 省公司squeeze : 默认为False,如果解析的数据只包含一列,则返回一个Series
dtype:列的类型名称或字典,默认为None。数据或列的数据类型。
例如{‘a’:np.float64,‘b’:np.int32}使用对象保存存储在Excel中的数据而不解释dtype。如果指定了转换器,则它们将应用于dtype转换的INSTEAD。
skiprows:省略指定行数的数据,从第一行开始
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,skiprows=0)
no name dep status sex id note
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
1 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
2 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,skiprows=1)
E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
0 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
1 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,skiprows=2)
E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
0 E0021010504 吴*卿 省公司 离职人员 女 44010219******4043 死亡
>>> skip_footer:省略从尾部数的行数据
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,skipfooter=1)
no name dep status sex id note
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
1 E0021015687 贾*冬 客户部 离职人员 男 51303019******3713 辞职/主动离职
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,skipfooter=2)
no name dep status sex id note
0 E0021150345 张*靖 财务部 离职人员 男 44522219******014 辞职/主动离职
nrows : int型,默认为None,解析0-所指定的行数
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,nrows=2)
no name dep status sex id note
0 E0021033660 杨*冲 福田分公司 离职人员 男 44510219******1217 辞职/主动离职
1 E0021033015 梁*颖 福田分公司 离职人员 男 44532119******0631 辞职/主动离职
>>> pd.read_excel(io=file_path,sheet_name=0,header=0,names=None,nrows=1)
no name dep status sex id note
0 E0021033660 杨*冲 福田分公司 离职人员 男 44510219******1217 辞职/主动离职
>>> na_values :添加字符作为NA/NaN
若是通过字典类型指定NA的值,那么默认替换为NaN。
skipfooter:省略指定行数的数据,从尾部数的行开始
总体而言,pandas库的pd.read_excel和pd.read_csv的参数比较类似,且相较xlrd库的读表操作更加简单,针对一般批量的数据处理最好选择pandas库操作。
ps:其他的参数暂时还没有使用到,以后再做补充。