一、前言
因为在做项目时候遇到了mybatis缓存的坑,所以全面学习了下mybaits的缓存知识,一来避免后面再次采坑,二来为其他童鞋提供前车之鉴。
二、Mybaits缓存作用
为了提高数据库查询性能,缓解数据查询压力,后面会具体看到一级是在sqlsession级别缓存了查询结果和二级缓存则是在namespace级别缓存了查询结果。
三、Mybaits一级缓存
3.1 问题示例
在做项目时候遇到一个问题,就是数据库里面有个任务表,单击页面上面设备测试时候,会触发一个事件,这个事件被定时钟轮询线程捕获后,修改任务的状态,而在单击设备测试的同时会有一个rpc请求去查看任务状态,这个rpc的bo层是个循环,循环查询任务状态。结果发现定时钟线程已经修改了任务状态,但是rpc的bo层循环查找的状态还是修改前面的,但是明明数据库里面状态已经修改了啊。经过断点发现,rpc的bo层循环查找的结果一直和第一次查找结果一样,好奇怪,为啥类,第一想法是不是事务隔离性问题啊,毕竟mysql默认配置的隔离水平是Repeated read,但是查看配置我用的mysql是Read Commited,那就郁闷了啊,想知道答案请看3.2
3.2一级缓存原理
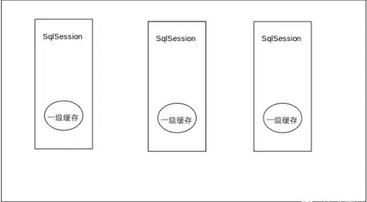
Mybatis的一级缓存是SqlSession级别的,我们知道每个mapper接口对应一个SqlSession(这样说应该不准确,应该是一个线程中一个mapper接口对应一个sqlsession),所以Mybatis的一级缓存在不同mapper之间是隔离,相互不影响的。另外在执行Add,Update,Del时候,会清空当前线程SqlSession的一级缓存避免脏读。默认情况下mybaits开启一级缓存。
Mybaits一级缓存结构图:
Java
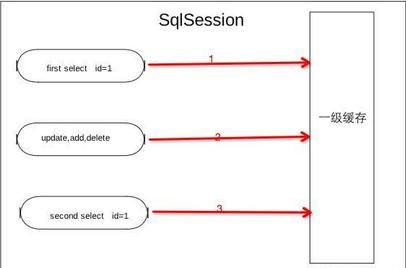
然后我们深入一个SqlSession看看它是怎么玩的?
Java
剧透下同一个mapper在第一次执行select时候会发现sqlsession缓存没有记录,会去数据库查找,然后把结果保存到缓存,第二次同等条件查询下,就会从缓存中查找到结果。另外为了避免脏读,每次执行更新新增删除时候会清空当前sqlsession缓存。
下面从代码时序图看下:
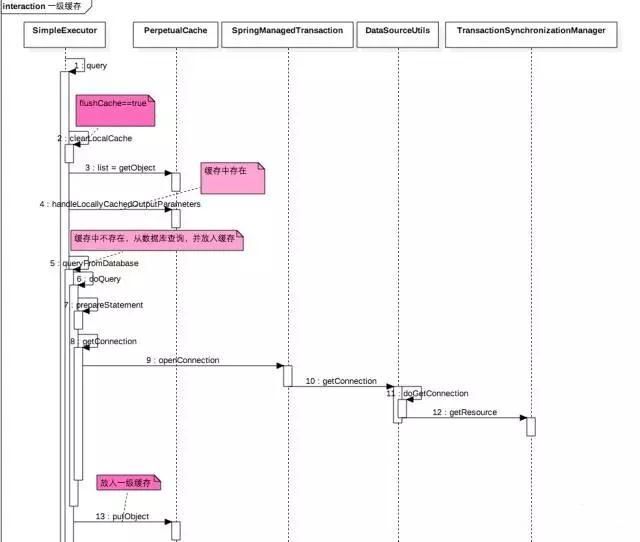
Java
代码为:
public List query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//根据配置是否刷新缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List list;
try {
queryStack++;
//从缓存获取结果
list = resultHandler == null ? (List) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//缓存中不存在,则在数据库中查询,查询后把结果放入缓存
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
} 由于内部insert,update,delete最终调用的都是update方法,所以看下update代码:
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//清空一级缓存
clearLocalCache();
return doUpdate(ms, parameter);
}由于默认情况下mybatis开启一级缓存,所以如果你需要每次查询都从数据库查询,可以在mapper.xml里面具体sql语句添加flushCache=”true”;
<select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.lang.Long" flushCache="true">
select
"Base_Column_List" />
from COMPANY
where ID = #{id,jdbcType=NUMERIC}
and is_deleted = 'n'
select> 3.1节的问题通过配置这个解决。
四、Mybatis二级缓存
4.1介绍
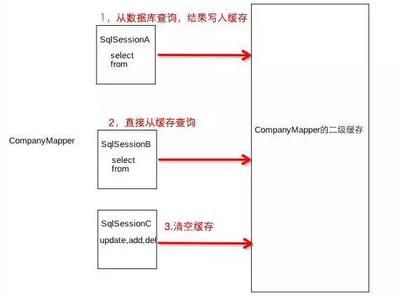
二级缓存是namespace级别的,这个namespace就是指mapper文件里面那个namepsace,同一个namespace下的搜寻语句共享一个二级缓存。那么二级缓存是怎么样的构造那,先上个图:
Java
4.2 原理
上CachingExecutor的查询代码如下:
public List query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
//如果配置了使用二级缓存,则从缓存中取
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List list = (List) tcm.getObject(cache, key);
if (list == null) {
//缓存找不到则代理给SimpleExecutor查找,
list = delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//没有设置二级缓存,则直接委托给SimpleExecutor查找
return delegate. query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
} 如果开启了二级缓存,则先从二级缓存中查找,查找不到则委托为SimpleExecutor查找,而它则会先从一级缓存中查找,查找不到则从数据库查找。
五、总结
mybaits的二级缓存一般不怎么使用,默认一级缓存是开启的,如果项目中遇到数据更新后查询出来的数据却没有改变,那么可以从数据隔离性和mybaits缓存方面查找问题所在。
Java学习资料获取(复制下段连接至浏览器即可)
data:text/html;charset=UTF-8;base64,5p625p6E5biI5a2m5Lmg6LWE5paZ5YWN6LS56aKG5Y+W6K+35Yqg5omj5omj5Y+35pivMTAxODkyNTc4MA==