【问题一】
复制slave报错1236,是较为常见的一种报错
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.
需要注意有多种场景都会导致1236错误,error code都是1236,但后面的错误描述会不同
【产生原因】
这个错误发生在slave的IO线程从master拉取日志时,发现gtid_next在master的binlog.index中第一个文件中不存在。
通常出现在新搭slave , 忘记关闭主库的binlog备份。
或者slave由于某些原因停止了一段时间,而这段时间master上的binlog被purge掉了,导致从库获取不到对应的binlog文件。
【保证数据一致性的修复步骤】
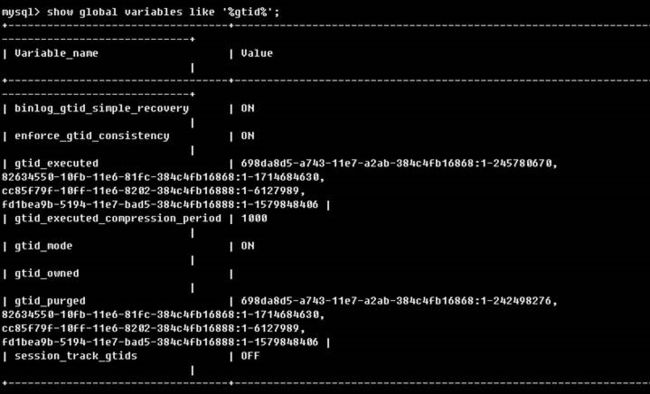
1、到对应的master上查询当前gtid_purged值,show global variables like '%gtid%'; 并记录下来

Variable_name: gtid_purged
Value: 698da8d5-a743-11e7-a2ab-384c4fb16868:1-245780670,
82634550-10fb-11e6-81fc-384c4fb16868:1-1714684630,
cc85f79f-10ff-11e6-8202-384c4fb16888:1-6127989,
fd1bea9b-5194-11e7-bad5-384c4fb16888:1-1579848406
2、在报错的slave上执行show global variables like '%gtid%';并将gtid_executed记录下来
Variable_name: gtid_executed
Value: 698da8d5-a743-11e7-a2ab-384c4fb16868:1-242405257,
82634550-10fb-11e6-81fc-384c4fb16868:1-1714684630,
cc85f79f-10ff-11e6-8202-384c4fb16888:1-6127989,
fd1bea9b-5194-11e7-bad5-384c4fb16888:1-1579848406
3、到binlog备份目录下找被pugre掉的包含 698da8d5-a743-11e7-a2ab-384c4fb16868:1-242405257的GTID的binlog文件,并从备份目录拷贝到当前slave服务器上的目录
4、在当前slave上执行还原脚本,直到还原到大于等于gtid_purged的位置,多还原没有问题,因为已经执行过的GTID,在salve的SQL线程重做时会跳过
mysqlbinlog -vvv /data/binlog/bin.file |mysql -u -p
如果出现报错,可以尝试导出SQL文件source执行
mysqlbinlog -vvv /data/binlog/bin.file > 1059.sql
source 1059.sql
5、start slave;
【不考虑数据一致性的修复步骤】
在某些特殊场景下,比如日志文件缺失,需要快速恢复,或是测试环境可以丢失一部分数据
1、master上执行show global variables like '%gtid_executed';并记录
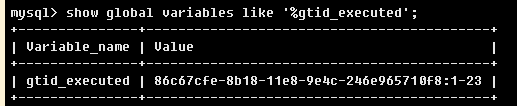
2、slave上一次依次执行,这种方法会丢失掉上次salve报错时 Executed_Gtid_Set的位置86c67cfe-8b18-11e8-9e4c-246e965710f8:1-16到新位置86c67cfe-8b18-11e8-9e4c-246e965710f8:1-23之间的,16-23集合的事务
stop slave;
reset master;
set global gtid_purged='86c67cfe-8b18-11e8-9e4c-246e965710f8:1-23';
start slave;
上述方法修复后,都建议用pt-table-checksum工具,检验主从数据的一致性。