P-CNN: Pose-based CNN Features for Action Recognition
2015ICCV
github :https://github.com/gcheron/P-CNN
project:http://www.di.ens.fr/willow/research/p-cnn/
原文:http://blog.csdn.net/zimenglan_sysu/article/details/49802769
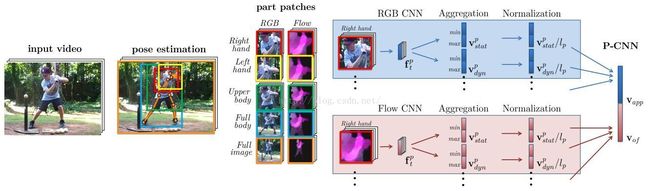
- 首先利用一些state-of-art的pose estimator来提取视频里面的每帧的pose.
- 定义parts。
- 如图中的upper body full body等, 并利用pose的坐标来截取每个part的patches,这里的patches包括rgb原图和motion图. motion图就是光流图。
- 用一些经典已训练好的的CNN(s)模型来提取fc特征(如fc7的4096维特征) 。
- 用一些aggregation的方法来进一步提取特征, 使得一个视频的特征P-CNN输出纬度是固定大小的。这里的aggregation的方法有max, min, mean, max/min等. 比较有意思的是, 从实验结果来看,motion的作用远大于rgb的。
- 训练svm的action classifiers。
- 一般来说, 视频的feature descriptors往往是高维的,如P-CNN的160k-d。所以在训练svm时, 需要对特征进行降维操作,可以用PCA等这些方法。
一些实现细节:
Crop Patches
RGB图像和flow图都通过定位分为了左手lefthand、右手righthand、上身upperbody、全身fullbody、全图fullimage五个patch,每个patch会resize到224x224来匹配CNN的输入。
extract_cnn_patches(video_names,param)
% get part boxes
% part CNN (fill missing part before resizing)
% 尺度
sc=scale(idim);
% box的边长 param.lside为指定的边长。对于JHMDB是40,MPIIcooking是120
lside=param.lside*sc ;
% left hand
% get_box_and_fill: given boxes positions and image, return the corresponding box with pixels
% out of the image filled with gray
lhand = get_box_and_fill(positions(:,param.lhandposition,idim)-lside,positions(:,param.lhandposition,idim)+lside,im);
lhand = imresize(lhand, net.normalization.imageSize(1:2)) ;
% right hand
rhand = get_box_and_fill(positions(:,param.rhandposition,idim)-lside,positions(:,param.rhandposition,idim)+lside,im);
rhand = imresize(rhand, net.normalization.imageSize(1:2)) ;
% upper body
sc=scale(idim); lside=3/4*param.lside*sc ;
upbody = get_box_and_fill(min(positions(:,param.upbodypositions,idim),[],2)-lside,max(positions(:,param.upbodypositions,idim),[],2)+lside,im);
upbody = imresize(upbody, net.normalization.imageSize(1:2)) ;
% full body
fullbody = get_box_and_fill(min(positions(:,:,idim),[],2)-lside,max(positions(:,:,idim),[],2)+lside,im);
fullbody = imresize(fullbody, net.normalization.imageSize(1:2)) ;
% full image CNNf (just resize frame)
fullim = imresize(im, net.normalization.imageSize(1:2)) ;get_box_and_fill(topleft,botright,im)
function box=get_box_and_fill(topleft,botright,im)
% given boxe positions and image, return the corresponding box with pixels
% out of the image filled with gray
% 对于左手和右手
% 左上:positions(:,param.lhandposition,idim)-lside
% 右下:positions(:,param.lhandposition,idim)+lside
% 对于上半身和全身
% topleft:min(positions(:,param.upbodypositions,idim),[],2)-lside
% botright:max(positions(:,param.upbodypositions,idim),[],2)+lside
[h,w,~]=size(im);
% 取整
topleft=round(topleft);
botright=round(botright);
% 每个值都是128的三维矩阵
box=uint8(128*ones(botright(2)-topleft(2)+1,botright(1)-topleft(1)+1,3));
% check if a part of the box is in the image
if topleft(1) > w || topleft(2) > h || botright(1) < 1 || botright(2) < 1
return % return a gray box 返回灰度box
end
left_min = max(topleft(1),1) ;
top_min = max(topleft(2),1) ;
right_max = min(botright(1),w) ;
bot_max = min(botright(2),h) ;
im_w=left_min:right_max ;
im_h=top_min:bot_max ;
box(top_min-topleft(2)+1:top_min-topleft(2)+length(im_h),left_min-topleft(1)+1:left_min-topleft(1)+length(im_w),:)=im(im_h,im_w,:);
提取CNN特征
- 对于RGB和flow,分别采用了两个模型:
- RGB: Imagenet的VGG-f
- flow:flow_net(pretrained on UCF101,Finding action tubes, CVPR2015)
- 上述两个模型都是5conv+3fc,得到的特征都是4096-d
-
extract_cnn_features(video_names,param)
% extract CNN features per frame
for b=1:bsize:nim
fprintf('%s -- feature extraction: %d\tover %d:\t',suf{i},b,nim);tic;
im = vl_imreadjpeg(filelist(b:min(b+bsize-1,nim)),'numThreads', param.nbthreads_netinput_loading) ;
im = cat(4,im{:}) ;
im = bsxfun(@minus, im, net.normalization.averageImage) ;
if param.use_gpu ; im = gpuArray(im) ; end
res=vl_simplenn(net,im);
fprintf('extract %.2f s\t',toc);tic;
save_feats(squeeze(res(end-2).x),outlist(b:min(b+bsize-1,nim)),param); % take features after last ReLU
fprintf('save %.2f s\n',toc)
end计算PCNN特征
作者的pcnn特征,采用了不同的aggregation scheme(聚合策略)。paper当中提出来的有以下几种:
- max-aggr
- max/min-aggr
- (static+dyn)(max-aggr)
- (static+dyn)(max/min-aggr)
- mean-aggr
max和min就是求取每一帧每个part的cnnfeatures当中每一维的最大或者最小值,然后串联起来。
static:把最大最小值串联起来
dyn:对于最大最小特征,每隔4帧求取cnnfeatures的差值。
compute_pcnn_features(param)
disp('In appearance') % 处理RGB图片,计算每个部分的norms(代码在下面,其实就是L2范数啦)
if isfield(param,'perpartL2') && param.perpartL2
fprintf('Compute per part norms ---> '); tic;
norms=get_partnorms(param.trainsplitpath,featdir_app,param);
fprintf('%d sec\n',round(toc));
else
norms=[];
end
[Xn_train,Xn_test] = get_Xn_train_test(featdir_app,param,norms);
disp('In flow') % 处理光流图片
if isfield(param,'perpartL2') && param.perpartL2
fprintf('Compute per part norms ---> '); tic;
norms=get_partnorms(param.trainsplitpath,featdir_flow,param);
fprintf('%d sec\n',round(toc));
else
norms=[];
end
% 计算线性核并保存
if param.compute_kernel
disp('Compute Kernel Test')
Ktest = Xn_test'*Xn_train;
savename=sprintf('%s/Ktest.mat',param.savedir);
disp(['Save test kernel in: ',savename])
assert(sum(isinf(Ktest(:)))==0 && sum(isnan(Ktest(:)))==0)
save(savename,'Ktest','-v7.3')
clear Ktest ;
clear Xn_test ;
disp('Compute Kernel Train')
Ktrain = Xn_train'*Xn_train;
assert(sum(isinf(Ktrain(:)))==0 && sum(isnan(Ktrain(:)))==0)
savename=sprintf('%s/Ktrain.mat',param.savedir);
disp(['Save train kernel in: ',savename])
save(savename,'Ktrain','-v7.3')
clear Ktrain ;
clear Xn_train ;
%计算L2范数
function norms=get_partnorms(splitpath,featdirraw,param)
partids = param.partids;
%% Compute norms
[samplelist,numfil]=get_sample_list(splitpath,featdirraw);
%samplelist 一个cell。cell(1000,1)
%numfil 文件数量
norms = zeros(length(partids),numfil);
nframes=zeros(length(partids),numfil);
parfor ii=1:numfil
pathname=samplelist{ii};
tmp=load(pathname) ;
norms_ii=norms(:,ii);
nframes_ii=nframes(:,ii);
for nd=1:length(partids)
cnnf=tmp.features(partids(nd)).x;%cnnfeatures
norms_ii(nd)=norms_ii(nd)+sum(sqrt(sum(cnnf.^2,2)));%计算2范数
nframes_ii(nd)=nframes_ii(nd)+size(cnnf,1);%size(cnnf,1)返回cnnf的行数
end
norms(:,ii)=norms_ii;
nframes(:,ii)=nframes_ii;
%fprintf('NORM: %d out of %d\n',ii,numfil)
end
norms=sum(norms,2);
nframes=sum(nframes,2);
norms=norms./nframes;