泛型:运行原理
1,泛型没有写死类型,调用的时候指定类型,这个是延时声明
2,延时声明,把参数类型的声明推迟到调用,
3,在即时编译中将泛型代码生成了原生代码,根据不同的类型生成不同的副本,等待程序去运行,性能跟原生代码几乎一致,
一,泛型有泛型类,泛型方法,泛型委托和泛型接口
泛型类 :这个命名空间的namespace System.Collections.Generic的泛型类,GenericDemo
泛型方法:泛型中有where ,Select等泛型的扩展方法,GetT
public void GetT(T t) { Console.WriteLine(t); }
泛型接口:IEnumerable这个是泛型接口
public interface GenericInter{ }
泛型委托:func和Action
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace GenericDelegate { class Program { static void Main(string[] args) { People p = new People(); //定义了一个委托,这个委托带参数 p.show("abc", p.Say); p.show(123, p.Say); } } public class People { public delegate void showDelegate(T t); public void show (T t, showDelegate showDelegate) { showDelegate(t); } public void Say (T t) { Console.WriteLine(t); } } }
二,为什么要有泛型?
多个方法,但是参数不一样时候,我们需要用泛型来解决,用object会造成太多装箱拆箱,消耗性能 ,如下公用代码:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace GenericDemo { class Program { static void Main(string[] args) { show(1); show("test"); Console.Read(); } public static void show(T t) { Console.WriteLine(t); } } }
二,什么是泛型缓存?先看如下,代码运行结果
Program.cs
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace GenericDemo { class Program { static void Main(string[] args) { var s = new SqlUtil(); var str1 = s.GetSql(); Console.WriteLine(str1); var s1 = new SqlUtil (); var str2 = s1.GetSql(); Console.WriteLine(str2); //一开始 var bo = s.Equals(s1); //输出false,证明两个构造出来的变量是不一样的 Console.WriteLine(bo); } } public class User { public int Id { get; set; } public string Name { get; set; } public string Title { get; set; } }
public class Dept
{
public int Id { get; set; }
public string Name { get; set; }
public string Title { get; set; }
}
}
SqlUtil.cs
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace GenericDemo { public class SqlUtil{ public static string strSql = ""; //public SqlUtil() //{ // Console.WriteLine("{0}public构造",this.GetType().Name); //} static SqlUtil() { Type t = typeof(T); var colums = string.Join(",", t.GetProperties().Select(m => $"[{m.Name}]")); strSql = $"select {colums} from {t.Name}"; Console.WriteLine("{0}被构造", t.Name); } public string GetSql() { return strSql; } } }
运行结果如下

这个时候我们就好奇了,为什么user被构造只是出现一次?那这样会不会理解成静态构造只是构造一个实例?其实s和s1是相等的?我们用代码比较一下
var bo = s.Equals(s1); //输出false,证明两个构造出来的变量是不一样的 Console.WriteLine(bo);

可结果出乎我意料,结果他们两个实例是不相等的。那这个是什么原因呢?我们给SqlUtil添加构造函数
public SqlUtil() { Console.WriteLine("{0}public构造",this.GetType().Name); }

结果输出了,SqlUtil被构造了两次,被初始化了两次结果肯定是不一样的,所以s和s1的值肯定不相等。那这个时候我们就疑惑了。静态构造的意义在哪里?根据上图结果,静态构造在特定类型的整个进程中,只会被构造一次,那他跟泛型缓存又有什么关系呢?
三,我们先来理解下程序编译整一个过程,如下图:

根据上图,我们可以总结为:
一,如下
1,程序在vs等开发工具中编译成DLL/ EXE,然后经过CLR(通用语言进行时)和JIT即时编译(二次编译),然后才能被转换为计算机语言,(PS:CLR和JIT是window安装了.netframework就有的的运行环境)
2,在编译器编译成DLL后,其中有metadata和IL,IL是被CLR和JIT编译成机器码的中间语言,而metadata是描述你的dll的,被反射后你能看得懂的代码
我们用ILspy反射下,看下图:c#这个是metadata存的给我们反射看的懂的,而IL模式这是给二次编译成机器码的中间语言

看下IL的代码

二,那泛型的编译过程是怎样的呢?
1, 程序编译泛型时会生成一个带占位符中间语言,在中间语言的时候泛型的类型是不确定的,占位符和替换结果如下代码:
Console.WriteLine(typeof(List<>)); Console.WriteLine(typeof(List<string>));
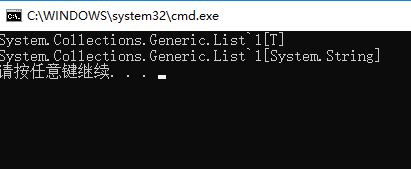
2,在CLR和JIT的二次编译成机器码的时候,方法可以确定被调用,这个时候就可以确定泛型的类型,将真实类型替换占位符,生成确定类型的代码,代码执行的性能跟原声的代码差不多
三,那泛型缓存是怎样的呢?
1,JIT会为不同类型生成一个代码副本,所以泛型类List
2,静态构造函数只会执行一次,在任何一个类里面静态构造函数只会在第一被代码调用当前类调用执行调用,并且只会调用一次,而根据泛型的不同类型就是不同类的定义所以一下代码静态构造会被执行两次
var s3 = new SqlUtil(); var s31 = new SqlUtil (); var s4 = new SqlUtil ();

3,总结:泛型缓存是利用泛型的编译原理,不同的类型参数产生不同的类,类里面用静态缓存数据,下次可以直接用静态字段的数据(PS:即是静态构造根据泛型的类型不一样,会被执行一次,执行静态构造是泛型类中的静态字段同时赋值,下次调用相同类型的泛型类时,可以直接使用静态字段保存的值,是利用泛型的编译原理和静态字段来缓存数据)
4,泛型缓存是根据类型相关,一个类型只能缓存一个结果,一份数据,相对字典来说性能高,字典是(key-value的hash存储,每次查找都要进行哈希运算),泛型缓存则是直接被JIT编译成一个代码段,这个代码段又有静态缓存,可以直接用,所以性能比字典高
5,泛型缓存:泛型会在JIT编译中,为不同类型生成不同的副本,那么在不同副本中,静态元素是独立的,初始使用会去初始化,以后可以直接重用,这就是缓存的效果