-
多线程的实现?
三种方法:1.继承Thread类;2.实现Runnable接口;3.使用Executor创建线程池;
-
多线程的的同步/线程安全的方式?
(1)同步方法:synchronized修饰的方法;
(2)同步代码块:同步是一种高开销的操作,因此应该尽量减少同步的内容。通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。
同步方法和同步代码块的区别是什么?
答:同步方法默认用this或者当前类class对象作为锁; 同步代码块可以选择以什么来加锁,比同步方法要更细颗粒度,我们可以选择只同步会发生同步问题的部分代码而不是整个方法。
(3)使用volatile实现同步:每次线程要访问volatile修饰的变量时都是从内存中读取,而不是从缓存当中读取,因此每个线程访问到的变量值都是一样的。这样就保证了同步。
(4)使用重入锁实现线程同步:ReentrantLock是concurrent包的类;常用方法有lock()和unlock();可以创建公平锁;支持非阻塞的tryLock(可超时);需要手动释放锁。
(5)使用ThreadLocal实现线程同步:每个线程都创建一个变量副本,修改副本不会影响其他线程的副本。ThreadLocal并不能替代同步机制,两者面向的问题领域不同。同步机制是为了同步多个线程对相同资源的并发访问,是为了多个线程之间进行通信的有效方式;而ThreadLocal是隔离多个线程的数据共享,从根本上就不在多个线程之间共享资源(变量)。
-
多线程的优化?
影响多线程性能的问题:死锁、过多串行化、过多锁竞争等;
预防和处理死锁的方法:
1)尽量不要在释放锁之前竞争其他锁;一般可以通过细化同步方法来实现;
2)顺序索取锁资源;
3)尝试定时锁tryLock();
降低锁竞争方法:
1)缩小锁的范围,减小锁的粒度;
2)使用读写分离锁ReadWriteLock来替换独占锁:来实现读-读并发,读-写串行,写-写串行的特性。这种方式更进一步提高了可并发性,因为有些场景大部分是读操作,因此没必要串行工作。
-
线程池有哪几种?有哪些参数?
(1.创建;2.四类线程池;3.参数;)
创建:线程池的顶级接口是Executor,是执行线程的工具;真正的线程接口是ExecutorService;
ThreadPoolExecutor是ExecutorService的默认实现;
示例:
ExecutorService pool=Executors.newFixedThreadPool(2);
四类线程池:
1. newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
2.newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
3. newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
4.newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
线程池ThreadPoolExecutor的参数:
corePoolSize - 池中所保存的线程数,包括空闲线程。
maximumPoolSize-池中允许的最大线程数。
keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
unit - keepAliveTime 参数的时间单位。
workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。
threadFactory - 执行程序创建新线程时使用的工厂。
handler - 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
关于corePoolSize和maximumPoolSize:
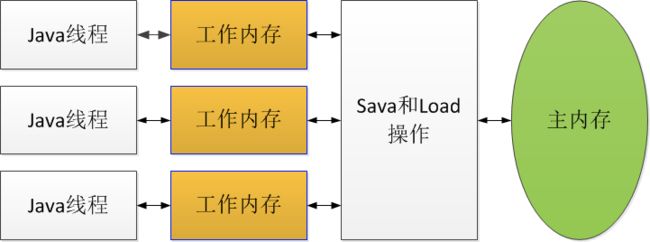
如果线程数 如果corePoolSize<线程数 根据java.lang.Thread.State类,线程包括六个状态: (NEW、RUNNABLE、BLOCKED、WAITTING、TIME_WAITTING、TERMINATED) NEW:线程实例化还未执行start(); RUNNABLE:线程已经在JVM执行。(根据是否取得CPU时间片对应操作系统的Running和Ready状态;) BLOCKED:线程阻塞;等待锁, WAITTING:线程无限期等待;调用Object.wait() 没有timeout 或者 Thread.join() 没有timeout 时进入该状态; TIMED_WAITTING:线程限期等待;调用Thread.sleep、Object.wait(timeout) 或者 Thread.join(timeout)是进入该状态; TERMINATED:线程终止; (相比较原版本,DEAD更改为TERMINATED,没有Running状态,有WAITTING和TIMED_WAITTING状态;) 状态变化: (和原版本的区别,没有Running状态;等待不属于阻塞、sleep/join不属于阻塞!) Runnable:t.start();从new变为Runnable; Waitting:Runnable执行wait()/join();无限等待唤醒; Timed_Waitting:Runnable执行sleep()/wait(timeout)/join(timeout); wait释放锁,sleep()不释放锁;等待唤醒,但设置了时限; Blocked:线程在等待锁; 在当前的Java内存模型下,线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。 要解决这个问题,只需要像在本程序中的这样,把该变量声明为volatile(不稳定的)即可,这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。一般说来,多任务环境下各任务间共享的标志都应该加volatile修饰。 volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。 使用volatile关键字修饰变量,线程要访问变量时都是从内存中读取,而不是从缓存当中读取,因此每个线程访问到的变量值都是一样的。 tryLock(),避免死锁;synchronized是不公平锁,而Lock可以指定锁公平还是不公平; syn实现wait/notify机制通知的线程是随机的,Lock可以有选择性的通知。 并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。 原子性:一组操作要么全部完成,要么全部不完成; 可见性:当多个线程同时访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值; 有序性:并发的情况下,实际执行的结果和单线程的执行结果是一样的,不会因为重排序的问题导致结果不可预知。 ReentrantReadWriteLock:读写各用一把锁;对于读多写少场景效率高。 读写锁表示两个锁,一个是读操作相关的锁,称为共享锁;另一个是写操作相关的锁,称为排他锁。我把这两个操作理解为三句话: 1、读和读之间不互斥,因为读操作不会有线程安全问题 2、写和写之间互斥,避免一个写操作影响另外一个写操作,引发线程安全问题 3、读和写之间互斥,避免读操作的时候写操作修改了内容,引发线程安全问题 总结起来就是,多个Thread可以同时进行读取操作,但是同一时刻只允许一个Thread进行写入操作。 PS:JVM内存模型和JMM(Java内存模型)没有关系。JMM的目的是为了解决Java多线程对共享数据的读写一致性问题。 Java内存模型规定: 所有的变量都存储在主内存中; 每个线程有自己的工作内存,线程的工作内存保存被线程使用到变量的主内存副本拷贝; 线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存的变量; 不同线程之间不能直接访问对方工作内存中的变量,线程间变量值的传递通过主内存来完成。 内存间交互操作 Java内存模型定义了八种操作: (lock/unlock、read/load主内存-工作内存、use/assign工作内存-执行引擎、store/write工作内存-主内存) lock(锁定):作用于主内存的变量,它把一个变量标识为一个线程独占的状态; unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定; read(读取):作用于主内存的变量,它把一个变量的值从主内存传送到线程中的工作内存,以便随后的load动作使用; load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中; use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎; assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存中的变量; store(存储):作用于工作内存的变量,它把工作内存中的一个变量的值传送到主内存中,以便随后的write操作; write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值写入主内存的变量中。 操作时规则 不允许read和load、store和write操作之一单独出现; 说明:如果要把一个变量从主内存复制到工作内存,那要顺序执行read和load操作;如果要把变量从工作内存同步回主内存,就要顺序执行store和write操作。Java内存模型要求上述连个操作必须按顺序执行,但不必须连续执行。 不允许一个线程丢弃它的最近的assign操作,即变量在工作内存中改变了之后必须把变化同步回主内存; 不允许一个线程无原因地(没有发生过任何assign操作)把数据从线程的工作内存同步回主内存; 一个新变量只能在主内存诞生,不允许在工作内存直接使用一个为被初始化(load或assign)的变量,即在对一个变量实施use和store操作之前,必须先执行assign和load操作; 一个变量在同一个时刻只允许一条线程对其进行lock操作,但lock操作可以被同一线程重复执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才被解锁; 如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值; 如果一个变量事先没有被lock操作锁定,则不允许对他执行unlock操作;也不允许去unlock一个被其他线程锁定住的变量; 对一个变量执行unlock操作之前,必须先把此变量同步回主内存。 volatile 关键字volatile是JVM提供最轻量级的同步机制。 当一个变量被定义成volatile后,它具有两个特性: 第一,volatile变量对所有线程是立即可见的,对于volatile变量所有的写操作都能立刻反应到其他线程之中;但volatile变量只能保证可见性,不能保证在并发下是安全的。 第二,禁止指令重排序优化。 Java模型特性 原子性:read、load、assign、use、store和write保证原子性变量操作;lock和unlock通过synchronized语法来加锁,在synchronized块之间的操作也具有原子性; 可见性:volatile、synchronized和final实现变量修改值在其他线程可见;synchronized可见性是由“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中”这条规则获得的;final可见性是“被final修饰的字段在构造器中一旦被初始化完成,并且构造器没有把this的引用传递出去,那么在其他线程就能看到final字段的值。” 有序性:Java语言提供volatile和synchronized两个关键字来保证线程之间的有序性;volatile本身禁止指令重排序;synchronized是由“一个变量在同一个时刻只允许一条线程对其进行lock操作“这条规则获得的。
线程的状态有哪些?
wait和sleep区别?
volatile的作用?
synchronized和lock的区别?
并发过程需要保证的特性?
synchronized和volatile的内存可见性和原子性?
原子性:即不可再分了,不能分为多步操作。比如赋值或者return。比如"a = 1;"和 "return a;"这样的操作都具有原子性。类似"a += b"这样的操作不具有原子性,在某些JVM中"a += b"可能要经过这样三个步骤:
① 取出a和b
② 计算a+b
③ 将计算结果写入内存
Synchronized能够实现原子性和可见性;在Java内存模型中,synchronized规定,线程在加锁时,先清空工作内存→在主内存中拷贝最新变量的副本到工作内存→执行完代码→将更改后的共享变量的值刷新到主内存中→释放互斥锁。
Volatile实现内存可见性是通过store和load指令完成的;也就是对volatile变量执行写操作时,会在写操作前加入一条store指令,即强迫线程将最新的值刷新到主内存中;而在读操作时,会加入一条load指令,即强迫从主内存中读入变量的值。但volatile不保证volatile变量的原子性。
读写锁的优势?
ThreadLocal的作用?
Java内存模型?
Concurren下的类?