- 【Flutter】面试记录
古希腊被code拿捏的神
flutter面试职场和发展
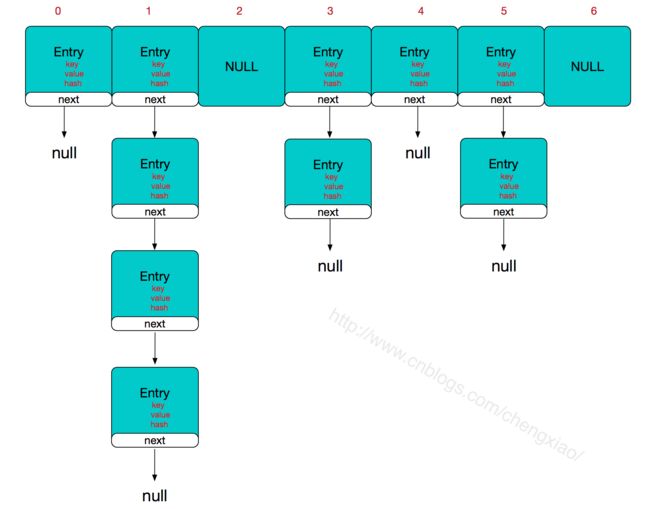
本文部分内容参考博文目录Flutter三棵树渲染原理渲染原理三者之间的关系参数位置参数mixin、extends和implementsmixin(混入)extends(继承)implements(实现)Flutter如何与Native通信的?如何从Flutter传递一个dart类到原生?常用的三种状态管理框架provider的渲染机制二叉树遍历递归与迭代什么是迭代?什么是递归?(怎么写一个递归函数
- 【秋招算法】2025 届搜广推方向求职历程(SSP、头部计划)
秋冬无暖阳°
搜广推等—算法面经面试职场和发展算法
【秋招算法】2025届搜广推方向求职历程(SSP、头部计划)文章目录【秋招算法】2025届搜广推方向求职历程(SSP、头部计划)1.背景2.日常实习3.暑期实习3.1暑期BG3.2暑期记录4.秋招4.1秋招BG4.2转正4.3头部4.4提前批4.5正式批5.面试记录5.1Coding5.2其他高频编程题5.3常见八股、面经6.关于搜广推1.背景关于日常实习、暑期实习、提前批,秋招、春招、补招何为大
- 第一次前端面试记录
Daisuki_
前端面试cssjavascriptvue.js
第一次前端面试记录应聘职位:互联网前端开发工程师面试方式:电话应聘企业:某电子信息产业集团公司面试流程:简历投递英语面试就是在微信“闪面”小程序和机器人对话,录制你的对话,一共两个问题,每个问题都有三次机会可以重新录制。第一个是英文自我介绍,第二个是“你觉得自己能胜任这份工作的理由”。电话面试上传英语面试结果之后,大概等了三四天,在吃晚饭的时候接到了面试的电话要求,是技术面。HR询问我十分钟之内可
- 百度前端面试记录
若寒hqq
每天都要督促自己前端面试百度
刚去就感觉百度的人都特别好,对人好,照顾周到,虽然整体流程不如阿里那么高大上(比如叫号码牌,二维码扫描。。。),但氛围绝对吸引人。先找空闲的面试官,一面面试官ok我选了一个看起来不会为难人的,O(∩_∩)O哈哈哈~面试时间最长了,感觉对我实习公司的项目很感兴趣,然后就一直追着问,记住一定要让面试官抓住一点觉得很欣赏你的这种技术或者思路和做法。然后给我出了个冒泡排序,我在那写,他给我写评语,写完后他
- 山东大学软件学院项目实训-基于大模型的模拟面试系统-面试官和面试记录的分享功能(2)
鸠菜
项目实训面试
本文记录在发布文章时,可以添加自己创建的面试官和面试记录到文章中这一功能的实现。前端首先是在原本的界面的底部添加了两个多选框(后期需要美化调整)实现的代码:{{item.name}}{{item.topic}}{{item.topic}}-->然后是前端脚本,添加以下函数:getInterviewers用来获取该用户创建的所有面试官。getInterviews用来获取该用户创建的所有面试记录。其次
- MySQL数据库面试记录
FINE!(正在努力!)
数据库mysql面试
主键、外键和索引的区别?主键:唯一标识一条记录,不能有重复的,不允许为空,用来保证数据完整性。主键只能有一个。外键:表的外键是另一表的主键,外键可以有重复的,可以是空值,用来和其他表建立联系,从而保证数据的一致性和完整性。一个表可以有多个外键。索引:该字段没有重复值,但可以有一个空值,是提高查询排序的速度。一个表可以有多个唯一索引。InnoDB数据存储方式InnoDB存储格式由大到小:表空间→段→
- 从零开始:使用 Playwright 脚本录制实现自动化测试
2301_78234743
java
实习招继任!网易新媒体运营实习生!4.15虾皮笔试滴滴暑期今天面试有人三面了吗航空工业工作感受腾讯测开腾讯wxg测开面经(已offer)延毕还是先毕业再找?延毕还是先毕业再找?被科曼医疗毁约了,还有什么公司在招人啊,给推荐一下吧[牛泪]CVTE国内销售面试记录第一轮商务谈判,群面小组面题目背景:A学校是市内重点高中学校,原有100台台式电脑30万元,现在打字节一面面经社招一年经验自我介绍你知道的搜
- 社招 Java 中厂面试记录,难度有点大!
个人情况:社招一年半面试公司:上海海鼎信息和深圳小赢科技面试感受:总体难度还是有点大的,第二家公司拷打的问题非常非常多,一共60个问题,多少有点离谱儿。不过,面试体验很好,面试官会引导往哪个方向思考。一面请做一下自我介绍。请介绍一下你参与过的项目。请解释一下接口(Interface)和抽象类(AbstractClass)的区别。什么是受检异常(CheckedException)和非受检异常(Unc
- 社招 Java 中厂面试记录,难度有点大!
个人情况:社招一年半面试公司:上海海鼎信息和深圳小赢科技面试感受:总体难度还是有点大的,第二家公司拷打的问题非常非常多,一共60个问题,多少有点离谱儿。不过,面试体验很好,面试官会引导往哪个方向思考。一面请做一下自我介绍。请介绍一下你参与过的项目。请解释一下接口(Interface)和抽象类(AbstractClass)的区别。什么是受检异常(CheckedException)和非受检异常(Unc
- 【面经&八股】搜广推方向:面试记录(十三)
秋冬无暖阳°
搜广推等—算法面经面试职场和发展
【面经&八股】搜广推方向:面试记录(十三)文章目录【面经&八股】搜广推方向:面试记录(十三)1.自我介绍2.实习经历问答3.八股之类的问题4.编程题5.反问6.可以1.自我介绍。。。。。。2.实习经历问答挑最熟的一个跟他讲就好了。一定要熟~3.八股之类的问题极大似然估计和贝叶斯估计,区别与联系建议参考这个链接transformer为什么要使用多头关键点在于集成,使语义更加完善圆上随机去三个点,三个
- 【面经&八股】搜广推方向:面试记录(九)
秋冬无暖阳°
搜广推等—算法面经面试职场和发展
【面经&八股】搜广推方向:面试记录(九)文章目录【面经&八股】搜广推方向:面试记录(九)1.自我介绍2.科研-项目经历问答3.实习经历问答4.八股5.编程题6.反问1.自我介绍。。。。。。2.科研-项目经历问答挑了我的论文,一直揪着问,建议一定要熟悉自己的工作。3.实习经历问答这个基本上没问。4.八股写一下LR—逻辑回归损失公式:当y=1时,损失函数等于y_hat的负对数,即越接近1,损失越小;越
- 社招后端中厂面试,全程被吊打!
这是一位读者参加武汉招银云创社招的面试记录,全程被吊打,共47min,结果也如预想那样没有通过。读者情况:社招,三年经验。下面是正文。社招,面试了武汉的招银云创,一共47min的技术拷打,堪称八股盛宴,难度有点大,感觉全程被吊打。不是?现在强度这么大的嘛?下面分享一下面试被拷打的一些技术问题。如何保证你的流程引擎和业务代码解耦?用到了哪些架构设计?或者说设计模式?抽象哪些业务功能出来流程审批完之后
- 招聘系统与银行支付的结合:功能与技术实现
久久鸿网络
产品运营设计规范架构
1.招聘系统功能招聘系统作为一种数字化工具,其核心功能包括:职位发布与管理:企业可以在招聘系统中发布和管理职位信息,包括职位描述、要求和薪资范围。简历收集与筛选:系统自动从多个渠道收集简历,并根据预设条件进行筛选,提高效率。候选人库管理:所有候选人信息存储于候选人库中,便于长期人才储备和管理。面试安排与通知:根据候选人状态和进度,系统自动安排面试并发送通知。面试记录与评价:招聘人员可以记录和评价候
- Harmony面试模版
学海无涯乐作舟
客户端面试面试职场和发展
1.自我介绍看表达能力、沟通能力面试记录:2.进一步挖掘2.1.现状目前是在职还是离职,如果离职,从上一家公司离职的原因2.2.项目经验如果自我介绍工作项目经验讲的不够清楚,可以根据简历上的信息再进一步了解面试记录:3.鸿蒙技术问题3.1.ArkTS3.1.1.基础3.1.1.1.基本数据类型有哪些数据类型概述基本类型number数值boolean布尔string字符串arrayRecordObj
- java面试记录
为什么没有实习
面试职场和发展
HashMap里的碰撞在Java中,HashMap是一种常用的哈希表实现,它使用哈希函数来确定键值对的存储位置。当多个键映射到同一个桶(bucket)时,就会发生哈希碰撞(hashcollision)。哈希碰撞是哈希表中不可避免的现象,但可以通过合理的设计来最小化其影响。哈希碰撞的原因哈希碰撞通常是因为哈希函数产生的哈希值相同,而哈希表的大小有限,导致多个键值对映射到了同一个位置。处理哈希碰撞的方
- 3.14-嵌入式软件实习生-面试记录
Loooqy
嵌入式面试记录面试职场和发展
经纬恒润嵌入式软件实习生面试记录自我介绍函数指针函数指针是一个指向函数的指针变量,它的本质是指针变量,但它指向的是函数的首地址。在C语言中,每一个函数在编译时都有一个入口地址,这个地址就是函数指针所指向的地址。函数指针的主要用途包括调用函数和作为函数的参数。指针函数,又称为带指针的函数,它的本质是一个函数。其特别之处在于,这个函数的返回值是一个地址值,即函数返回类型是某一类型的指针。结构体联合体概
- 2024 IC FPGA 岗位 校招面试记录
在路上-正出发
我的面试记录面试经验分享程序人生华为海思联发科1024程序员节新思科技
引言各位看到这篇文章时,24届校招招聘已经渐进尾声了。在这里记录一下自己所有面试(除了时间过短或者没啥干货的一些研究所外,如中电55所(南京),航天804所(上海))的经历以及感悟。希望给秋招的小伙伴或者明年、后年要找工作的小伙伴一些借鉴。本人的话,研究生期间所做的项目都是跟FPGA相关,并未参与ASIC芯片设计相关的项目。HR面试不记录在内,只记录跟技术面沾边的一些问题。联发科技实习一面岗位:I
- 2018年7月面试记录
Goach
MRCM聊天缓存如何实现的聊天重发如何实现如何保持长连接心跳简述TCP协议写一个自己最擅长的设计模式ZHYTfinish会立马销毁activity吗view的生命周期activity结束了HandlerQueue如何处理Handler如何知道activity已经结束了CMJFAndroid的单元测试kotlin的回收机制Hash算法FCActivity,Window,View之间的关系Fragme
- 实习面试记录2
1024_
C++11的新特性C++中有四种智能指针:auto_pt、unique_ptr、shared_ptr、weak_ptr其中后三个是C++11支持,第一个已经被C++11弃用且被unique_prt代替,不推荐使用。各自的特点以及区别:1、std::unique_ptr对其持有的堆内存具有唯一拥有权,也就是std::unique_ptr不可以拷贝或赋值给其他对象,其拥有的堆内存仅自己独占,std::
- 毕业一年后,第二次面试记录和心得体会
rong193000
基本信息:待离职,忙于面试中求职岗位:Android开发面试时间在下午2.30,面试地点是在深圳南山西丽波顿工业园里。由于最近的工作激情不高,索性就请了半天假,虽然从公司到面试地点只有5个公交站,由于生物钟和情绪的缘故,晕车及其严重,平常,我是断然不会晕车的。经过了十多分钟上的折腾,终于来到了面试地点,是在新修的写字楼里,栅栏外边,遍布荒草,一看就是待开发区域。到了大厅,饥渴难忍,就买了瓶尖叫来缓
- 面试记录(被问倒的)
Uqiumu
面试职场和发展u3d
快排,设计模式(观察者模式mvc模式单例模式)及其优势,工作遇到的困难,解决过的问题,渲染管线,ui合批(动静分离),比较复杂的编辑器扩展,算法,用算法解决过什么问题,必须掌握的排序算法,快排每一轮是怎么走的以下是笔记渲染管线流程包括下面几个步骤:顶点处理、面处理、光栅化、像素处理等。观察者模式定义:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动
- Android中高级开发工程师-面试记录-长期更新(二)
肖义熙
由于篇幅原因,接上面的一篇继续:Android中高级开发工程师-面试记录-长期更新JD一面2021-05-2620:30电话面试1、Kotlin和Java的运算符可以重载么?协程和线程的区别2、自定义View和自定义ViewGroup的区别3、onMeasure、onLayout、onDraw方法的先后顺序,有没有哪些方法可以触发执行,invalidate、layout、postinvalidat
- 国考结构化面试I到底考什么?常见题型分析
区域_教育
国考面试形式主要有结构化面试、无领导小组、结构化小组三种。今天先了解结构化面试的基本情况。结构化面试面试题量每天两套题(部分单位每天一套题),每套4-5道题(2020年某部选调生、2019年商务部等部门为3道题)。面试时长结构化面试记录总时长,题量不同时间不同:结构化面试25分钟5道题和20分钟4道题情况居多(根据题目的个数,平均1题5分钟);部分岗位3道题15分钟;看题时间和思考时间都计算在总时
- web前端面试记录 2022-09-13
亿个小目标
背景外包公司,面向客户是银行。社招岗位:web前端开发过程1.线上面试2.自我介绍3.项目介绍4.过程中遇到的问题5.根据上述的内容面试官进行细节挖掘和扩展6.场景题:现在需要一个开发一个动态配置表单的界面,你会遇到什么问题?7.js技术题:定时器什么时候会失效?8.兼容性问题9.对于w3c协议的理解有哪些?10.webpack的配置(问的比较细)小结攒经验。第一次项目介绍得不好,所以导致后面面试
- 【面经&八股】搜广推方向:面试记录(四)
笃℃
搜广推算法面经面试职场和发展
【面经&八股】搜广推方向:面试记录(四)文章目录【面经&八股】搜广推方向:面试记录(四)1.自我介绍2.项目问答3.八股4.编程题4.1大数加法4.2平面最近点对问题求解5.反问环节1.自我介绍。。。。。。2.项目问答问的有点细。。。。。。3.八股1)自监督、监督、无监督的区别首先比较监督和无监督学习,其最主要的区别在于模型在训练时是否需要人工标注的标签信息。监督学习利用大量的标注数据来训练模型,
- 【面经&八股】搜广推方向:面试记录(一)
笃℃
搜广推算法面经面试职场和发展
【面经&八股】搜广推方向:面试记录(一)字节跳动文章目录【面经&八股】搜广推方向:面试记录(一)字节跳动1.自我介绍2.项目、科研介绍3.有了解过工业届的推荐模型4.编程题4.1手写auc4.2手写矩阵的逆5.反问环节1.自我介绍。。。2.项目、科研介绍面试官问你答(之前做的东西,时间长没看,昨晚愣是说的有些吞吞吐吐,面试前还得熟练)3.有了解过工业届的推荐模型典型的双塔模型。召回阶段:统计类,热
- 【面经&八股】搜广推方向:面试记录(三)
笃℃
搜广推算法面经面试职场和发展
【面经&八股】搜广推方向:面试记录(三)文章目录【面经&八股】搜广推方向:面试记录(三)1.编程题1.1大数乘法1.2大数加法2.项目介绍3.有了解过的广告推荐模型吗4.广告模型回归问题1.编程题上来直接写编程题,有点儿懵逼。1.1大数乘法可以参考该博客,其实掌握最简单的模拟就够用了。/***大数相乘
- 2021秋招-面经
LBJ_King2020
算法
面经总结微软STCA面试-面经字节AIlab实习面试记录腾讯PCG-腾讯新闻面试百度(AIDU)-内容策略部门面试百度(AIDU)-搜索策略-机器学习算法工程师百度(AIDU)-知识图谱部门算法工程师(2020-07-08)百度(AIDU)-NLP部门算法工程师(2020-07-10)微软STCA面试-面经2020-06-01左右在牛客上面投递微软STCA的面试简历,没看清楚,要求是researc
- 【面试记录】支付宝面试考察技术点
Vine955
面试面试散列表哈希算法
支付宝面试考察技术点1.JDK基础1.1HashMap源码1.2线程池原理1.3[Java8新特性](https://developer.51cto.com/article/647804.html)1.4[锁机制](https://tech.meituan.com/2018/11/15/java-lock.html)(CAS/AQS/重量级&轻量级/偏向锁/独占锁/具体实现/ConcurrentH
- 三年经验前端vue面试记录
bb_xiaxia1998
vue.js
router-link和router-view是如何起作用的分析vue-router中两个重要组件router-link和router-view,分别起到导航作用和内容渲染作用,但是回答如何生效还真有一定难度回答范例vue-router中两个重要组件router-link和router-view,分别起到路由导航作用和组件内容渲染作用使用中router-link默认生成一个a标签,设置to属性定义
- 强大的销售团队背后 竟然是大数据分析的身影
蓝儿唯美
数据分析
Mark Roberge是HubSpot的首席财务官,在招聘销售职位时使用了大量数据分析。但是科技并没有挤走直觉。
大家都知道数理学家实际上已经渗透到了各行各业。这些热衷数据的人们通过处理数据理解商业流程的各个方面,以重组弱点,增强优势。
Mark Roberge是美国HubSpot公司的首席财务官,HubSpot公司在构架集客营销现象方面出过一份力——因此他也是一位数理学家。他使用数据分析
- Haproxy+Keepalived高可用双机单活
bylijinnan
负载均衡keepalivedhaproxy高可用
我们的应用MyApp不支持集群,但要求双机单活(两台机器:master和slave):
1.正常情况下,只有master启动MyApp并提供服务
2.当master发生故障时,slave自动启动本机的MyApp,同时虚拟IP漂移至slave,保持对外提供服务的IP和端口不变
F5据说也能满足上面的需求,但F5的通常用法都是双机双活,单活的话还没研究过
服务器资源
10.7
- eclipse编辑器中文乱码问题解决
0624chenhong
eclipse乱码
使用Eclipse编辑文件经常出现中文乱码或者文件中有中文不能保存的问题,Eclipse提供了灵活的设置文件编码格式的选项,我们可以通过设置编码 格式解决乱码问题。在Eclipse可以从几个层面设置编码格式:Workspace、Project、Content Type、File
本文以Eclipse 3.3(英文)为例加以说明:
1. 设置Workspace的编码格式:
Windows-&g
- 基础篇--resources资源
不懂事的小屁孩
android
最近一直在做java开发,偶尔敲点android代码,突然发现有些基础给忘记了,今天用半天时间温顾一下resources的资源。
String.xml 字符串资源 涉及国际化问题
http://www.2cto.com/kf/201302/190394.html
string-array
- 接上篇补上window平台自动上传证书文件的批处理问卷
酷的飞上天空
window
@echo off
: host=服务器证书域名或ip,需要和部署时服务器的域名或ip一致 ou=公司名称, o=公司名称
set host=localhost
set ou=localhost
set o=localhost
set password=123456
set validity=3650
set salias=s
- 企业物联网大潮涌动:如何做好准备?
蓝儿唯美
企业
物联网的可能性也许是无限的。要找出架构师可以做好准备的领域然后利用日益连接的世界。
尽管物联网(IoT)还很新,企业架构师现在也应该为一个连接更加紧密的未来做好计划,而不是跟上闸门被打开后的集成挑战。“问题不在于物联网正在进入哪些领域,而是哪些地方物联网没有在企业推进,” Gartner研究总监Mike Walker说。
Gartner预测到2020年物联网设备安装量将达260亿,这些设备在全
- spring学习——数据库(mybatis持久化框架配置)
a-john
mybatis
Spring提供了一组数据访问框架,集成了多种数据访问技术。无论是JDBC,iBATIS(mybatis)还是Hibernate,Spring都能够帮助消除持久化代码中单调枯燥的数据访问逻辑。可以依赖Spring来处理底层的数据访问。
mybatis是一种Spring持久化框架,要使用mybatis,就要做好相应的配置:
1,配置数据源。有很多数据源可以选择,如:DBCP,JDBC,aliba
- Java静态代理、动态代理实例
aijuans
Java静态代理
采用Java代理模式,代理类通过调用委托类对象的方法,来提供特定的服务。委托类需要实现一个业务接口,代理类返回委托类的实例接口对象。
按照代理类的创建时期,可以分为:静态代理和动态代理。
所谓静态代理: 指程序员创建好代理类,编译时直接生成代理类的字节码文件。
所谓动态代理: 在程序运行时,通过反射机制动态生成代理类。
一、静态代理类实例:
1、Serivce.ja
- Struts1与Struts2的12点区别
asia007
Struts1与Struts2
1) 在Action实现类方面的对比:Struts 1要求Action类继承一个抽象基类;Struts 1的一个具体问题是使用抽象类编程而不是接口。Struts 2 Action类可以实现一个Action接口,也可以实现其他接口,使可选和定制的服务成为可能。Struts 2提供一个ActionSupport基类去实现常用的接口。即使Action接口不是必须实现的,只有一个包含execute方法的P
- 初学者要多看看帮助文档 不要用js来写Jquery的代码
百合不是茶
jqueryjs
解析json数据的时候需要将解析的数据写到文本框中, 出现了用js来写Jquery代码的问题;
1, JQuery的赋值 有问题
代码如下: data.username 表示的是: 网易
$("#use
- 经理怎么和员工搞好关系和信任
bijian1013
团队项目管理管理
产品经理应该有坚实的专业基础,这里的基础包括产品方向和产品策略的把握,包括设计,也包括对技术的理解和见识,对运营和市场的敏感,以及良好的沟通和协作能力。换言之,既然是产品经理,整个产品的方方面面都应该能摸得出门道。这也不懂那也不懂,如何让人信服?如何让自己懂?就是不断学习,不仅仅从书本中,更从平时和各种角色的沟通
- 如何为rich:tree不同类型节点设置右键菜单
sunjing
contextMenutreeRichfaces
组合使用target和targetSelector就可以啦,如下: <rich:tree id="ruleTree" value="#{treeAction.ruleTree}" var="node" nodeType="#{node.type}"
selectionChangeListener=&qu
- 【Redis二】Redis2.8.17搭建主从复制环境
bit1129
redis
开始使用Redis2.8.17
Redis第一篇在Redis2.4.5上搭建主从复制环境,对它的主从复制的工作机制,真正的惊呆了。不知道Redis2.8.17的主从复制机制是怎样的,Redis到了2.4.5这个版本,主从复制还做成那样,Impossible is nothing! 本篇把主从复制环境再搭一遍看看效果,这次在Unbuntu上用官方支持的版本。 Ubuntu上安装Red
- JSONObject转换JSON--将Date转换为指定格式
白糖_
JSONObject
项目中,经常会用JSONObject插件将JavaBean或List<JavaBean>转换为JSON格式的字符串,而JavaBean的属性有时候会有java.util.Date这个类型的时间对象,这时JSONObject默认会将Date属性转换成这样的格式:
{"nanos":0,"time":-27076233600000,
- JavaScript语言精粹读书笔记
braveCS
JavaScript
【经典用法】:
//①定义新方法
Function .prototype.method=function(name, func){
this.prototype[name]=func;
return this;
}
//②给Object增加一个create方法,这个方法创建一个使用原对
- 编程之美-找符合条件的整数 用字符串来表示大整数避免溢出
bylijinnan
编程之美
import java.util.LinkedList;
public class FindInteger {
/**
* 编程之美 找符合条件的整数 用字符串来表示大整数避免溢出
* 题目:任意给定一个正整数N,求一个最小的正整数M(M>1),使得N*M的十进制表示形式里只含有1和0
*
* 假设当前正在搜索由0,1组成的K位十进制数
- 读书笔记
chengxuyuancsdn
读书笔记
1、Struts访问资源
2、把静态参数传递给一个动作
3、<result>type属性
4、s:iterator、s:if c:forEach
5、StringBuilder和StringBuffer
6、spring配置拦截器
1、访问资源
(1)通过ServletActionContext对象和实现ServletContextAware,ServletReque
- [通讯与电力]光网城市建设的一些问题
comsci
问题
信号防护的问题,前面已经说过了,这里要说光网交换机与市电保障的关系
我们过去用的ADSL线路,因为是电话线,在小区和街道电力中断的情况下,只要在家里用笔记本电脑+蓄电池,连接ADSL,同样可以上网........
- oracle 空间RESUMABLE
daizj
oracle空间不足RESUMABLE错误挂起
空间RESUMABLE操作 转
Oracle从9i开始引入这个功能,当出现空间不足等相关的错误时,Oracle可以不是马上返回错误信息,并回滚当前的操作,而是将操作挂起,直到挂起时间超过RESUMABLE TIMEOUT,或者空间不足的错误被解决。
这一篇简单介绍空间RESUMABLE的例子。
第一次碰到这个特性是在一次安装9i数据库的过程中,在利用D
- 重构第一次写的线程池
dieslrae
线程池 python
最近没有什么学习欲望,修改之前的线程池的计划一直搁置,这几天比较闲,还是做了一次重构,由之前的2个类拆分为现在的4个类.
1、首先是工作线程类:TaskThread,此类为一个工作线程,用于完成一个工作任务,提供等待(wait),继续(proceed),绑定任务(bindTask)等方法
#!/usr/bin/env python
# -*- coding:utf8 -*-
- C语言学习六指针
dcj3sjt126com
c
初识指针,简单示例程序:
/*
指针就是地址,地址就是指针
地址就是内存单元的编号
指针变量是存放地址的变量
指针和指针变量是两个不同的概念
但是要注意: 通常我们叙述时会把指针变量简称为指针,实际它们含义并不一样
*/
# include <stdio.h>
int main(void)
{
int * p; // p是变量的名字, int *
- yii2 beforeSave afterSave beforeDelete
dcj3sjt126com
delete
public function afterSave($insert, $changedAttributes)
{
parent::afterSave($insert, $changedAttributes);
if($insert) {
//这里是新增数据
} else {
//这里是更新数据
}
}
- timertask
shuizhaosi888
timertask
java.util.Timer timer = new java.util.Timer(true);
// true 说明这个timer以daemon方式运行(优先级低,
// 程序结束timer也自动结束),注意,javax.swing
// 包中也有一个Timer类,如果import中用到swing包,
// 要注意名字的冲突。
TimerTask task = new
- Spring Security(13)——session管理
234390216
sessionSpring Security攻击保护超时
session管理
目录
1.1 检测session超时
1.2 concurrency-control
1.3 session 固定攻击保护
- 公司项目NODEJS实践0.3[ mongo / session ...]
逐行分析JS源代码
mongodbsessionnodejs
http://www.upopen.cn
一、前言
书接上回,我们搭建了WEB服务端路由、模板等功能,完成了register 通过ajax与后端的通信,今天主要完成数据与mongodb的存取,实现注册 / 登录 /
- pojo.vo.po.domain区别
LiaoJuncai
javaVOPOJOjavabeandomain
POJO = "Plain Old Java Object",是MartinFowler等发明的一个术语,用来表示普通的Java对象,不是JavaBean, EntityBean 或者 SessionBean。POJO不但当任何特殊的角色,也不实现任何特殊的Java框架的接口如,EJB, JDBC等等。
即POJO是一个简单的普通的Java对象,它包含业务逻辑
- Windows Error Code
OhMyCC
windows
0 操作成功完成.
1 功能错误.
2 系统找不到指定的文件.
3 系统找不到指定的路径.
4 系统无法打开文件.
5 拒绝访问.
6 句柄无效.
7 存储控制块被损坏.
8 存储空间不足, 无法处理此命令.
9 存储控制块地址无效.
10 环境错误.
11 试图加载格式错误的程序.
12 访问码无效.
13 数据无效.
14 存储器不足, 无法完成此操作.
15 系
- 在storm集群环境下发布Topology
roadrunners
集群stormtopologyspoutbolt
storm的topology设计和开发就略过了。本章主要来说说如何在storm的集群环境中,通过storm的管理命令来发布和管理集群中的topology。
1、打包
打包插件是使用maven提供的maven-shade-plugin,详细见maven-shade-plugin。
<plugin>
<groupId>org.apache.maven.
- 为什么不允许代码里出现“魔数”
tomcat_oracle
java
在一个新项目中,我最先做的事情之一,就是建立使用诸如Checkstyle和Findbugs之类工具的准则。目的是制定一些代码规范,以及避免通过静态代码分析就能够检测到的bug。 迟早会有人给出案例说这样太离谱了。其中的一个案例是Checkstyle的魔数检查。它会对任何没有定义常量就使用的数字字面量给出警告,除了-1、0、1和2。 很多开发者在这个检查方面都有问题,这可以从结果
- zoj 3511 Cake Robbery(线段树)
阿尔萨斯
线段树
题目链接:zoj 3511 Cake Robbery
题目大意:就是有一个N边形的蛋糕,切M刀,从中挑选一块边数最多的,保证没有两条边重叠。
解题思路:有多少个顶点即为有多少条边,所以直接按照切刀切掉点的个数排序,然后用线段树维护剩下的还有哪些点。
#include <cstdio>
#include <cstring>
#include <vector&