JVM虚拟机---(3)垃圾回收机制
垃圾回收机制
JVM的五大数据区域:程序计数器,虚拟机栈,本地方法栈,方法区,Heap堆。
其中程序计算器、虚拟机栈、本地方法栈这3个区域都是由线程生产周期,线程结束后自然就会被回收,所以这几个区域的内存分配和回收都是具备稳定性,不需要考虑回收的问题。但方法区和Heap堆就不行,它们的内存的分配和回收是动态的,这2个区域便是垃圾收集器关注点。
一、如何判断对象为垃圾对象
垃圾收集器在对Heap堆区和方法区进行回收时,首先需要确定这些区域的对象哪些可以被回收,哪些暂时还不能被回收,这需要用到判断对象是否存活的算法。
1.引用计数算法
a.算法分析
堆中每个对象实例都有一个引用计数,当一个对象被创建时,就将该对象实例分配给一个变量,该变量计数设置为
1,当任何其它变量被赋值为这个对象的引用时,计数+1,但当一个对象实例的某个引用超过了生命周期或者被设
置为一个新值时,对象实例的引用计数器-1,任何引用计数器为0的对象实例可以被当做垃圾回收集,当一个对象
实例被垃圾收集时,它引用的任何对象实例的引用计数器减1。b.优点
引用计数器收集器可以很快的执行,交织在程序运行中,对程序需要不被长时间打断的实时环境比较好。
c.缺点
无法检测出循环引用,如父对象有一个子对象的引用,子对象反过来引用父对象,那么该引用计数永远不可能为0。
d.代码演示
package com.kevin.jvm.gc;
/**
* @author caonanqing
* @version 1.0
* @description 演示垃圾回收机制的引用计数算法不能检测出循环引用。
* @createDate 2019/7/12
*/
public class Demo {
private Object instance;
public static void main(String[] args) {
Demo d1 = new Demo();
Demo d2 = new Demo();
// 相互引用对方
d1.instance = d2;
d2.instance = d1;
// 将它们设为null,表示指向的对象不可能被引用。
d1 = null;
d2 = null;
// 由于相互引用对方,导致它们的引用计数器无法设置为0,那么垃圾收集器就永远无法回收它们
System.gc();
}
}
2.可达性分析算法
程序将所有应用关系看做一张图,从一个节点GC ROOT开始,往下寻找对应的引用节点,找到这个节点之后继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用的节点,将被判定为是可回收的对象。

可作为GC ROOT的对象
- 虚拟机栈
- 方法区的类属性所引用的对象
- 方法区中常量所引用的对象
- 本地方法栈中引用的对象
二、垃圾回收算法
1.标记-清除算法
算法分析:
标识清除算法采用从根集合(GC ROOTS)进行扫描,对存活的对象进行标记,标记完后,再扫描整个空间中未被
标记的对象,进而进行回收,标记-清除算法不需要进行的对象的移动,只需对不存活的对象进行处理,在存活对
象比较多的情况下非常高效,由于标记-清除算法直接回收不存活的对象,因此会造成内存碎片。
存在的问题:
效率问题
空间问题
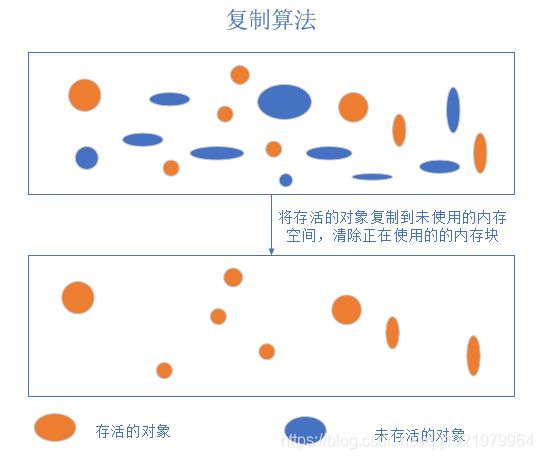
2.复制算法
复制算法的提出是为了解决句柄的开销和内存碎片的问题。
算法分析:
将原有的内存空间分为两块,每次只使用其中的一块,在垃圾回收时候,将正在使用的内存中的存活对象复制到未
使用的内存中,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收复制算法对空间有一定的浪费,只能使用一半的空间。
存在的问题:
空间浪费
应用场景:
复制算法一般都是在新生代使用。
复制算法进行扩展
JVM将Heap内存划分为新生代与老生代,又将新生代划分为Eden(伊甸园)、2块Survivor Space(存活区)
但是JVM在应用复制算法时,并不是按照1:1来划分的,这样太浪费内存空间,一般的JVM是8:1:1
有90%的空间都是可以用来创建对象,剩下10%存放回收后存活的对象。
- 当Eden区满时,会触发young gc,将存活的对象复制到From区,当Eden区再次触发young gc,会扫描Eden区和From区,进行垃圾回收,将存活的对象复制到To区,并将Eden区和Fron区清空。
- 当后续Eden又触发young gc时,会对Eden区和To区进行垃圾回收,将存活的对象复制到From区,并将Eden区和Tao区清空。
- 存活的对象会一直在From和To重复复制,某个对象复制达到15次之后,依旧是存活的,将存入老年代。
注:如果存活的对象比较多,To区的内存不够存放,会借助老年代的空间。
优点:
在存活对象不多时,性能高,能解决内存碎片和标记-清除算法的存在的问题。缺点:
1.会造成一定内存的浪费,但可以适当调整。
2.如果存活对象比较多,复制性能会变得很差。3.标记-整理算法
针对老年代的特点,创建该算法,主要将存活对象移到内存的另一端。
4.分代收集算法
根据存活对象划分几块,一般是分为新生代和老年代,然后根据各个年代的特点制定相应的回收算法。
新生代:每次垃圾回收都有大量对象死去,只有少量存活,选用复制算法比较合理。
老生代:老生代对象存活率较高,没有额外的空间分配对它进行担保,所以必须使用标识-清除或者标记-整理算法回收。
三、垃圾收集器
新生代收集器:
Serial、ParNew、Parallel Scavenge
老年代收集器:
Serial Old、Parallel Old、CMS

1.Serial收集器(复制算法)
新生代单线程收集器,标记-清除都是单线程。
优点:简单高效。
最基本,占用内存小。
使用方式:
-XX:+UseSerialGC2.Serial Old收集器(标记-整理算法)
老年代单线程收集器,Serial收集器的老年代版本。
3.ParNew收集器(复制算法)*
新生代收集器,可以认为是Serial收集器的多线程版本,在多喝CPU环境下有着比Serial更好的表现。
使用方式:
-XX:+UseParallelGC -XX:+UseParallelOldGC4.Parallel Scavenge收集器(复制算法)
新生代收集器,多线程收集器,最求高吞吐量,高效利用CPU,吞吐量一般为99%。
吞吐量:CPU用于运行用户代码的时间与CPU消耗的总时间的比值。
吞吐量=用户线程时间(用户线程时间+GC线程时间)。
XX:MaxGCPauseMillis垃圾收集器停顿时间1
XX:CGTimeRatio吞吐量大小(0,100)
适合后台应用等交互要求不高的场景。
5.Parallel Old收集器(复制算法)
Parallel Scavenge收集器的老年代版本,并行收集器,吞吐量优先。
6.CMS(Concurrent Mark Sweep)收集器(标记-清理算法)
工作过程:
a.初始标记
b.并发标记
c.重新标记
d.并发清理
优点:
a.并发收集
b.低停顿
缺点:
a.占用大量的CPU资源
b.无法处理浮动垃圾
c.出现Concurrent Mode Failure
d.空间碎片
高并发,低停顿,追求最短GC回收停顿时间,CPU占用比较高,响应时间快,停顿时间短,多核CPU追求高响应时间的选择。
使用方式:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC7.G1收集器
优势
a.并行与并发
b.分代收集
c.空间集合
d.可预测的停顿
步骤
a.初始标记
b.并发标记
c.最终标记
d.筛选回收
与CMS比较
内存碎片的产生率大大降低。
使用方式:
-XX:+UseG1GC8.垃圾收集器参数选项
| 选项和默认值 |
描述 |
| -XX:+UseG1GC |
开启G1 |
| -XX:MaxGCPauseMillis=n |
最大GC停顿时间,这是个软目标,JVM将尽可能(但不保证)停顿小于这个时间 |
| -XX:InitiatingHeapOccupancyPercent=n |
堆占用了多少的时候就触发GC,默认为45 |
| -XX:NewRatio=n |
new/old 比,默认为2 |
| -XX:SurvivorRatio=n |
eden/survivor比,默认为8 |
| -XX:MaxTenuringThreshold=n |
新生代到老年代的岁数,默认是15 |
| -XX:ParallelGCThreads=n |
并行GC的线程数,默认值会根据平台不同而不同 |
| -XX:ConcGCThreads=n |
并发GC使用的线程数 |
| -XX:G1ReservePercent=n |
设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险。默认值是 10%。 |
| -XX:G1HeapRegionSize=n |
设置的 G1 区域的大小。值是2的幂,范围是1 MB 到32 MB。目标是根据最小的 Java 堆大小划分出约 2048 个区域。 |
掌握混合垃圾回收:当调优混合垃圾回收时,请尝试以下选项
-XX:InitiatingHeapOccupancyPercent
-XX:G1MixedGCLiveThresholdPercent 和 -XX:G1HeapWastePercent
-XX:G1MixedGCCountTarget 和 -XX:G1OldCSetRegionThresholdPercent9.使用方式:例如使用G1收集器
java -XX:+UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200 -jar d:\Demo.jar