ImageNet Evolution论文笔记(2)
Very deep convolutional networks for large-scale image recognition
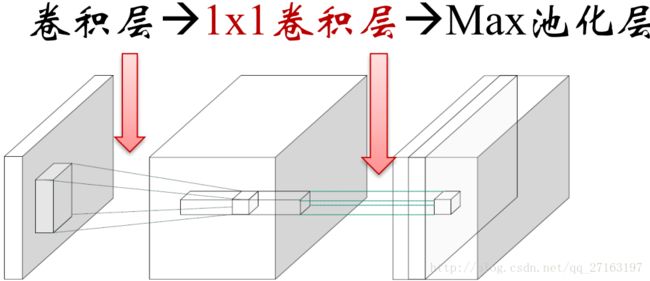
说明: use very small (3 × 3) convolution filters in all layers to increase the depth of the network,VGGNet的拓展性很强,迁移到其他图片数据上的泛化性非常好;VGGNet依然经常被用来提取图像特征,1x1卷积的意义主要在于线性变换,而输入通道数和输出通道数不变,没有发生降维。
The Dataset【ImageNet】:the input to our ConvNets is a fixed-size 224 × 224 RGB image,subtracting the mean RGB value
卷积网络配置
1,Spatial pooling is carried out by five max-pooling layers,Max-pooling is performed over a 2 × 2 pixel window, with stride 2。
2,very small 3 × 3 receptive fields throughout the whole net。

核分解: 7x7核 -> 3个3x3核(由ReLU连接)【参数数量: 49C^2 -> 27C^2】: makes the decision function more discriminative;decrease the number of parameters;减少参数,降低计算,增加深度

1 × 1 convolution is essentially a linear projection onto the space of the same dimensionality。【Network-in-Network网络(NiN):提高CNN的局部感知区域】
训练过程
multi-scale training
1,mini-batch gradient descent【 256,momentum to 0.9】
2,The training was regularised by weight decay (the L2 penalty multiplier set to 5· 10−4) and dropout regularisation for the first two fully-connected layers (dropout ratio set to 0.5).The learning rate was initially set to 10−2, and then decreased by a factor of 10 when the validation set accuracy stopped improving.
3,In total, the learning rate was decreased 3 times。
4,we initialised the first four convolutional layers and the last three fullyconnected layers with the layers of net A
5,sampled the weights from a normal distribution
with the zero mean and 10−2 variance. The biases were initialised with zero
Training image size
在不同的尺度下,训练多个分类器,参数为S,参数的意义就是在做原始图片上的缩放时的短边长度。
1,论文中训练了S=256和S=384两个分类器,其中S=384的分类器的参数使用S=256的参数进行初始化,且将步长调为10e-3。由0.01->0.001
2,另一种方法是直接训练一个分类器,每次数据输入时,每张图片被重新缩放,缩放的短边S随机从[min, max]中选择,使用区间[256,384],网络参数初始化时使用S=384时的参数。
Testing
测试使用如下步骤:
首先进行等比例缩放,短边长度Q大于224,Q的意义与S相同,不过S是训练集中的,Q是测试集中的参数。Q不必等于S,相反的,对于一个S,使用多个Q值进行测试,然后去平均会使效果变好。然后,对测试数据进行测试。(重要)
1.将全连接层转换为卷积层,第一个全连接转换为7×7的卷积,第二个转换为1×1的卷积。
2.Resulting net is applied to the whole image by convolving the filters in each layer with the full-size input. The resulting output feature map is a class score map with the number channels equal to the number of classes, and the variable spatial resolution, dependent on the input image size.
3.Finally, class score map is spatially averaged(sum-pooled) to obtain a fixed-size vector of class scores of the image.
tensorflow slim实现
VGG16
def vgg_16(inputs,num_classes=1000,is_training=True,dropout_keep_prob=0.5,spatial_squeeze=True,scope='vgg_16',fc_conv_padding='VALID',global_pool=False):
"""Oxford Net VGG 16-Layers version D Example.
Note: All the fully_connected layers have been transformed to conv2d layers.
To use in classification mode, resize input to 224x224.
Args:
inputs: 大小为[batch_size, height, width, channels]的张量.
num_classes:
is_training: 训练时为True,测试时为False
dropout_keep_prob: 训练时<1,测试时=1
spatial_squeeze: True除去不必要的维度,变成两维
scope: 自己定义的名称scope
fc_conv_padding: 'SAME','VALID'
global_pool: If True, the input to the classification layer is avgpooled to size 1x1, for any input size
Returns:
net: the output of the logits layer (if num_classes is a non-zero integer),
the input to the logits layer (if num_classes is 0 or None).
end_points: a dict of tensors with intermediate activations.
"""
with tf.variable_scope(scope, 'vgg_16', [inputs]) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d],outputs_collections=end_points_collection):
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
# Use conv2d instead of fully_connected layers.
net = slim.conv2d(net, 4096, [7, 7], padding=fc_conv_padding, scope='fc6')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,scope='dropout6')
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
# Convert end_points_collection into a end_point dict.
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if global_pool:
net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
end_points['global_pool'] = net
if num_classes:
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,scope='dropout7')
net = slim.conv2d(net, num_classes, [1, 1],activation_fn=None,normalizer_fn=None,scope='fc8')
if spatial_squeeze and num_classes is not None:
net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
end_points[sc.name + '/fc8'] = net
return net, end_pointsVGG19
def vgg_19(inputs,num_classes=1000,is_training=True,dropout_keep_prob=0.5,spatial_squeeze=True,scope='vgg_19',fc_conv_padding='VALID',global_pool=False):
"""Oxford Net VGG 19-Layers version E Example.
Note: All the fully_connected layers have been transformed to conv2d layers.
To use in classification mode, resize input to 224x224.
Args:
inputs: 大小为[batch_size, height, width, channels]的张量.
num_classes:
is_training: 训练时为True,测试时为False
dropout_keep_prob: 训练时<1,测试时=1
spatial_squeeze: True出去不必要的维度,变成两维
scope: 自己定义的名称scope
fc_conv_padding: 'SAME','VALID'
global_pool: If True, the input to the classification layer is avgpooled to size 1x1, for any input size
Returns:
net: the output of the logits layer (if num_classes is a non-zero integer),
the input to the logits layer (if num_classes is 0 or None).
end_points: a dict of tensors with intermediate activations.
"""
with tf.variable_scope(scope, 'vgg_19', [inputs]) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
# Collect outputs for conv2d, fully_connected and max_pool2d.
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d],outputs_collections=end_points_collection):
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
# Use conv2d instead of fully_connected layers.
net = slim.conv2d(net, 4096, [7, 7], padding=fc_conv_padding, scope='fc6')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,scope='dropout6')
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
# Convert end_points_collection into a end_point dict.
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if global_pool:
net = tf.reduce_mean(net, [1, 2], keep_dims=True, name='global_pool')
end_points['global_pool'] = net
if num_classes:
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,scope='dropout7')
net = slim.conv2d(net, num_classes, [1, 1],activation_fn=None,normalizer_fn=None,scope='fc8')
if spatial_squeeze:
net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
end_points[sc.name + '/fc8'] = net
return net, end_points