zeppelin Interpreter Yarn 模式 和 doris的 bitmap_union
1,记录一下zeppelin Interpreter Yarn 模式
在上生产部署的路上,需要思考一下各组件的高可用,出现意外情况等情况,所以才发现
zeppelin 存在 Interpreter Yarn 模式:
首先需要声明的是这里的Interpreter Yarn 模式和 Flink的Yarn模式不是一个概念。Flink的Yarn模式是指把Flink集群运行在Yarn环境里,而这里的 Interpreter Yarn 模式是指把 Flink Interpreter 进程运行在 Yarn 环境里。
那为什么我们要引入Interpreter Yarn 模式呢?因为默认情况下 Flink Interpreter 进程和 Zeppelin 是运行在同一台机器上。如果我们是采用 Isolated Per Note 模式,每个Note就会起一个 Flink Interpreter 进程,会对Zeppelin那台机器造成很大的资源压力。Interpreter Yarn 模式就是把 Flink Interpreter进程跑在Yarn环境里,从而减轻 Zeppelin 那台机器的压力。
默认的架构:
我们通过再node1节点安装的zeppelin节点创建了多个 flink interpreter,interpreter创建在server上面。然后任务提交到yarn去执行。
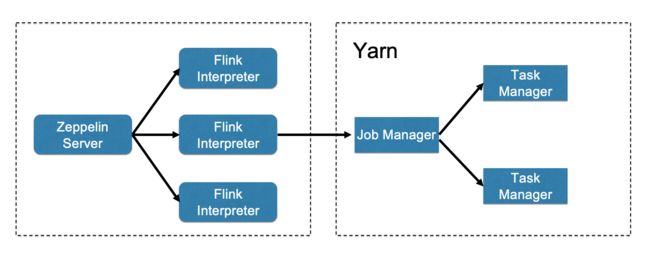
这是Yarn Interpreter 模式的进程布局,flink interpreter是在yarn上,从而减轻了zeppelin server节点的压力
配置
要启动Yarn Interpreter模式,需要做以下几点配置:
- 安装hadoop client (hadoop 2和3都支持)
- 把 $HADOOP_HOME/bin放到环境变量 PATH 里. 因为Zeppelin会调用命令hadoop classpath 获取所有hadoop相关的jar,然后放到CLASSPATH 里
- 在 zeppelin-env.sh 中配置 USE_HADOOP 为true,以及配置 HADOOP_CONF_DIR
除了这几个配置,你还需要可以配置下面这些参数来控制 interpreter process
| Name |
Default Value |
Description |
| zeppelin.interpreter.yarn.resource.memory |
1024 | memory for interpreter process, unit: mb |
| zeppelin.interpreter.yarn.resource.cores |
1 |
cpu cores for interpreter proces |
| zeppelin.interpreter.yarn.queue |
default |
yarn queue name |
视频教程
Flink on Zeppelin 23. Yarn Interpreter 模式.mp4
不能在Flink Job中使用case class的问题
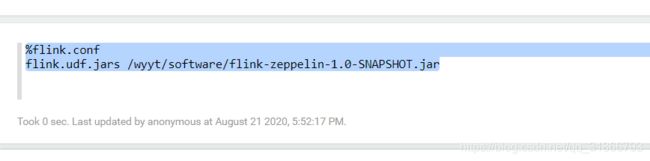
1,记得重启interpreter
%flink.conf
flink.udf.jars /wyyt/software/flink-zeppelin-1.0-SNAPSHOT.jar
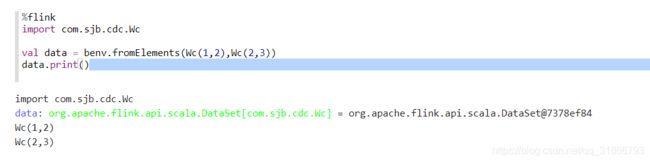
2,代码
3,jar包中的类:

Doris的bitmap_union去重:
业务场景:计算PV,UV
正常的sql语句:
select page_id, count(distinct user_id) from table group by page_id;使用去重:
select page_id, bitmap_union(user_id) from table group by page_id;bitmap_count 函数组合使用可以求得网页的 PV 数据:
select page_id, bitmap_count(bitmap_union(user_id)) from table group by page_id;创建表:
CREATE TABLE IF NOT EXISTS example_db.user_behavior
(
page_id INT COMMENT "page_id",
user_id INT COMMENT "user_id",
)
DUPLICATE KEY(page_id ,user_id )
DISTRIBUTED BY HASH(page_id ) BUCKETS 5
PROPERTIES("replication_num" = "1");
CREATE ROUTINE LOAD example_db.user_behavior_insert_test ON user_behavior
COLUMNS(page_id,user_id)
PROPERTIES
(
"desired_concurrent_number"="3",
"max_batch_interval" = "20",
"max_batch_rows" = "300000",
"max_batch_size" = "209715200",
"strict_mode" = "false",
"format" = "json"
)
FROM KAFKA
(
"kafka_broker_list" = "192.168.12.188:9092",
"kafka_topic" = "user_behavior",
"kafka_partitions" = "0",
"kafka_offsets" = "0"
);
配置物化视图使用:
创建物化视图
create materialized view advertiser_uv as select advertiser, channel, bitmap_union(to_bitmap(user_id)) from advertiser_view_record group by advertiser, channel;
执行查询语句:
SELECT advertiser, channel, bitmap_union_count(to_bitmap(user_id)) FROM advertiser_uv GROUP BY advertiser, channel;
因为版本问题,物化视图不支持:

或者配置文件设置支持物化视图,或者通过命令:
参考:
http://doris.apache.org/master/zh-CN/administrator-guide/config/fe_config.html#%E6%9F%A5%E7%9C%8B%E9%85%8D%E7%BD%AE%E9%A1%B9
命令:
ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true");