Spark全面性能调优详解
1、GC对Spark性能影响的原理图解
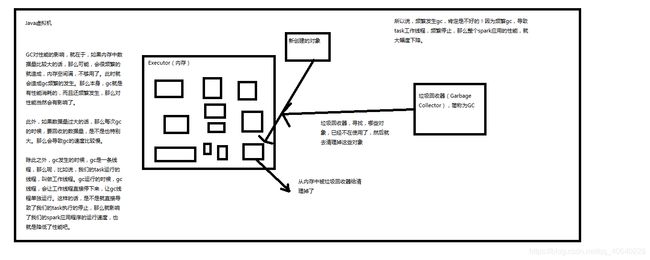
如果在Task执行期间发生大量的Full GC,那么说明年轻代的Eden区域给的空间不够大,可以通过一下方式进行调优:
(1)降低Cache操作占用的内存比例,给Eden等区域更多的内存空间;
(2)给Eden区域分配更大的空间,-Xmn参数即可调节,通常给Eden区域预计大小的4/3,如果使用的是HDFS文件存储且每个Executor有4个Task,然后每个HDFS块解压缩后是原来的三倍左右,每个块大小默认128MB,那么Eden区域的大小可以设置为4 * 3 * 128 * 4/3,一般对于垃圾回收的调优调节Executor的内存比例就可以满足需求了,除非到万不得已且自身对JVM较为了解的情况下可以再对JVM参数进行调节。
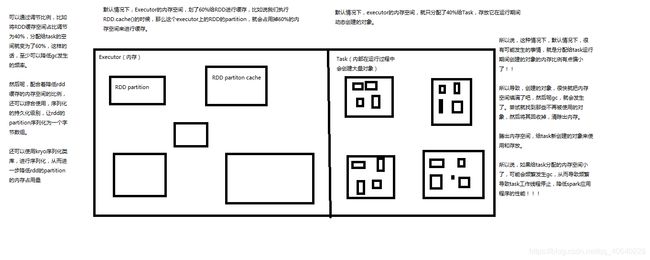
2、调节executor内存比例图解
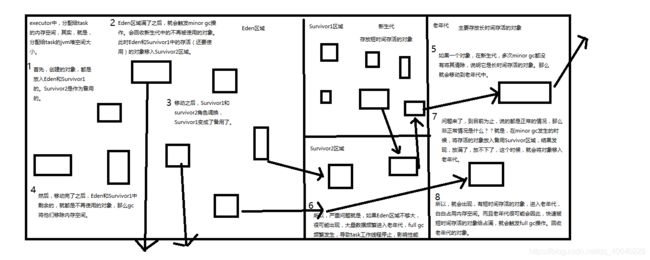
3、JVM minor gc与full gc原理图解
4、提高并行度原理图解

5、广播共享数据原理图解

6、数据本地化原理图解

7、groupByKey原理图解
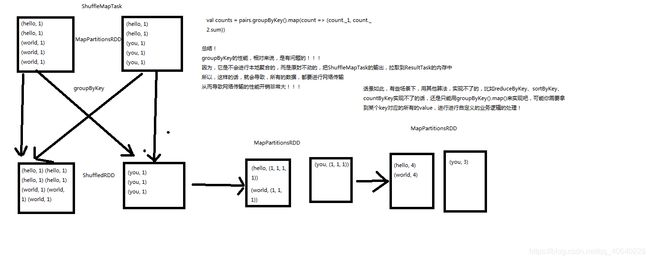
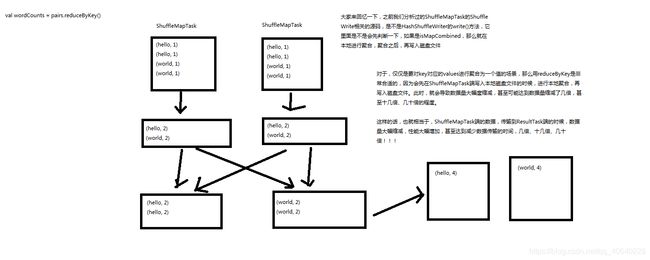
8、reduceByKey原理图解
9、没有开启consolidation机制的性能低下的原理剖析图解
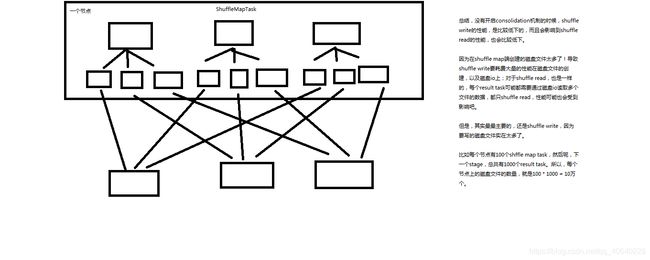
10、开启consolidation机制之后对磁盘io性能的提升的原理图解

11、SparkSQL工作原理剖析图解
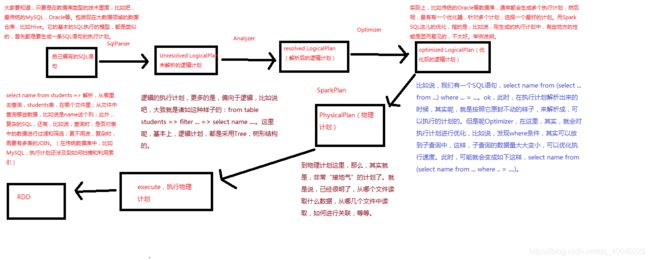
Spark SQL性能调优:
(1)设置Shuffle的并行度:SaprkConf.set( “spark.sql.shuffle.partitions” , “n” );
(2)Hive建表过程中合理选择数据类型;
(3)编写SQL时尽量写明列明,不要使用select * 的形式进行查询;
(4)并行处理计算结果:如果数据量较大,比如超过1000条数据,就不要一次性的collect到Driver端再处理,而是使用foreachPartition算子并行处理数据;
(5)缓存表:对于一条SQL语句的查询结果,如果可能多次使用则可以将表数据进行缓存,使用SQLContext.cacheTable(name)或者DataFrame.cache均可;
(6)广播join表:通过参数spark.sql.autoBroadcastJoinThreshold调节广播表的阈值大小,默认为10MB,该参数表示一个表在Join时,在多大以内会被广播出去以优化性能;
(7)开启钨丝计划:通过参数spark.sql.tungsten.enable开启Tungsten,实现集群自动管理内存;
12、大数据实时计算原理图解

13、Spark Streaming基本工作原理图解
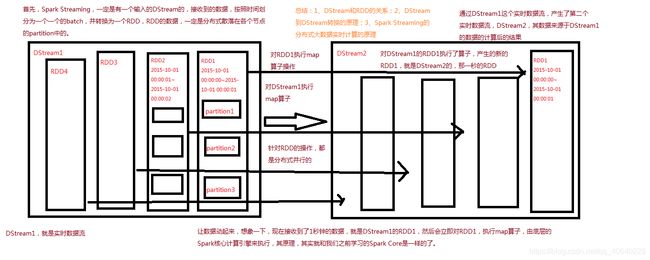
(1)如果使用的是本地模式,至少local[n]中的n设置为2,因为SparkStreaming底层至少有两条线程,一条线程分配给Receiver接收数据并存储在Spark内存中,SparkStreaming的任务也会独占一个CPU;在Master模式下也要求集群节点上有大于等于1个CPU Core,其次每个Executor分配的Core必须 ≥ 1,否则将只能接收数据,不会处理数据;
集群节点上总共拥有的CPU Core必须大于Receiver的数量,一个SparkStreaming程序可以启动多个Receiver,即接收多个数据源;
基于HDFS文件的数据源是没有Receiver的;
(2)DStream中所有计算都是由output操作触发的,如print()、foreachRDD()、saveAsTextFile(prefix,[suffix])、saveAsObjectFile()、saveAsHadoopFile();
(3)对于窗口操作如reduceByWindow、reduceByKeyAndWindow,以及基于状态的操作如updateStateByKey,默认隐式开启了持久化机制,将数据缓存到了内存中,所以不需要手动调用persist()方法,对于通过网络接收数据的输入流,如socket、Kafka、Flume等默认的持久化级别是Memory_only_ser_2;
(4)何时启用CheckPoint机制?
Ⅰ、使用了有状态的transfremation操作,如updateStateByKey、reduceByWindow或reduceByKeyAndWindow,则必须开启CheckPoint机制;
Ⅱ、要保证Driver从失败中恢复 – 元数据CheckPoint需要启用(实现较为复杂,需要改写SparkStreaming程序);
Ⅲ、可以将CheckPoint间隔设为窗口操作滑动时间的5–10倍;
(5)SparkSteaming调优:
Ⅰ、数据接收并行度调优 :通过网络接收数据(Kafka、Flume…)时,会将数据反序列化并存储在Saprk的内存中,如果数据接收称为系统瓶颈那么可以通过创建多个DStream接收不同数据源的数据,以更多的Receiver提升系统的吞吐量;
Ⅱ、调节block interval : 通过参数spark.streaming.blockInterval(默认200s)调节每个block块的接收时长,对于大多数Receiver在将数据保存到BlockManager之前会将数据切分为一个一个的block,而每个batch中block的数量决定了该batch对应的Partitoion数量和对应的Task数量;
Ⅲ、重分区 : DataStream.repartition(n)
Ⅳ、任务启动调优 : 如果每秒钟启动的Task过多,比如每妙启动50个Task,那么分发Task去Worker节点上的Executor的性能开销较大,会导致很难达到毫秒级的响应延迟,可以通过以下方法进行调优:
①Task序列化:使用Kryo序列化机制序列化Task;
②在StandAlone模式下运行Spark程序,减少Task启停时间;
Ⅴ、设置算子或者全局并行度;
Ⅵ、默认情况下接收到输入数据是存储在Executor的内存中的,使用持久化级别是Memory_and_disk_ser_2,数据会进行序列化且有副本,所以可以通过启用Kryo序列化机制进行优化;
Ⅶ、调节batch interval : 如果想让SparkStreaming任务在集群上稳定运行,应该让batch生成之后快速被处理掉,可以通过观察Spark UI上batch处理时间调节相应参数,batch处理时间必须小于batch interval时间;
14、Receiver和cpu core分配说明图解

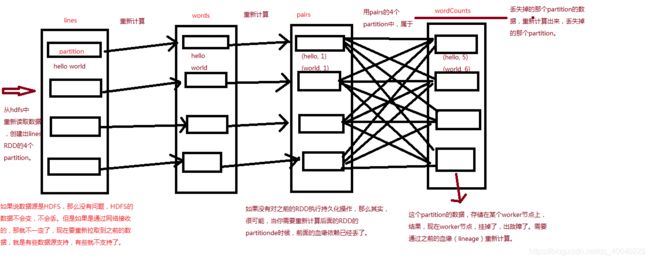
15、RDD的基本容错原理图解