java中的Hashtable概念和基础用法
Hashtable
[1]参考资料:JDK1.8 api文档、Hashtable源代码、百度百科
[2]概念
Hashtable(哈希表) 也可以叫做散列表,是根据关键码值(Key value)而直接进行访问的数据结构,通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
通过代码来理解:
Hashtable
public static void main(String[] args) {
Hashtable ht=new Hashtable();
ht.put("aaa","hash");
ht.put("bbb","table");
System.out.println(ht.get("bbb"));
}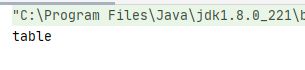
上面代码中通过put(key,value)的方式把值存进对应的键中,再通过put(key)的方式把键中的值拿出来(通过访问key,拿到value,就是通过这种方式加快访问速度)。
[3]Hashtable源代码
创建Hashtable对象
1.public Hashtable()
构造一个新的,空的散列表,默认初始容量(11)和负载因子(0.75)。
通过源代码来理解:
使用Hashtable()时,代码会用 this(11,0.75f) 去指向 Hashtable(int initialCapacity, float loadFactor),可以理解成不填入初始容量和负载因子,代码会给你个默认值(初始容量默认11,负载因子默认0.75)。


注:源代码中都存在着一些方便理解的注释(英文不好只能靠翻译了)。
2.public Hashtable(int initialCapacity)
通过源代码来理解:
使用Hashtable(int initialCapacity)时,代码会用 this(initialCapacity,0.75f) 去指向 Hashtable(int initialCapacity, float loadFactor),可以理解成只填入初始容量,代码会给你个补充一个负载因子的默认值(初始容负载因子默认0.75)。
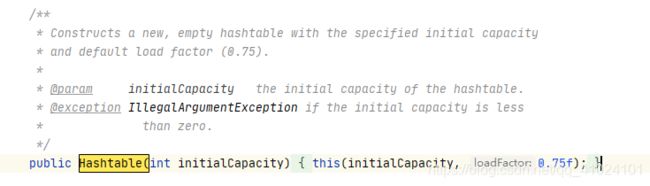

3. public Hashtable(int initialCapacity, float loadFactor)
通过源代码来理解:
使用Hashtable(int initialCapacity, float loadFactor)时,代码会检查初始容量是否小于0、加载因子小于等于0、加载因子是否是NAN,符合则会抛出IllegalArgumentException异常(如果对Float.isNaN()有疑惑可以看看这篇博客:从源码的角度分析 Java 中的 Float.isNaN() )
初始容量为0的话,代码会给初始容量赋值1


知识点: 1.初始容量不能小于0
2.负载因子不能小于等于0
3.负载因子不能是非数字(NaN) 例如:0.0f/0.0f 或者 sqrt(-1)
[4]Hashtable性能(摘自JDK1.8api文档)
- 影响性能的两个参数:初始容量和负载因子,容量是哈希表中的桶数, 初始容量只是创建哈希表时的容量。 请注意,哈希表是打开的 :在“哈希冲突”的情况下,单个存储桶存储多个条目,必须依次搜索。 负载因子是在容量自动增加之前允许哈希表得到满足的度量。
- 默认负载因子(0.75)提供了时间和空间成本之间的良好折衷。 更高的值会减少空间开销,但会增加查询条目的时间成本(这反映在大多数Hashtable操作中,包括get和put )。
-
初始容量控制了浪费空间与需要
rehash操作之间的折中,这是耗时的。 没有rehash如果初始容量大于项Hashtable将其负载因子包含除以最大数量永远不会发生的操作。 然而,设置初始容量太高可能会浪费空间。 -
如果不需要线程安全的实现,建议使用HashMap代替
Hashtable。 如果需要线程安全的并发实现,那么建议使用ConcurrentHashMap代替Hashtable。
[5]Hashtable基础用法
1.赋值
public static void main(String[] args) {
Hashtable ht=new Hashtable();
ht.put("aaa","hash");
ht.put("bbb","table");
System.out.println(ht);
}
2.清除
public static void main(String[] args) {
Hashtable ht=new Hashtable();
ht.put("aaa","hash");
ht.put("bbb","table");
ht.clear();
System.out.println(ht);
}
3.取值
public static void main(String[] args) {
Hashtable ht=new Hashtable();
ht.put("aaa","hash");
ht.put("bbb","table");
System.out.println(ht.get("bbb"));
}