perf性能分析带你具备高级运维的基础能力
1. 小声BIBI
事情的起因是在线上碰到了一次CPU使用率标高导致系统异常,当时使用sar -u命令查看发现system(内核态)数值飙高至40%左右,明显大于平时,此时就需使用perf命令进行性能分析,查找出是哪个服务或进程导致的内存飙高。本文不会介绍perf的实现原理等核心内容,仅做简单的命令介绍。
2. 前期准备
一般我们的机器是没有安装perf的,执行命令:yum install perf -y安装perf,若出现下载较慢的情况,可以百度linux修改yum源为阿里云。
3. 正餐开始
3.1. perf list
首先我们一定会好奇的是perf究竟能监控些什么,我们可以使用perf list命令查看perf所能监控到的性能指标。
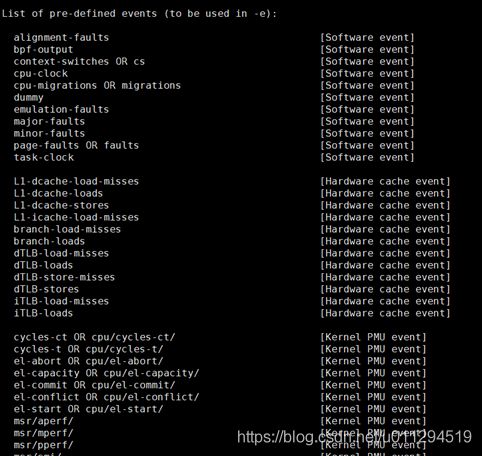
可以看到有许多的CPU事件,虽然到现在我查看的资料中没有一个能够将所有事件都解释的很清楚,但是我们平时常见的并不多。整体上分为了三类,Software event,Hardware cache event,Kernel PMU event。
- Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
- Hardware cache event是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
- Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等。
3.2. perf stat
知道了CPU有哪些性能事件后,我们需要先关注CPU的整体情况,这时perf stat命令恰巧能满足我们的需求。
常用参数:-p: 根据指定进程的pid对该进程进行监控
perf stat执行效果如下:

截图中是对进程号为2812的进程CPU使用率进行监控,首先看到最下面一行的time elapsed,这里输出的是监控总时长。
下面对输出的参数做简要说明:
task-clock:监控时间内程序占用CPU的时间,单位是毫秒。
CPUs utilized:CPU使用率,CPUs utilized= task-clock/(time elapsed*1000)
context-switches:程序在运行过程中发生的上下文切换次数。
cpu-migrations:程序在运行过程中发生的CPU迁移次数,即被调度器从一个CPU转移到另外一个CPU上运行。
page-faults:缺页。指当内存访问时先根据进程虚拟地址空间中的虚拟地址通过MMU查找该内存页在物理内存的映射,没有找到该映射,则发生缺页,然后通过CPU中断调用处理函数,从物理内存中读取。
cycles:CPU时钟周期(我截图中的虚拟机不支持)。说到CPU时钟周期就要简单的讲下指令,CPU回到指令集中选取指令执行,一个指令包含5个步骤:读取指令,指令解码,执行,内存访问,寄存区回写。每个步骤的执行至少都需要一个CPU的时钟周期,CPU中有一个叫功能单元的组件负责处理每个步骤。
Instructions:该进程在这段时间内完成的CPU指令(我截图中的虚拟机不支持)。在网上看到还会有一个重要的相关指标:insns per cycle,表示一个时钟周期内能完成多少个CPU指令。该值越高,表示CPU的性能越好。
branches:这段时间内发生分支预测的次数。比如我们有一个简单的if判断,有10次都是走的true分支,CPU会优先预测后续走的都是true
branches-misses:这段时间内分支预测失败的次数,这个值越小越好。
3.3. perf top
perf stat固然能整体的看到CPU的状态,但是却不能告诉我们到底是我们程序的什么方法导致CPU异常,perf top命令恰巧能满足我们这个需求,perf top命令与我们平时使用的top命令类似,可以实时查看当前系统进程函数占用率整体情况,在这种时候就满足我们所需要的第一感受。
执行效果如下:
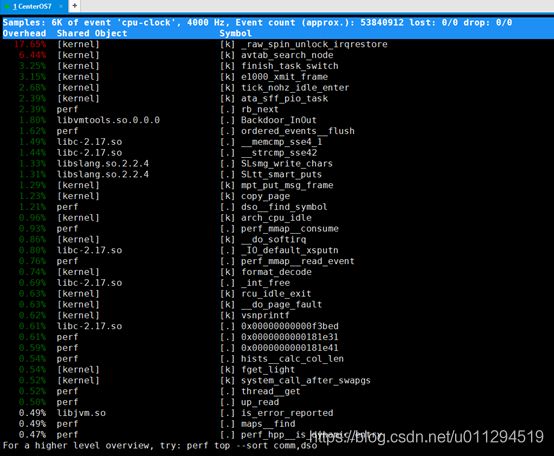
可以看到图中第一行有三个关键字,采样数:Samples,事件:event,事件数量:Event count,所以第一行的意思是cpu-clock事件的数量为6K,总事件数为53840912。
再看第二行,第二行其实是下面表格的表头,参数意义如下:
| Overhead |
该Symbol 的性能事件占所有采样事件中的比例 |
|---|---|
| Shared |
该Symbol所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等 |
| Object |
是动态共享对象的类型。 [.]:表示用户空间的可执行程序、或者动态链接库 [k]:表示内核空间。 |
| Symbol |
符号名,也是函数名。当函数名未知时,用十六进制的地址来表示 |
拿图中示例解析,我们可以看到_raw_spin_unlock_irqrestore的函数占用最多,为17.65%。共享对象为kernel,类型为内核空间。
perf top我经常常用的参数是-p [pid]和-g,因为大部分时间都是我们自己的代码导致cpu使用异常,所以我们可以先使用ps -ef|grep [进程名]来查找出我们进程的PID,然后使用perf top -p [pid]的命令来查看具体是哪个函数占用性能较高。而-g参数可以打印出具体的函数调用关系,这个对我们做具体的函数优化很有必要,这个参数有助于我们定位到到底是程序的那个函数占用CPU较高。
3.4. perf record和perf report
使用perf top我们只能看到当时的情况,且不能留存,大部分事件我们可能需要统计一段时间的CPU情况,这时候perf record就是不二利器,常用用法:perf record -ag -p [PID],回车执行后监控一段时间,然后按CTRL+C会自动生成一个perf.data的报告文件,若想修改输出文件名,可以使用-o参数,例如: perf record -ago 20200603.data -p 3051,然后使用perf report -i 20200603.data来分析输出报告。
因为输出内容与perf top一样,限于篇幅,这里不做赘述。