Ubuntu16.04.4 + 双 NAVDA TitanX + CUDA9.0 + cudnn7.05 + TensorFlow 1.8(1.5.0) + Keras
- 一、安装 Ubunt16.04.4
- 二、安装显卡驱动
- 二*、遇到问题
- 若驱动安装失败,不能进入系统,采用如下两种方法解决。
- 无法进入桌面的问题
- 三、安装 CUDA
- 四、安装 cudnn
- 五、在 bashrc 中添加安装位置
- 六、安装带 Anaconda
- 七、在Anaconda 建立 TensorFlow GPU虚拟环境
- 八、启动 TensorFlow GPU 环境
- 参考文档
准备工作:
(1) 查看显卡型号:
sudo lspci | grep -i nvidia(2) 查看显卡驱动版本号
cat /proc/driver/nvidia/version
一、安装 Ubunt16.04.4
1、显示器HDMI超出频率的黑屏问题
在选择“install ubuntu”的界面,光标上下移动(为啥要上下移动不太清楚),然后按“e”进入编辑模式,然后找到"linux......quiet splash......"这行,在quiet splash 后面添加 nomodeset,即改为“quiet splash nomodeset”,最后按F10,就能进入桌面了。
需要注意的是,这只是暂时的进去,之后重启ubuntu,再次进入也会出现这种问题,所以想要一劳永逸的话,
需要改写grub。
在ubuntu命令行下输入
sudo nano /etc/default/grub
打开grub文件,修改其中的一行为(可以用搜索来定位,其实主要就是在quiet splash 后面加了nomodeset):
GRUBCMDLINELINUXDEFAULT="quiet splash nomodeset"
修改后保存,输入
sudo update-grub
这样,以后再启动ubuntu的时候就不会遇到HDMI的问题了
2、获取root权限
(1)重置 root 密码
sudo passwd root
(2)以root身份登陆,使用 su root 命令可以以 root 身份登录 ubuntu 系统
su root(3)在系统登陆界面以 root 用户登陆
- 切换到 /usr/share/lightdm/lightdm.conf.d 目录,并查看该目录下的文件
cd /usr/share/lightdm/lightdm.conf.d
ls
- 使用 vim 50-unity-greeter.conf 命令打开 50-unity-greeter.conf 文件,在其中添加如下信息
user-session=ubuntu
greeter-show-manual-login=true
all-guest=false
- 使用 vim /root/.profile 命令 打开 .profile 文件,并修改其最后一行为 tty -s && mesg n || true
vim /root/.profile
(4) 重启系统,即可在系统登陆界面切换至 root 用户并进行登录
二、安装显卡驱动
进入命令行界面
Ctrl-Alt+F1安装显卡驱动有三种方式
-直接去nvidia官网下载驱动包安装(网址:http://www.nvidia.cn/Download/index.aspx?lang=cn)
-从PPA中安装(参考博文:http://blog.csdn.net/qiusuoxiaozi/article/details/70195689)
-直接通过安装Cuda8.0带的驱动(网址:https://developer.nvidia.com/cuda-downloads)
查看版本驱动:
sudo apt-cache search nvidia*| Version | 390.67 |
|---|---|
| Release Date | Tue Jun 05, 2018 |
| Operating System | Linux 64-bit |
| Language | Chinese (Simplified) |
| File Size | 78.46 MB |
| NVIDIA TITAN Series |
|---|
| NVIDIA TITAN V, NVIDIA TITAN Xp, NVIDIA TITAN X (Pascal)…… |
1、禁用开源驱动nouveau
首先检测一下,nouveau有没有运行,如果没有返回结果则 nouveau驱动没有被加载
lsmod | grep nouveau
(1)改变blacklist.conf文件的属性,使之可编辑
sudo chmod 666 /etc/modprobe.d/blacklist.conf(2) 用 gedit 软件打开并编辑系统配置文件blacklist.conf
sudo gedit/etc/modprobe.d/blacklist.conf(3)在其中添加下面几行:
# 版本1- 首选
blacklist nouveau #此条必加!禁用nouveau第三方驱动,之后也不需要改回来
options nouveau modeset=0#版本2
blacklist vga16fb
blacklist nouveau
blacklist rivafb
blacklist rivatv
blacklist nvidiafb(4)保存,退出,执行如下命令使配置生效
sudo update-initramfs -u
(5)重启系统,
sudo reboot
(6)至此开源驱动就已被禁用了,可用如下命令进行检查:
lsmod | grep nouveau
如果系统什么也没返回,说明nouveau禁用成功
这种方式也可能不能彻底禁用nouveau,在此基础上可以移除以下文件:nouveau.ko;nouveau.ko.org,此文件一般是隐藏的具体操作:
cd /lib/modules/4.13.0-36-generic/kernel/drivers/gpu/drm/nouveau
sudo rm -rf nouveau.ko
sudo rm -rf nouveau.ko.org再更新
sudo update-initramfs –u
此时重启,再用终端检测一下
lsmod | grep nouveau
没有输出即为禁用成功。
2、关闭UEFI模式
这一步主要是安装驱动的需要。在UEFI模式下安装驱动需要为驱动生成签名,公钥需要存储在linux内核信任的某目录下,关于这方面没有找到什么资料,目前大部分的解决办法都是直接关闭UEFI模式。
UEFI的关闭方法与电脑型号有关,我的戴尔灵越是F2进入BIOS后在Boot标签下选择关闭Secure Boot,之后就可以选择从UEFI模式切换到Legacy模式,其他电脑型号请百度。
华硕 X-99 ii ,启动 - 安全启动菜单 - 操作系统类型 - 选择其他操作系统(关闭Windows UEFI)3、卸载官方驱动 nouveau
# 若前方操作已禁用和卸载 nouveau,忽略此步(Ps:我也没有用过这个命令,不知道效果)
#sudo apt-get --purge remove xserver-xorg-video-nouveau4、清除 NVIDIA 相关的软件
sudo apt-get --purge remove nvidia-* 5、关闭图形环境 X sereve 服务:
sudo /etc/init.d/lightdm stop
# sudo service lightdm stop
之后如果直接死机请重启查看nouveau禁用设置是否正确。正常情况会黑屏,然后按Ctrl+Alt+F1进入字符终端界面,输入用户名和密码通过验证。
6、切换到驱动所在的文件夹,安装Nvidia驱动
#给驱动run文件赋予执行权限
sudo chmod a+x NVIDIA-Linux-x86_64-390.67.run
# –no-x-check 安装驱动时不检查X服务
# –no-nouveau-check 安装驱动时不检查nouveau
# –no-opengl-files也就是不安装opengl
sudo ./NVIDIA-Linux-x86_64-390.67.run -no-x-check -no-nouveau-check -no-opengl-files
执行脚本的三个参数是为了防止接下来循环登录。然后按照步骤进行就可以了,如果提示无法安装32-bit lib不用担心,回车继续就好。
**出现问题
WARNING: Unable to find a suitable destination to install 32-bit compatibility libraries. Your system may not be set up for 32-bit compatibility. 32-bit compatibility files will not be installed; if you wish to install them, re-run the installation and set a valid directory with the --compat32-libdir option.解决办法:运行命令
sudo aptitude install ia32-libs
7、可能出现:
he distribution-provided pre-install script failed!Are you sure you want to continue?
不用管,继续
Would you like to register the kernel module sources with DKMS?This will allow DKMS to auomatically build a new module,if you install a different kernel later
选择“no”
Install Nvidia’s 32-bit compatibility libraries? 选择 No 继续
Would you like to run the nvidia-xconfig utility to automatically update your X configuration file so that the NVIDIA X driver will be user whten you rest…”什么的,选择 No。
黑屏
8、最好再执行命令
sudo apt-get install linux-image-extra-virtual #否则后续可能会出现如下错误提示:
modprobe:ERROR: could not insert'nvidia':Unknown symbolinmodule,or unknown parameter(seedmesg)9、安装完成后重新启动X server服务(重启电脑):
#进入图形界面,字体恢复正常代表N卡驱动安装成功
sudo service lightdm start
# sudo /etc/init.d/lightdm start
10、如果执行以上命令后能够正常进入图形界面,恭喜你安装驱动成功,输入命令:nvidia-smi 查看显卡驱动:
nvidia-smi出现:
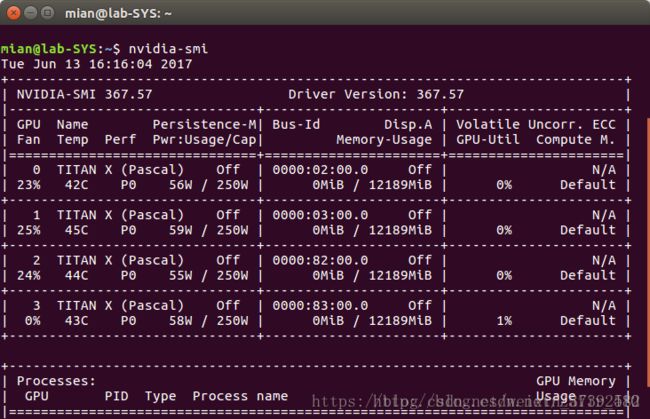
接下来装 CUDA的时候不要再装驱动了。
这个命令也可以查看驱动是否安装成功glxinfo | grep rendering, 显示Yes则成功
输入lspci | grep -i nvidia,查看显卡
显示如下:
01:00:.VGA compatible controller:NVIDIA Corporation Device 1b00(rev a1)
.............可能存在的问题:显卡驱动安装成功,但是版本过低。
二*、遇到问题
若驱动安装失败,不能进入系统,采用如下两种方法解决。
1、进文本tty1模式,输入命令:
sudo /etc/init.d/lightdm stop
sudo ./NVIDIA-Linux-x86_64-390.67.run --uninstall
sudo /etc/init.d/lightdm start卸载已安装的驱动,继续重新尝试。
2、利用PPA的方式,参考是http://blog.csdn.net/qiusuoxiaozi/article/details/70195689。 配置好了PPA(不一定必须配置,看你的源有没有),指令就是:sudo apt-get install nvidia-390
无法进入桌面的问题
如果出现无法进入桌面的问题,这是因为驱动修改了xorg的配置,可执行一下命令:
cd /usr/share/X11/xorg.conf.d/
sudo mv nvidia-drm-outputclass.conf nvidia-drm-outputclass.conf.bak三、安装 CUDA
- 降级 gcc
https://blog.csdn.net/xierhacker/article/details/53035989

1、下载 cuda_9.0.176_384.81_linux.run
2、进入到cuda路径下,更改权限
sudo chmod +x cuda_9.0.176_384.81_linux.run3、按 ctrl+alt+f1进入命令行模式,登录用户后,关闭显卡驱动
命令行内不要用小键盘输入
sudo /etc/init.d/lightdm stop4、运行cuda安装包
sudo sh cuda_9.0.176_384.81_linux.run
# sudo ./cuda_9.0.176_384.81_linux.run 协议可 control + c 跳过,在提示是否安装Nvidia驱动时选择 no (第一个跳出来)安装完成后显示:
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-8.0
Samples: Installed in /home/textminer
Please make sure that
– PATH includes /usr/local/cuda-8.0/bin
– LD_LIBRARY_PATH includes /usr/local/cuda-8.0/lib64, or, add /usr/local/cuda-8.0/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run the uninstall script in /usr/local/cuda-8.0/bin
Please see CUDA_Installation_Guide_Linux.pdf in /usr/local/cuda-8.0/doc/pdf for detailed information on setting up CUDA.
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 361.00 is required for CUDA 8.0 functionality to work.
To install the driver using this installer, run the following command, replacing with the name of this run file:
sudo .run -silent -driver
Logfile is /opt/temp//cuda_install_6583.log5、安装完成后开启图形界面
sudo etc/init.d/lightdm start6、查看 cuda 是否安装成功
cd /usr/local/cuda/samples/1_Utilities/deviceQuery #由自己电脑目录决定
make
sudo ./deviceQueryDrv出现列表显示 cuda 版本,若报错,则为安装 g++
* 降级 gcc
https://blog.csdn.net/xierhacker/article/details/53035989
sudo apt-get install g++7、打开“profile”文件
sudo gedit /etc/profile在末尾处添加(注意不要有空格,不然会报错):
export CUDA_HOME=/usr/local/cuda-9.0
export PATH=/usr/local/cuda-9.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64$LD_LIBRARY_PATH使环境变量生效
source /etc/profile8、sudo reboot重启后,再查看cuda版本,应该就是9.0了,查看GPU运行的进程检测是否安装成功
nvidia-smi四、安装 cudnn
1、进入CUDNN安装包所在目录,执行以下命令:
#sudo dpkg -i runtime包.deb
#sudo dpkg -i developer包.deb
#sudo dpkg -i 代码sample包.deb
sudo dpkg -i libcudnn7_7.0.5.15-1+cuda8.0_amd64.deb
sudo dpkg -i libcudnn7-dev_7.0.5.15-1+cuda8.0_amd64.deb
sudo dpkg -i libcudnn7-doc_7.0.5.15-1+cuda8.0_amd64.debCUDNN的code sample可以用来检查CUDNN和CUDA是否安装成功,执行以下命令:
sudo cp -r /usr/src/cudnn_samples_v7 /home # 复制错来
cd /home/cudnn_samples_v7/mnistCUDNN
sudo make clean
sudo make
sudo ./mnistCUDNN正常情况下执行以上代码会得到Test passed!的结果。如果在make步出错,那么可能gcc需要降级;如果出现CUDA driver version is insufficient for CUDA runtime version,那么或许你的显卡驱动安装失败,或许你之前安装过低版本的nvidia的显卡又没有删掉。
- 降级 gcc
https://blog.csdn.net/xierhacker/article/details/53035989
如果出现报错:
./mnist CUDNN: error while loading shared libraries: libcudart.so.9.0: cannot open……对报错文件进行链接,这里是 libcudart.so.9.0,其他的文件同样方式处理
sudo cp /usr/local/cuda-9.0/lib64/libcudart.so.9.0 /usr/local/lib/libcudart.so.9.0 && sudo ldconfig
再次执行
sudo ./mnistCUDNN显示如下 cudnn 安装完毕
Test passed!五、在 bashrc 中添加安装位置
1、安装位置应该被添加到 bashrc 文件中,以便系统下一次知道如何找到这些用于 CUDA 的文件。使用下面的命令打开 bashrc 文件:
sudo gedit ~/.bashrc2、文件打开后,添加下面两行到文件的末尾:
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
export CUDA_HOME=/usr/local/cudasource /.bashrc六、安装带 Anaconda
1、自定义安装 Anaconda(安装在根目录时遇到了权限问题)
bash Anaconda3-4.2.0-Linux-x86_64.sh
#以下为自定义安装路径,路径为 PATH
bash Anacondaxxxxx.bash -p PATH -u2、conda 报错,添加环境变量至 profile
sudo gedit /etc/profile
#添加如下
export PATH=/root/anaconda3/bin:$PATH
#在 .bashrc 中的环境变量在安装 anaconda 时已经自动配置好了,如果没有如上命令手动添加七、在Anaconda 建立 TensorFlow GPU虚拟环境
# 几个命令
conda info --envs 查看虚拟环境
conda remove -name py36 --all # 删除py36 虚拟环境
source activate py36
source deactivate py361、conda create --name tensorflow-gpu python=3.5 anaconda
| 命令 | 说明 |
|---|---|
| conda create | 建立虚拟环境 |
| –name tensorflow-gpu | 虚拟环境的名称是 tensorflow-gpu |
| python=3.5 | Python版本是3.5(暂不支持更高版本) |
| anaconda | 加入此命令选项,建立虚拟环境时,也会同时安装其他 Python 软件包,例如 Jupyter Notebook、NumPy、SciPy、Matplotlib、Pandas,用于进行数据分析 |
2、启用 TensorFlow GPU 虚拟环境
source activate tensorflow-gpu3、安装 TensorFlow GPU 版本
pip install tensorflow-gpu==1.8.0 # 216MBsudo gedit ~/.condarc # 查看 conda 下载源4、安装 Keras
pip install keras八、启动 TensorFlow GPU 环境
1、启动TensorFLow GPU
因此是在虚拟环境中配置的 tensorflow,因此在使用前需要开启虚拟环境
source activate tensorflow-gpu# 开启 jupyter book
jupyter notebook --allow-root2、不使用时,关闭 TensorFlow GPU 环境
source deactivate3、测试1
import tensorflow as tf
# 使用第一块显卡
with tf.Session() as sess:
with tf.device("/gpu:0"):
matrix1=tf.constant([[3.,3.]])
matrix2=tf.constant([[2.],[2.]])
product=tf.matmul(matrix1,matrix2)
result=sess.run(product)
print(result)
# 使用第二块显卡
with tf.Session() as sess:
with tf.device("/gpu:1"):
matrix1=tf.constant([[6.,6.]])
matrix2=tf.constant([[3.],[2.]])
product=tf.matmul(matrix1,matrix2)
result=sess.run(product)
print(result)
控制台显示如下:
2018-07-17 16:46:47.731215: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1195] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: TITAN X (Pascal), pci bus id: 0000:01:00.0, compute capability: 6.1)
2018-07-17 16:46:47.731263: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1195] Creating TensorFlow device (/device:GPU:1) -> (device: 1, name: TITAN X (Pascal), pci bus id: 0000:02:00.0, compute capability: 6.1)
4、测试2
采用keras搭建如下网络结构:
| Layer (type) | Output Shape | Param # |
|---|---|---|
| conv2d_1 (Conv2D) | (None, 32, 32, 32) | 896 |
| dropout_1 (Dropout) | (None, 32, 32, 32) | 0 |
| conv2d_2 (Conv2D) | (None, 32, 32, 32) | 9248 |
| dropout_2 (Dropout) | (None, 32, 32, 32) | 0 |
| max_pooling2d_1 (MaxPooling2 | (None, 16, 16, 32) | 0 |
| conv2d_3 (Conv2D) | (None, 16, 16, 64) | 18496 |
| dropout_3 (Dropout) | (None, 16, 16, 64) | 0 |
| max_pooling2d_2 (MaxPooling2 | (None, 8, 8, 64) | 0 |
| flatten_1 (Flatten) | (None, 4096) | 0 |
| dropout_4 (Dropout) | (None, 4096) | 0 |
| dense_1 (Dense) | (None, 1024) | 4195328 |
| dropout_5 (Dropout) | (None, 1024) | 0 |
| dense_2 (Dense) | (None, 10) | 10250 |
| – | – | – |
| Total params: 4,234,218 | ||
| Trainable params: 4,234,218 | ||
| Non-trainable params: 0 |
每批次训练 16 组数据(Ps:32、64、128……都会出先 OOM 报错)
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
40000/40000 [==============================] - 21s 533us/step - loss: 1.4742 - acc: 0.4668 - val_loss: 1.2316 - val_acc: 0.5898
Epoch 2/10
40000/40000 [==============================] - 21s 530us/step - loss: 1.1186 - acc: 0.6036 - val_loss: 1.0766 - val_acc: 0.6352
Epoch 3/10
40000/40000 [==============================] - 21s 531us/step - loss: 0.9688 - acc: 0.6544 - val_loss: 0.9124 - val_acc: 0.6946
Epoch 4/10
40000/40000 [==============================] - 21s 531us/step - loss: 0.8663 - acc: 0.6948 - val_loss: 0.9523 - val_acc: 0.6878
Epoch 5/10
40000/40000 [==============================] - 21s 530us/step - loss: 0.7795 - acc: 0.7266 - val_loss: 0.8278 - val_acc: 0.7199
Epoch 6/10
40000/40000 [==============================] - 21s 533us/step - loss: 0.7063 - acc: 0.7530 - val_loss: 0.8164 - val_acc: 0.7260
Epoch 7/10
40000/40000 [==============================] - 22s 553us/step - loss: 0.6489 - acc: 0.7741 - val_loss: 0.7907 - val_acc: 0.7358
Epoch 8/10
40000/40000 [==============================] - 22s 553us/step - loss: 0.5983 - acc: 0.7906 - val_loss: 0.7980 - val_acc: 0.7284
Epoch 9/10
40000/40000 [==============================] - 22s 544us/step - loss: 0.5601 - acc: 0.8039 - val_loss: 0.8116 - val_acc: 0.7191
Epoch 10/10
40000/40000 [==============================] - 22s 549us/step - loss: 0.5161 - acc: 0.8193 - val_loss: 0.7913 - val_acc: 0.7317
参考文档
(1)【profile /bashrc 环境变量配置文件】ubuntu15和16下安装cuda以及caffe深度学习环境 https://blog.csdn.net/windforever2014/article/details/52440392
(2)Ubuntu 16.04 上安装 CUDA 9.0 详细教程 https://blog.csdn.net/QLULIBIN/article/details/78714596
(3)Linux下CUDA+CUDNN+TensorFlow安装笔记 ,https://blog.csdn.net/m0_37924639/article/details/78785699
(4)Ubuntu 16.04 + Nvidia 显卡驱动 + Cuda 8.0 (问题总结 + 解决方案),https://blog.csdn.net/zafir_410/article/details/73188228?utm_source=itdadao&utm_medium=referral
(5)Ubuntu 命令行界面login incorrect 问题 https://blog.csdn.net/sea_sky_cloud/article/details/75267817
(6)在Linux中永久设置Anaconda环境变量的方法 https://www.linuxidc.com/Linux/2016-08/134259.htm
(7)Ubuntu16.04下Anaconda安装完成后conda:找不到命令 https://blog.csdn.net/xianglao1935/article/details/80510494
(8)《TensorFlow + Keras 深度学习人工智能实践应用》 – 第20章,TensorFlow GPU 版本的安装