学习java的第五周学习总结
VI. protected void finalize() throws Throwable //了解(面试题中可能有坑)
当对象被判定为垃圾对象时,由JVM自动调用此方法,用以标记垃圾对象,进入回收队列。
垃圾对象:没有有效引用指向此对象时,为垃圾对象。
垃圾回收: 由GC销毁垃圾对象,释放数据存储空间。
自动回收机制:JVM的内存耗尽,一次性回收所有垃圾对象。
手动回收机制:使用System.gc(); 通知JVM执行垃圾回收。
附加源代码:Windows --> Preferences --> Java --> Installed JREs --> 选中JRE --> Edit --> xxx/rt.jar --> Source Attachment --> External Location --> External File 选中src.zip
三、包装类:
-
概念:
I. 基本类型所对应的引用类型
II. Object可统一所有数据,包装类的默认值为null
III. 包装类中实际上就是持有了一个基本类型的属性,作为数据的存储空间(Byte中有一个byte属性),还提供了常用的转型方法,以及常量,
既可以存储值,又具备了一系列的转型方法和常用常量,比直接使用基本类型的功能更强大。
IV. 包装类型中提供了若干转型的方法,可以让自身类型与其他包装类型、基本类型、字符串相互之间进行转换。 -
转型方法:
I. 8种包装类型中,有6种是数字型(Byte、Short、Integer、Long、Float、Double),继承自java.lang.Number父类。
II. java.lang.Number父类为所有子类分别提供了6个转型的方法,将自身类型转换成其他数字型。
byteValue();
shortValue();
intValue();
longValue();
floatValue();
doubleValue();
III. parseXXX(String s) 静态转型方法,8种包装类型都有
parseByte(“123”);
parseShort(“123”);
parseInt(“123”);
parseDouble(“123.45”);
…
IV. valueOf(基本类型)、valueOf(字符串类型),静态转型方法,8种包装类型都有
Byte b1 = Byte.valueOf( (byte)10 );
Byte b2 = Byte.valueOf( “20” );
V. 注意:在使用字符串构建包装类型对象时,要保证类型的兼容,否则产生NumberFormatException。
VI. JDK5之后,提供自动装箱、拆箱,简化使用包装类的编程过程
Byte b4 = 40;//自动装箱,将基本类型直接赋值给包装类型
byte b5 = b4;//自动拆箱,将包装类型的值,直接赋值给基本类型
VII. 自动装箱时,会调用valueOf方法,Byte、Short、Integer、Long,四种整数包装类型都提供了对应的cache缓冲区,将常用的256个数字提前创建对象并保存在数组中,实现复用。即在区间的复用已有对象,在区间外创建新对象。
自动拆箱,会调用xxxValue方法,看什么类型接受就调用哪个方法
String类
1.String类基础概念
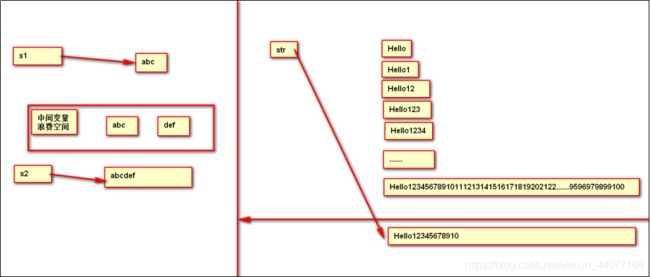
字符串是常量,创建之后不可改变。
字符串字面值存储在字符串池中,可以共享。
Strings= “Hello”;产生-一个对象,字符串池中存储。
String s = new String(“Hello”); //产生两个对象,堆、池各存储-一个。而s存储的是堆中的地址。
举例:
String a =”abc”;
a =”def”;
这种情况不是字符串改变了,而是变量a指向了另一个字符串地址
反编译 javap -verbose 字节码文件名(.class文件) > 字节码文件名.bytecode
String s1 = “abc”+”def”;这样和String s1 =”abcdef”一样就只创建一个对象
String s4 = new String(“Word”);//如果word首次出现并且直接赋值的,他是在String构造里面直接赋值的,所以他会在堆中和池中分别创建(查看String的构造源码)
String s1 = “abc”;//1.直接声明&&2.首次出现(保存在池中)
String s2 = s1 + "def";//自动优化 StringBuilder.toString()得到的一个 new String(xxx,xxx,xxx) 堆new的是拼接好了的字符串所以def不会在池中创建
//s2.intern();
String s3 = "abcdef";//1.直接声明&&2.首次出现(保存在池中)
s2.intern();//手工向池中保存s2指向的字符串失败了
System.out.println(s2 == s3);//比较 s2指向堆中的"abcdef" s3所指向的池中的"abcdef"
String s4 = s2;//指向堆中,可变
String s5 = s2.intern();//指向池中,不变(如果池中已有s2所指向的"abcdef"的话,则返回池中的内容一样的常量的地址)
System.out.println(s4 == s3);
2.String类常用方法
public char charAt(int index) :根据下标获取字符。
public boolean contains(tring str) :判断当前字符串中是否包含str。
public charD toCharArray( ):将字符串转换成数组。
public int indexOf(String str) :查找str首次出现的下标,存在,则返回该下标;不存在,则返回-1。
public int lastIndexOf(String str) :查找字符串在当前字符串中最后一次出现的 下标索引。
public int length():返回字符串的长度。
public String trim():去掉字符串前后的空格。
public String toUpperCase():将小写转成大写。
public boolean endWith(String str):判断字符串是否以str结尾。
public String replace(char oldChar, char newChat);将旧字符串替换成新字符串
public String] split(String str):根据str做拆分。
System.out.println( upperHi.equals(lowerHi) );//内容必须完全相同,包括大小写
System.out.println( upperHi.equalsIgnoreCase(lowerHi) );//内容必须完全相同,忽略大小写
String str = text.substring(0, 5); //获取字符串text的子串,传入的参数为截取开始下标和结束下标,截取的内容是开始下标值和结束下标值的前一个(左包右不包)
VI. protected void finalize() throws Throwable //了解(面试题中可能有坑)
当对象被判定为垃圾对象时,由JVM自动调用此方法,用以标记垃圾对象,进入回收队列。
垃圾对象:没有有效引用指向此对象时,为垃圾对象。
垃圾回收: 由GC销毁垃圾对象,释放数据存储空间。
自动回收机制:JVM的内存耗尽,一次性回收所有垃圾对象。
手动回收机制:使用System.gc(); 通知JVM执行垃圾回收。
附加源代码:Windows --> Preferences --> Java --> Installed JREs --> 选中JRE --> Edit --> xxx/rt.jar --> Source Attachment --> External Location --> External File 选中src.zip
三、包装类:
-
概念:
I. 基本类型所对应的引用类型
II. Object可统一所有数据,包装类的默认值为null
III. 包装类中实际上就是持有了一个基本类型的属性,作为数据的存储空间(Byte中有一个byte属性),还提供了常用的转型方法,以及常量,
既可以存储值,又具备了一系列的转型方法和常用常量,比直接使用基本类型的功能更强大。
IV. 包装类型中提供了若干转型的方法,可以让自身类型与其他包装类型、基本类型、字符串相互之间进行转换。 -
转型方法:
I. 8种包装类型中,有6种是数字型(Byte、Short、Integer、Long、Float、Double),继承自java.lang.Number父类。
II. java.lang.Number父类为所有子类分别提供了6个转型的方法,将自身类型转换成其他数字型。
byteValue();
shortValue();
intValue();
longValue();
floatValue();
doubleValue();
III. parseXXX(String s) 静态转型方法,8种包装类型都有
parseByte(“123”);
parseShort(“123”);
parseInt(“123”);
parseDouble(“123.45”);
…
IV. valueOf(基本类型)、valueOf(字符串类型),静态转型方法,8种包装类型都有
Byte b1 = Byte.valueOf( (byte)10 );
Byte b2 = Byte.valueOf( “20” );
V. 注意:在使用字符串构建包装类型对象时,要保证类型的兼容,否则产生NumberFormatException。
VI. JDK5之后,提供自动装箱、拆箱,简化使用包装类的编程过程
Byte b4 = 40;//自动装箱,将基本类型直接赋值给包装类型
byte b5 = b4;//自动拆箱,将包装类型的值,直接赋值给基本类型
VII. 自动装箱时,会调用valueOf方法,Byte、Short、Integer、Long,四种整数包装类型都提供了对应的cache缓冲区,将常用的256个数字提前创建对象并保存在数组中,实现复用。即在区间的复用已有对象,在区间外创建新对象。
自动拆箱,会调用xxxValue方法,看什么类型接受就调用哪个方法
String类
1.String类基础概念
字符串是常量,创建之后不可改变。
字符串字面值存储在字符串池中,可以共享。
Strings= “Hello”;产生-一个对象,字符串池中存储。
String s = new String(“Hello”); //产生两个对象,堆、池各存储-一个。而s存储的是堆中的地址。
举例:
String a =”abc”;
a =”def”;
这种情况不是字符串改变了,而是变量a指向了另一个字符串地址
反编译 javap -verbose 字节码文件名(.class文件) > 字节码文件名.bytecode
String s1 = “abc”+”def”;这样和String s1 =”abcdef”一样就只创建一个对象
String s4 = new String(“Word”);//如果word首次出现并且直接赋值的,他是在String构造里面直接赋值的,所以他会在堆中和池中分别创建(查看String的构造源码)
String s1 = “abc”;//1.直接声明&&2.首次出现(保存在池中)
String s2 = s1 + "def";//自动优化 StringBuilder.toString()得到的一个 new String(xxx,xxx,xxx) 堆new的是拼接好了的字符串所以def不会在池中创建
//s2.intern();
String s3 = "abcdef";//1.直接声明&&2.首次出现(保存在池中)
s2.intern();//手工向池中保存s2指向的字符串失败了
System.out.println(s2 == s3);//比较 s2指向堆中的"abcdef" s3所指向的池中的"abcdef"
String s4 = s2;//指向堆中,可变
String s5 = s2.intern();//指向池中,不变(如果池中已有s2所指向的"abcdef"的话,则返回池中的内容一样的常量的地址)
System.out.println(s4 == s3);
2.String类常用方法
public char charAt(int index) :根据下标获取字符。
public boolean contains(tring str) :判断当前字符串中是否包含str。
public charD toCharArray( ):将字符串转换成数组。
public int indexOf(String str) :查找str首次出现的下标,存在,则返回该下标;不存在,则返回-1。
public int lastIndexOf(String str) :查找字符串在当前字符串中最后一次出现的 下标索引。
public int length():返回字符串的长度。
public String trim():去掉字符串前后的空格。
public String toUpperCase():将小写转成大写。
public boolean endWith(String str):判断字符串是否以str结尾。
public String replace(char oldChar, char newChat);将旧字符串替换成新字符串
public String] split(String str):根据str做拆分。
System.out.println( upperHi.equals(lowerHi) );//内容必须完全相同,包括大小写
System.out.println( upperHi.equalsIgnoreCase(lowerHi) );//内容必须完全相同,忽略大小写
String str = text.substring(0, 5); //获取字符串text的子串,传入的参数为截取开始下标和结束下标,截取的内容是开始下标值和结束下标值的前一个(左包右不包)
VI. protected void finalize() throws Throwable //了解(面试题中可能有坑)
当对象被判定为垃圾对象时,由JVM自动调用此方法,用以标记垃圾对象,进入回收队列。
垃圾对象:没有有效引用指向此对象时,为垃圾对象。
垃圾回收: 由GC销毁垃圾对象,释放数据存储空间。
自动回收机制:JVM的内存耗尽,一次性回收所有垃圾对象。
手动回收机制:使用System.gc(); 通知JVM执行垃圾回收。
附加源代码:Windows --> Preferences --> Java --> Installed JREs --> 选中JRE --> Edit --> xxx/rt.jar --> Source Attachment --> External Location --> External File 选中src.zip
三、包装类:
-
概念:
I. 基本类型所对应的引用类型
II. Object可统一所有数据,包装类的默认值为null
III. 包装类中实际上就是持有了一个基本类型的属性,作为数据的存储空间(Byte中有一个byte属性),还提供了常用的转型方法,以及常量,
既可以存储值,又具备了一系列的转型方法和常用常量,比直接使用基本类型的功能更强大。
IV. 包装类型中提供了若干转型的方法,可以让自身类型与其他包装类型、基本类型、字符串相互之间进行转换。 -
转型方法:
I. 8种包装类型中,有6种是数字型(Byte、Short、Integer、Long、Float、Double),继承自java.lang.Number父类。
II. java.lang.Number父类为所有子类分别提供了6个转型的方法,将自身类型转换成其他数字型。
byteValue();
shortValue();
intValue();
longValue();
floatValue();
doubleValue();
III. parseXXX(String s) 静态转型方法,8种包装类型都有
parseByte(“123”);
parseShort(“123”);
parseInt(“123”);
parseDouble(“123.45”);
…
IV. valueOf(基本类型)、valueOf(字符串类型),静态转型方法,8种包装类型都有
Byte b1 = Byte.valueOf( (byte)10 );
Byte b2 = Byte.valueOf( “20” );
V. 注意:在使用字符串构建包装类型对象时,要保证类型的兼容,否则产生NumberFormatException。
VI. JDK5之后,提供自动装箱、拆箱,简化使用包装类的编程过程
Byte b4 = 40;//自动装箱,将基本类型直接赋值给包装类型
byte b5 = b4;//自动拆箱,将包装类型的值,直接赋值给基本类型
VII. 自动装箱时,会调用valueOf方法,Byte、Short、Integer、Long,四种整数包装类型都提供了对应的cache缓冲区,将常用的256个数字提前创建对象并保存在数组中,实现复用。即在区间的复用已有对象,在区间外创建新对象。
自动拆箱,会调用xxxValue方法,看什么类型接受就调用哪个方法
String类
1.String类基础概念
字符串是常量,创建之后不可改变。
字符串字面值存储在字符串池中,可以共享。
Strings= “Hello”;产生-一个对象,字符串池中存储。
String s = new String(“Hello”); //产生两个对象,堆、池各存储-一个。而s存储的是堆中的地址。
举例:
String a =”abc”;
a =”def”;
这种情况不是字符串改变了,而是变量a指向了另一个字符串地址
反编译 javap -verbose 字节码文件名(.class文件) > 字节码文件名.bytecode
String s1 = “abc”+”def”;这样和String s1 =”abcdef”一样就只创建一个对象
String s4 = new String(“Word”);//如果word首次出现并且直接赋值的,他是在String构造里面直接赋值的,所以他会在堆中和池中分别创建(查看String的构造源码)
String s1 = “abc”;//1.直接声明&&2.首次出现(保存在池中)
String s2 = s1 + "def";//自动优化 StringBuilder.toString()得到的一个 new String(xxx,xxx,xxx) 堆new的是拼接好了的字符串所以def不会在池中创建
//s2.intern();
String s3 = "abcdef";//1.直接声明&&2.首次出现(保存在池中)
s2.intern();//手工向池中保存s2指向的字符串失败了
System.out.println(s2 == s3);//比较 s2指向堆中的"abcdef" s3所指向的池中的"abcdef"
String s4 = s2;//指向堆中,可变
String s5 = s2.intern();//指向池中,不变(如果池中已有s2所指向的"abcdef"的话,则返回池中的内容一样的常量的地址)
System.out.println(s4 == s3);
2.String类常用方法
public char charAt(int index) :根据下标获取字符。
public boolean contains(tring str) :判断当前字符串中是否包含str。
public charD toCharArray( ):将字符串转换成数组。
public int indexOf(String str) :查找str首次出现的下标,存在,则返回该下标;不存在,则返回-1。
public int lastIndexOf(String str) :查找字符串在当前字符串中最后一次出现的 下标索引。
public int length():返回字符串的长度。
public String trim():去掉字符串前后的空格。
public String toUpperCase():将小写转成大写。
public boolean endWith(String str):判断字符串是否以str结尾。
public String replace(char oldChar, char newChat);将旧字符串替换成新字符串
public String] split(String str):根据str做拆分。
System.out.println( upperHi.equals(lowerHi) );//内容必须完全相同,包括大小写
System.out.println( upperHi.equalsIgnoreCase(lowerHi) );//内容必须完全相同,忽略大小写
String str = text.substring(0, 5); //获取字符串text的子串,传入的参数为截取开始下标和结束下标,截取的内容是开始下标值和结束下标值的前一个(左包右不包)
BigDecimal
位置: java.math包中。
作用:精确计算浮点数。
创建方式: BigDecimal bd=new BigDecimal(“1.0");
方法:
BigDecimal add(BigDecimal bd) 加
BigDecimal subtract(BigDecimal bd) 减
BigDecimal multiply(BigDecimal bd) 乘
BigDecimal divide(BigDecimal bd) 除
BigDecimal除法
除法: BigDecimal(BigDecimal bd,int scal,RoundingMode mode)
参数scal :指定精确到小数点后几位。
参数mode :
指定小数部分的取舍模式,通常采用四舍五入的模式,
取值为BigDecimal.ROUND_HALF_UP。
集合:
-
Collection体系集合:
I. Collection父接口:该体系结构的根接口,代表一组对象,称为“集合”,每个对象都是该集合的“元素”。
II. List接口的特点:有序、有下标、元素可重复。
III.Set接口的特点:无序、无下标、元素不可重复。
IV. Collection接口方法
特点:代表- -组任意类型的对象,无序、无下标。
方法:
boolean add(Object obj) //添加-一个对象。
boolean addAll(Collection c) //将一个集合中的所有对象添加到此集合中。
void clear() /清空此集合中的所有对象。
boolean contains(Object o) //检查此集合中是否包含o对象
boolean equals(Object o) //比较此集合是否与指定对象相等。
boolean isEmpty() /判断此集合是否为空
boolean remove(Object o) //在此集合中移除o对象,也可以传入下标
int size() //返回此集合中的元素个数。
Object[] toArray() //将此集合转换成数组。 -
List子接口:
I. 特点:有序、有下标、元素可以重复。
II. 继承可父接口提供的共性方法,同时定义了一些独有的与下标相关的操作方法。
III.接口中的方法
特点:有序、有下标、元素可以重复。
方法:
void add(int index, Object o) //在index位置插入对象o。
boolean addAll(int index, Collection c) //将一个集合中的元素添加到此集合中的index位置。
Object get(int index) //返回集合中指定位置的元素。
List subList(int fromIndex, int toIndex) //返回fromIndex和toIndex之间的集合元素。 -
List实现类:
I. JDK8的ArrayList,实际初始长度是0(开始是0,扩容之后就变成了10了)
II. 首次添加元素时,需要实际分配数组空间,执行数组扩容操作
III.真正向数组中插入数据,(Lazy懒)用的时候再创建,或再加载,有效的降低无用内存的占用 -
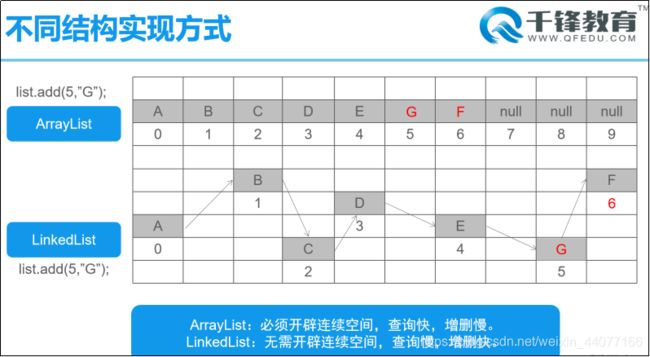
ArrayList:
I. 数组结构存储,查询快,增删慢。//注册(1次)-> 查询(N次)
II. JDK 1.2发布,执行效率快,线程不安全。 -
Vector:
I. 数组结构存储,查询快,增删慢。
II. JDK 1.0发布,执行效率慢,线程安全。 -
LinkedList:
I. 链表(链接列表)结构存储,查询慢、增删快。
II. 了解:Queue接口:队列、双端队列
III. 了解:栈结构Last In First Out(后进先出)
IV. 了解:队列结构First In First Out(先进先出)
万物皆对象,一切皆工具
7. 泛型集合【重点-解决应用问题】:
I. 概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
II. 特点:
1). 编译时即可检查,而非运行时抛出异常。
2). 访问时,不必类型转换(拆箱)。
3). 不同泛型之间引用不能相互赋值,泛型不存在多态。
- 泛型:高级类别的知识,熟练应用,需要时间、经验的积累(常用名称:E = Element / T = Type / K = Key / V = Value)
I. 概念:约束-规范类型
II. 泛型的场景:
1). 定义泛型:
A). 实例泛型:
a). 类:创建对象时,为类所定义的泛型,进行参数化赋值
b). 接口:实现接口时,为接口所定义的泛型,进行参数化赋值
B). 静态泛型:
a). 定义在方法的返回值类型前面:、、
2). 定义在方法的形参列表当中:、、,不支持使用&
- Collections工具类:
概念:集合工具类,定义了除了存取以外的集合常用方法。
I. public static> void sort(List list) //排序,要求:必须实现Comparable,必须可与自身类型比,以及父类类型比
II. public static void reverse(List list) //反转、倒置元素
III. public static void shuffle(List list) //随机重置顺序
经验:一级目标能看懂、能调用,二级目标能定义、能设计
-
Set子接口:
I. 特点:无序、无下标、元素不可重复(当插入新元素时,如果新元素与已有元素进行equals比较,结果为true时,则拒绝新元素的插入)
II. 方法:全部继承自Collection中的方法 -
foreach循环:
for(数据类型 变量名 : 容器名称){ //可遍历集合或数组(常用在无序集合上)
} -
Set接口实现类:
I. HashSet【重要】:
1). HashSet的底层使用的HashMap类,即是将所有需要存入HashSet的值,直接保存在HashMap中
2). HashSet如何去掉重复?
3). 先判断hashCode是否一致,==比较地址,equals比较内容
II. LinkedHashSet【了解】:
1). 底层使用LinkedHashMap(链表结构)存储,节点形式单独存储数据,并可以指向下一个节点,通过顺序访问节点,可保留元素插入顺序
III. TreeSet【了解】:
1). 实现了SortedSet接口,要求必须可以对元素排序。
2). 所有插入元素,必须实现Comparable接口,覆盖compareTo方法。
3). 根据compareTo方法返回0作为去重的依据,(意味重复)
- Map体系集合:
I. Map:地图、映射
I. 概念:存储一对数据(Key-value),无序、无下标、键不可重复、值可以重复。
II. HashMap算法:拿到任何一个对象好,通过hash(key)做运算,key>>>16(除以16),只可能得到0~15之间的一个数组,作为插入数组的下标
III. Hashtable:HashMap的线程安全版本
IV. TreeMap:自动对key做排序,根据compareTo的返回值去重
V. Properties:Hashtable 子类,主要用于存储key和value都是字符串的情况,常在读取配置文件之后,保存文件中的键值对。反射、JDBC
BigDecimal
位置: java.math包中。
作用:精确计算浮点数。
创建方式: BigDecimal bd=new BigDecimal(“1.0");
方法:
BigDecimal add(BigDecimal bd) 加
BigDecimal subtract(BigDecimal bd) 减
BigDecimal multiply(BigDecimal bd) 乘
BigDecimal divide(BigDecimal bd) 除
BigDecimal除法
除法: BigDecimal(BigDecimal bd,int scal,RoundingMode mode)
参数scal :指定精确到小数点后几位。
参数mode :
指定小数部分的取舍模式,通常采用四舍五入的模式,
取值为BigDecimal.ROUND_HALF_UP。
集合:
-
Collection体系集合:
I. Collection父接口:该体系结构的根接口,代表一组对象,称为“集合”,每个对象都是该集合的“元素”。
II. List接口的特点:有序、有下标、元素可重复。
III.Set接口的特点:无序、无下标、元素不可重复。
IV. Collection接口方法
特点:代表- -组任意类型的对象,无序、无下标。
方法:
boolean add(Object obj) //添加-一个对象。
boolean addAll(Collection c) //将一个集合中的所有对象添加到此集合中。
void clear() /清空此集合中的所有对象。
boolean contains(Object o) //检查此集合中是否包含o对象
boolean equals(Object o) //比较此集合是否与指定对象相等。
boolean isEmpty() /判断此集合是否为空
boolean remove(Object o) //在此集合中移除o对象,也可以传入下标
int size() //返回此集合中的元素个数。
Object[] toArray() //将此集合转换成数组。 -
List子接口:
I. 特点:有序、有下标、元素可以重复。
II. 继承可父接口提供的共性方法,同时定义了一些独有的与下标相关的操作方法。
III.接口中的方法
特点:有序、有下标、元素可以重复。
方法:
void add(int index, Object o) //在index位置插入对象o。
boolean addAll(int index, Collection c) //将一个集合中的元素添加到此集合中的index位置。
Object get(int index) //返回集合中指定位置的元素。
List subList(int fromIndex, int toIndex) //返回fromIndex和toIndex之间的集合元素。 -
List实现类:
I. JDK8的ArrayList,实际初始长度是0(开始是0,扩容之后就变成了10了)
II. 首次添加元素时,需要实际分配数组空间,执行数组扩容操作
III.真正向数组中插入数据,(Lazy懒)用的时候再创建,或再加载,有效的降低无用内存的占用 -
ArrayList:
I. 数组结构存储,查询快,增删慢。//注册(1次)-> 查询(N次)
II. JDK 1.2发布,执行效率快,线程不安全。 -
Vector:
I. 数组结构存储,查询快,增删慢。
II. JDK 1.0发布,执行效率慢,线程安全。 -
LinkedList:
I. 链表(链接列表)结构存储,查询慢、增删快。
II. 了解:Queue接口:队列、双端队列
III. 了解:栈结构Last In First Out(后进先出)
IV. 了解:队列结构First In First Out(先进先出)
万物皆对象,一切皆工具
7. 泛型集合【重点-解决应用问题】:
I. 概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
II. 特点:
1). 编译时即可检查,而非运行时抛出异常。
2). 访问时,不必类型转换(拆箱)。
3). 不同泛型之间引用不能相互赋值,泛型不存在多态。
- 泛型:高级类别的知识,熟练应用,需要时间、经验的积累(常用名称:E = Element / T = Type / K = Key / V = Value)
I. 概念:约束-规范类型
II. 泛型的场景:
1). 定义泛型:
A). 实例泛型:
a). 类:创建对象时,为类所定义的泛型,进行参数化赋值
b). 接口:实现接口时,为接口所定义的泛型,进行参数化赋值
B). 静态泛型:
a). 定义在方法的返回值类型前面:、、
2). 定义在方法的形参列表当中:、、,不支持使用&
- Collections工具类:
概念:集合工具类,定义了除了存取以外的集合常用方法。
I. public static> void sort(List list) //排序,要求:必须实现Comparable,必须可与自身类型比,以及父类类型比
II. public static void reverse(List list) //反转、倒置元素
III. public static void shuffle(List list) //随机重置顺序
经验:一级目标能看懂、能调用,二级目标能定义、能设计
-
Set子接口:
I. 特点:无序、无下标、元素不可重复(当插入新元素时,如果新元素与已有元素进行equals比较,结果为true时,则拒绝新元素的插入)
II. 方法:全部继承自Collection中的方法 -
foreach循环:
for(数据类型 变量名 : 容器名称){ //可遍历集合或数组(常用在无序集合上)
} -
Set接口实现类:
I. HashSet【重要】:
1). HashSet的底层使用的HashMap类,即是将所有需要存入HashSet的值,直接保存在HashMap中
2). HashSet如何去掉重复?
3). 先判断hashCode是否一致,==比较地址,equals比较内容
II. LinkedHashSet【了解】:
1). 底层使用LinkedHashMap(链表结构)存储,节点形式单独存储数据,并可以指向下一个节点,通过顺序访问节点,可保留元素插入顺序
III. TreeSet【了解】:
1). 实现了SortedSet接口,要求必须可以对元素排序。
2). 所有插入元素,必须实现Comparable接口,覆盖compareTo方法。
3). 根据compareTo方法返回0作为去重的依据,(意味重复)
- Map体系集合:
I. Map:地图、映射
I. 概念:存储一对数据(Key-value),无序、无下标、键不可重复、值可以重复。
II. HashMap算法:拿到任何一个对象好,通过hash(key)做运算,key>>>16(除以16),只可能得到0~15之间的一个数组,作为插入数组的下标
III. Hashtable:HashMap的线程安全版本
IV. TreeMap:自动对key做排序,根据compareTo的返回值去重
V. Properties:Hashtable 子类,主要用于存储key和value都是字符串的情况,常在读取配置文件之后,保存文件中的键值对。反射、JDBC
BigDecimal
位置: java.math包中。
作用:精确计算浮点数。
创建方式: BigDecimal bd=new BigDecimal(“1.0");
方法:
BigDecimal add(BigDecimal bd) 加
BigDecimal subtract(BigDecimal bd) 减
BigDecimal multiply(BigDecimal bd) 乘
BigDecimal divide(BigDecimal bd) 除
BigDecimal除法
除法: BigDecimal(BigDecimal bd,int scal,RoundingMode mode)
参数scal :指定精确到小数点后几位。
参数mode :
指定小数部分的取舍模式,通常采用四舍五入的模式,
取值为BigDecimal.ROUND_HALF_UP。
集合:
-
Collection体系集合:
I. Collection父接口:该体系结构的根接口,代表一组对象,称为“集合”,每个对象都是该集合的“元素”。
II. List接口的特点:有序、有下标、元素可重复。
III.Set接口的特点:无序、无下标、元素不可重复。
IV. Collection接口方法
特点:代表- -组任意类型的对象,无序、无下标。
方法:
boolean add(Object obj) //添加-一个对象。
boolean addAll(Collection c) //将一个集合中的所有对象添加到此集合中。
void clear() /清空此集合中的所有对象。
boolean contains(Object o) //检查此集合中是否包含o对象
boolean equals(Object o) //比较此集合是否与指定对象相等。
boolean isEmpty() /判断此集合是否为空
boolean remove(Object o) //在此集合中移除o对象,也可以传入下标
int size() //返回此集合中的元素个数。
Object[] toArray() //将此集合转换成数组。 -
List子接口:
I. 特点:有序、有下标、元素可以重复。
II. 继承可父接口提供的共性方法,同时定义了一些独有的与下标相关的操作方法。
III.接口中的方法
特点:有序、有下标、元素可以重复。
方法:
void add(int index, Object o) //在index位置插入对象o。
boolean addAll(int index, Collection c) //将一个集合中的元素添加到此集合中的index位置。
Object get(int index) //返回集合中指定位置的元素。
List subList(int fromIndex, int toIndex) //返回fromIndex和toIndex之间的集合元素。 -
List实现类:
I. JDK8的ArrayList,实际初始长度是0(开始是0,扩容之后就变成了10了)
II. 首次添加元素时,需要实际分配数组空间,执行数组扩容操作
III.真正向数组中插入数据,(Lazy懒)用的时候再创建,或再加载,有效的降低无用内存的占用 -
ArrayList:
I. 数组结构存储,查询快,增删慢。//注册(1次)-> 查询(N次)
II. JDK 1.2发布,执行效率快,线程不安全。 -
Vector:
I. 数组结构存储,查询快,增删慢。
II. JDK 1.0发布,执行效率慢,线程安全。 -
LinkedList:
I. 链表(链接列表)结构存储,查询慢、增删快。
II. 了解:Queue接口:队列、双端队列
III. 了解:栈结构Last In First Out(后进先出)
IV. 了解:队列结构First In First Out(先进先出)
万物皆对象,一切皆工具
7. 泛型集合【重点-解决应用问题】:
I. 概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
II. 特点:
1). 编译时即可检查,而非运行时抛出异常。
2). 访问时,不必类型转换(拆箱)。
3). 不同泛型之间引用不能相互赋值,泛型不存在多态。
- 泛型:高级类别的知识,熟练应用,需要时间、经验的积累(常用名称:E = Element / T = Type / K = Key / V = Value)
I. 概念:约束-规范类型
II. 泛型的场景:
1). 定义泛型:
A). 实例泛型:
a). 类:创建对象时,为类所定义的泛型,进行参数化赋值
b). 接口:实现接口时,为接口所定义的泛型,进行参数化赋值
B). 静态泛型:
a). 定义在方法的返回值类型前面:、、
2). 定义在方法的形参列表当中:、、,不支持使用&
- Collections工具类:
概念:集合工具类,定义了除了存取以外的集合常用方法。
I. public static> void sort(List list) //排序,要求:必须实现Comparable,必须可与自身类型比,以及父类类型比
II. public static void reverse(List list) //反转、倒置元素
III. public static void shuffle(List list) //随机重置顺序
经验:一级目标能看懂、能调用,二级目标能定义、能设计
-
Set子接口:
I. 特点:无序、无下标、元素不可重复(当插入新元素时,如果新元素与已有元素进行equals比较,结果为true时,则拒绝新元素的插入)
II. 方法:全部继承自Collection中的方法 -
foreach循环:
for(数据类型 变量名 : 容器名称){ //可遍历集合或数组(常用在无序集合上)
} -
Set接口实现类:
I. HashSet【重要】:
1). HashSet的底层使用的HashMap类,即是将所有需要存入HashSet的值,直接保存在HashMap中
2). HashSet如何去掉重复?
3). 先判断hashCode是否一致,==比较地址,equals比较内容
II. LinkedHashSet【了解】:
1). 底层使用LinkedHashMap(链表结构)存储,节点形式单独存储数据,并可以指向下一个节点,通过顺序访问节点,可保留元素插入顺序
III. TreeSet【了解】:
1). 实现了SortedSet接口,要求必须可以对元素排序。
2). 所有插入元素,必须实现Comparable接口,覆盖compareTo方法。
3). 根据compareTo方法返回0作为去重的依据,(意味重复)
- Map体系集合:
I. Map:地图、映射
I. 概念:存储一对数据(Key-value),无序、无下标、键不可重复、值可以重复。
II. HashMap算法:拿到任何一个对象好,通过hash(key)做运算,key>>>16(除以16),只可能得到0~15之间的一个数组,作为插入数组的下标
III. Hashtable:HashMap的线程安全版本
IV. TreeMap:自动对key做排序,根据compareTo的返回值去重
V. Properties:Hashtable 子类,主要用于存储key和value都是字符串的情况,常在读取配置文件之后,保存文件中的键值对。反射、JDBC
经验:每个集合的方法很多,记住集合的特性需要什么方法我们去Api里面查