字符串——字典树模板及习题(持续更新)
字典树
字典树又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。
字典树叫前缀树更容易理解。
字典树的样子
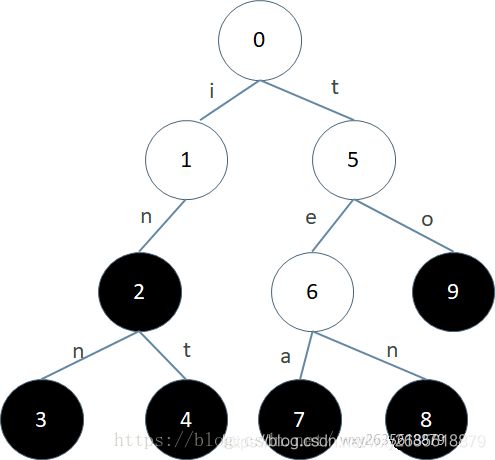
原理
一般来说trie树支持俩个操作:
1.Insert(w); 就是将字符串w插入到集合
2.Search(s);就是查询字符串s在不在集合中
如上如所示,插入的字符串包括 ’in’,‘inn’,‘int’,‘tea’,‘to’,‘ten’,这六个字符串。黑色表示是终结点,在插入一个字符串的结尾,要将该节点标记为终结点,及接下来的代码中的color[p] = 1。
查询一个字符串在不在集合中就是,相当于顺着trie找,当前字符不在时返回false,若存在就在该节点的子节点中找下一个字符,找到结尾时判断一下当前节点,如果是终结点,那么返回true,否则返回false。
模板(数组简单实现)
#include #include 习题(持续更新)
1.UVA 644 Immediate Decodability
链接:UVA 644
题意:多组输入,每一组结尾用单字符‘9’表示该组结束。给你一系列由‘0’,‘1’构成的字符串,让你判断是否有字符串是其他字符串的前缀,若有输出Set 2 is not immediately decodable,否则输出Set 1 is immediately decodable。
题解:就是简单的运用一下trie树,在执行Insert的时候有两种情况表示为有字符串为其他字符串的前缀。
1.插入该字符串的最后一个字符的时候没有新键节点。
2.发现下一个字符处有结尾标签。
代码:
#include 2.UVA 1127 Word Puzzles
链接:UVA 1127
题意:T组, 每组包括n, m, t, 分别表示字符迷宫的行和列, t 表示接下来的字符串数量。接下来输入一个n*m的字符数组,以及t串字符串,全部由大写字母组成。现在让你在字符数组中找出这些字符串,寻找的方式是可以由一个字符出发沿着八个方向,A到H表示这八个方向,A表示North上, 按时钟顺时针。
按顺序输出找到每一个字符串的起始位置以及方向。
题解:将这写字符串用字典树存起来,然后暴力搜索即可,这里用到了字典树的前缀树的性质可以减少时间复杂度,所以要用字典树。
代码:
有点小问题没找出来
#include 参考代码(正解)
#include3.UVA 10282 Babelfish
链接:UVA10282
题意:输入最多包含100,000个字典条目,后跟空白行,然后输入最多100,000个字符串消息。 每个字典条目都是一行,包含英文单词后跟一个空格和外语单词。 在词典中,没有外来词出现多次。 字符串消息是一些外语单词序列,每行一个单词。 输入中的每个单词都是一个序列最多10个小写字母。现在要你输出每一个外语单词对应的英文单词,如果不存在就输出“eh”。
题解:字典树模板题,输入用gets 和 sscanf 判断一些。
代码:
#include 4.UVA 11362 PhoneList
链接:UVA11362
题意:与第一题差不多就是换了一个皮,字典树简单题。
题解:见第一题
代码:
#include 5.HDU 1251 统计难题
链接:HDU1251
题意:Ignatius最近遇到一个难题,老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计出以某个字符串为前缀的单词数量(单词本身也是自己的前缀).
题解:用字典树,每一次插入的时候用数组记录当前字符串前缀的访问次数,查询的时候直接返回,输出就行。
代码:
#include 6.POJ 2001 Shortest Prefixes
链接:POJ2001
一开始在vjudge上写,发现UVALive评测有问题搞了调了半天代码结果不是代码问题,在poj上一发过了。我的大好时光/(ㄒoㄒ)/~~。
题意:就是给你一些字符串,现在让你对每一个字符串找出一个最短前缀(包括本身)让该前缀只有该字符串有,若不存在则输出字符串本身。
题解:放到字典树中,统计一下每一个前缀出现的次数,查找的时候第一个出现次数为1 的前缀就是ans,若找不到返回字符串结尾下标。
代码:
//#include 7.HDU 5687 Problem C
链接:HUD5687
题意:
有三种操作:
1、insert : 往神奇字典中插入一个单词
2、delete: 在神奇字典中删除所有前缀等于给定字符串的单词
3、search: 查询是否在神奇字典中有一个字符串的前缀等于给定的字符串
对于每一个search 操作,如果在度熊的字典中存在给定的字符串为前缀的单词,则输出Yes 否则输出 No。
题解:用字典树,操作1就是插入记录每一个前缀出现的次数,操作2就是删除掉要删除的前缀的后面的所有节点就是memset一下,并且将路径上的所有前缀出现的次数减去该需要删除的前缀出现的次数,操作3就是判断一下该字符串前缀出现的次数为0输出No不然输出Yes。
代码:
//#include 8.POJ 1816 Wild Words
链接:POJ1816
题意:现在给你n个模式串和m个匹配串,模式串中有 ?和∗ ? 和 ∗ 两种字符,?可以匹配任意一种字符, ∗ ∗ 可以匹配任意个字符,问每种匹配串可以和之前哪些模式串匹配。
题解:我们先构建好字典树,对于每个匹配串实现find,find的时候用类似dfs的写法,如果当前节点的字符或者?存在,直接dfs下一个位置的字符,如果当前字符对应的位置有 ∗ ∗ 存在,那么就从匹配串之后的每一个位置进行往下dfs,因为可以匹配任意个字符。而dfs计数的条件是匹配串匹配结束而且达到模式串某个结尾标记。则在这个模式串上做标记。需要注意的细节是此时不能直接return(这里我就被坑了一下没有考虑好),因为有可能此时的字符串和剩下的匹配串还能匹配,类似模式串A : AA** 模式串B: AA*** 匹配串为AAA ,那么匹配到A字符串之后则不能停止,要继续往下搜索。
代码:
#include 9.HDU 2846 Repository
链接:HDU2864
题意:给你一些P个字符串 和 Q个字符串, 求这Q个字符串分别在这P个字符串中出现过几次, 每个字符串只记一次。
题解:看题目数据发现P最大为1e4, 并且字符串最长为20, 很明显字典树可以写, 处理一下将P个字符出串每一个的后缀包括本身插入字典树中, 并且用一个mark’数组记录一下每一个前缀出现的次数,注意的是可能一个字符串中的不同后缀的一些前缀相同,这里我用一个map记录一下在同一个字符串中的那些前缀出现过,若出翔mark就不加了。
代码:
#include 10.CodeForces 817E Choosing The Commander(01字典树入门好题)
题意:第一行一个数 t 表示 接下来的操作数,每一行为一个操作。输入格式为:
- 1 pi 表示能力值为pi的人加入军营
- 2 pi 表示能力值为pi的人离开军营
- 3 pj qj 表示能力值为pj, 领导力为qj 的人来领导军营里的人,输出服从领导的人数,服从领导的条件是当pj 按位异或 pi < qj 时服从领导。
题解:用01字典树,将每一个数用32位二进制表示并插入或删除或比较字典树中的。
代码:
#include