spark结合hive
如果mysql是安装在windows上的话,hive在Linux上,要保证两者能通信的话需要改变windows上的字符集形式为latin1
方法如下alter database hive character set latin1;
话不多说码代码
(hive shell里面 机器只启动了hdfs没有启动yarn所以没有启动hadoop的mapreduce程序)
create table person(id int,name string,age int) row format delimited fields terminated by ",";
load data inpath "hdfs://hadoop01:9000/person.txt" into table person;
select * from person;(没有mapreduce也可以从中读取出来,不会启动mapreduce,不需要mapreduce)
select * from person order by age desc ; (会启动本地自带的mapreduce)
和spark结合(必须将hive-site.xml 放到$SPARK_HOME/conf/目录里面)cp hive-site.xml $SPARK_HOME/conf/
同时将(hdfs也要拷贝过来)cp hdfs-site.xml $SPARK_HOME/conf/
Caused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver ("com.mysql.jdbc.Driver") was not found
解决方法将jdbc驱动放到spark的jars目录中 :
cp mysql-connector-java-5.1.32.jar /export/servers/spark-2.1.0-bin-hadoop2.7/jars/
或者也可以在启动的时候告知jar在哪 --driver-class-path+jar的地址
远程调试的时候
添加下面这行配置在spark-env.sh中
export SPARK_MASTER_OPTS="-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=10000"
调试master
sbin/start-master.sh
IDEA主要进行添加remote的一下配置
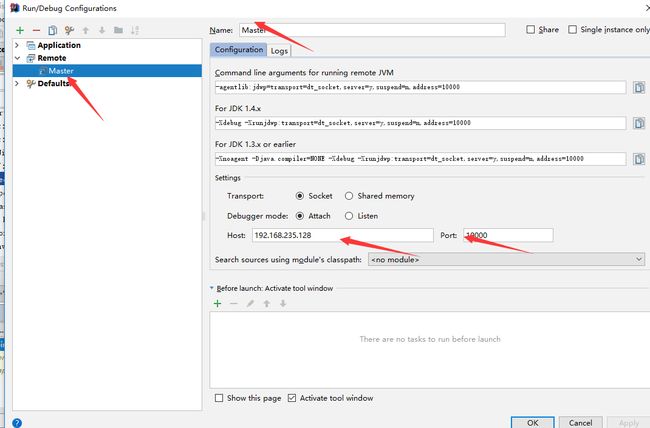
然后开始debug

调试worker
在worker的spark-env.sh中添加
export SPARK_WORKER_OPTS="-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=10001"
start-slave.sh spark://hadoop01:7077 //要告诉worker master的地址
然后主要的方法和调试master基本一致
也可以Debug app (--driver-java-options)如下面
bin/spark-submit --class cn.itcast.spark.WC --master spark://node-1.itcast.cn:7077 --driver-java-options "-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=10002" /root/bigdata-2.0.jar hdfs://node-1.itcast.cn:9000/words.txt hdfs://node-1.itcast.cn:9000/wordsout
任务提交流程
spark-submit --class cn.itcast.spark.WordCount
bin/spark-clas -> org.apache.spark.deploy.SparkSubmit 调用这个类的main方法
doRunMain方法中传进来一个自定义spark应用程序的main方法class cn.itcast.spark.WordCount
通过反射拿到类的实例的引用mainClass = Utils.classForName(childMainClass)
在通过反射调用class cn.itcast.spark.WordCount的main方法
用一个IDE工具连接 建立一个remote application
172.16.0.13 10002
在本地的代码打断点
debug按钮开始调试