当二维码在跑步的时候,ZXing在想些什么。
我与二维码的故事,是从一张扫不出来的二维码开始的。
如下图:

这是一张我们的app,无法识别的二维码
上面的这张二维码,我们的Android APP很难扫描出来。
我试了 微信、华为浏览器、ios 客户端等大厂app,不管是正着扫,歪着扫、躺着扫,跪着扫。。。。不管怎么扫基本都能一次成功。
我们二维码解析使用的是ZXing。我试了demo也是一样的情况。看来如果想要解决这个问题,需要去阅读甚至修改Google大佬们的代码,这件事情我本来是不敢去尝试的。
幸亏关键时刻,我想起来我大哥——江湖上鼎鼎有名的 瑞幸--雷彦祖 所过的一句话:
遇到技术难题就不去解决,到最后只能

雷彦祖 语录1
看来是时候展示真正的技术了。
一 物理相机采集图像数据
首先先来看看,当我们使用摄像头扫描二维码的时候,究竟在发生了些什么事情。二维码的解析数据是从相机反馈回来的:
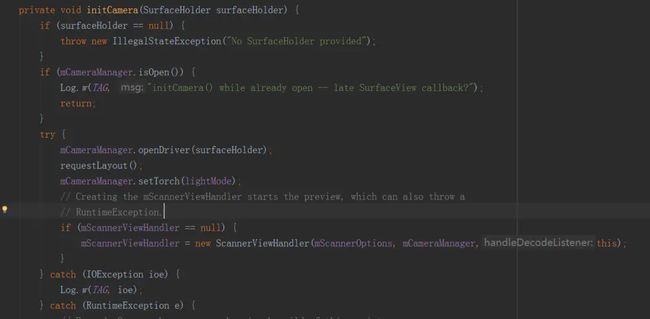
初始化打开摄像头
摄像头通过聚焦等操作,不断将预览数据以YUV的格式反馈给ZXing.
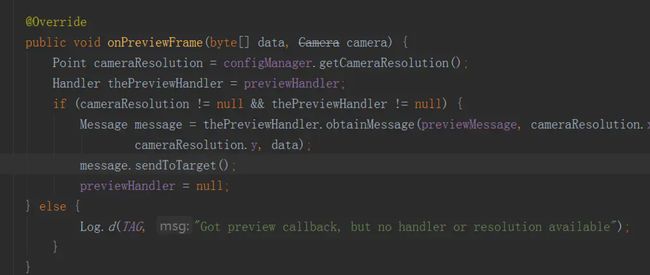
回调返回摄像头的预览数据。
二 ZXing接盘YUV数据,进行解析操作

开始解析
拿到YUV数据之后,首先做两件事:
第一件就是把图像旋转90度,这个是因为android摄像头默认方向是横屏的,与用户习惯不符。
第二件事,就是根据YUV图像创建亮度源。

构建亮度图
走到这,如果想要看的懂后续流程,需要引入一个图像方面的概念了。
什么是YUV格式:
YUV格式 分辨是 Y 明亮度,U 色度 V浓度。
这种格式有两个好吃:方便切换且节省带宽, 因此无线电视一般都采用这种格式。
当数据色彩数据(UV)移除时,就是完整的黑白影像,不需要做什么特殊的处理。
在android 平台上一般采用的YUV420格式。以此为例: 一帧一像素RGB格式,需要占用3字节带宽。而 YUV420 只需要1.5字节长度的带宽。
与大家熟悉的ARGB等格式不同,YUV420格式的储存方式是这样的(多个连续的Y像素,公用一组UV像素):

YUV420格式
我们这里探究的是二维码的识别过程,对于YUV有所了解就可以了。如果想要知道更多的内容具体可以查看这篇MSDN文档:
https://msdn.microsoft.com/en-us/library/aa904813

雷彦祖 语录2
三 对YUV格式的图像进行二值化操作
大家都看的出来,二维码上真正有意义的内容是那些黑色的符号部分,所以我们需要对捕捉到的图像,进行二值化操作。

二
所谓的二值化,就是把在我们捕捉到的图像上拆成两部分,一部分是白的,另外一部分是黑的。
整个图像上的所有像素 要进行分类:非黑即白。
当我们在晚上扫描二维码的时候,因为整体灰度值都很低,黑色的二维码像素很有可能被当做白色数据扔掉,也就是光源不足时,二维码扫描失败的主要原因。
ZXing自带的二值化解析器有两种,我们采用的是相对保守,对低端设备支持较好的GlobalHistogramBinarizer解析器。

二值化代码实现
二值化的第一步是二维的图像数据,映射到一个一维数组,便于后续的计算。
第二步是从 YUV420的编码格式中取出对于我们构造光源图有用的 Y像素,不理会UV即可。(所以,使用解析YUV格式的二维码会比解析RGB格式的二维码图像效率更高,这也是二维码的优点之一)
如果你问 摄像头返回的图像数据是YUV以外的格式怎么办? Google的大佬一早就悄悄告诉我了,ZXing 只支持特定的两种编码格式了:
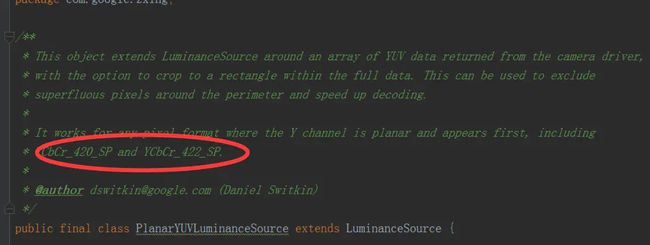
光源图支持的两种图像格式
第三步, 想要把一张图分为黑与白,那么一定要找到一个“灰”值,“黑”与“白”都是基于这个标准值来说的,亮度高于标准值,则为白,亮度低于标准值则为黑。
来看看ZXing是怎么计算这个值的:
首先是将 整个图像,按照高度 等比例截取五条像素线。类似这种:

获取五条线
然后对截取到的五条像素线,截取掉其 头部和尾部的五分之一,只取其中的五分之三。就像这样:

凑活着看吧。
再然后,对根据刚刚采集到的 这些像素,进行一次直方图的分布。采集其中出现频率最高的色值,把他当做基准值,就像下图:
(上面的花样截取操作 是为了在不影响效率的前提下,尽可能采样地相对公平。)

直方图示例
找出基准点,后面的事情就简单了,把低于基准值的像素点,单独放到一个matrix中。这就是我们接下来二维码解析中会用到的唯一数据源了。
至此,二值化结束。。。。。。。。。(真特么的麻烦啊)

雷彦祖 语录3
将所有我们认为是“黑”的色值保存到一个matrix中。这个也就是本次解析,我们会用到的有效数据源了。
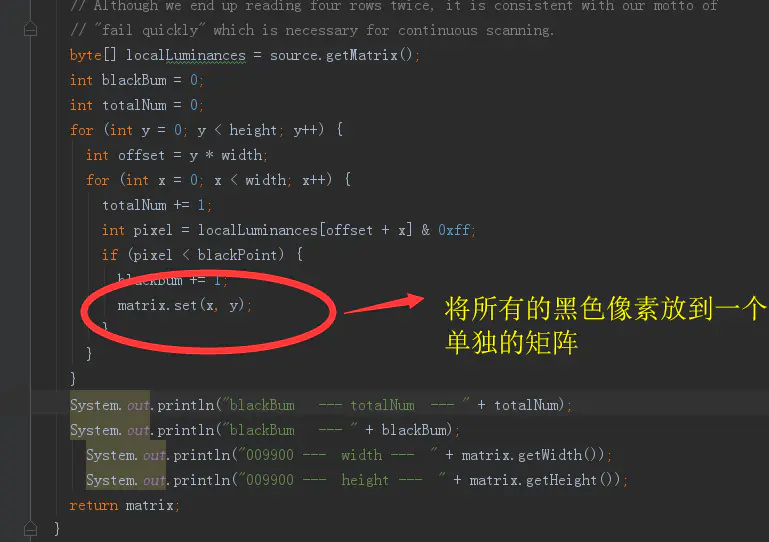
黑?
四 QRCode定位裁剪
我们平时说说的二维码,其标准名称就是ISO--QRCode标准。ZXing接下来的所有的操作,都要看他的表演了。
需要特别说明一下,ZXing自带多种格式解析器,我们可以配置成只解析二维码,这样可以提升扫码速度。
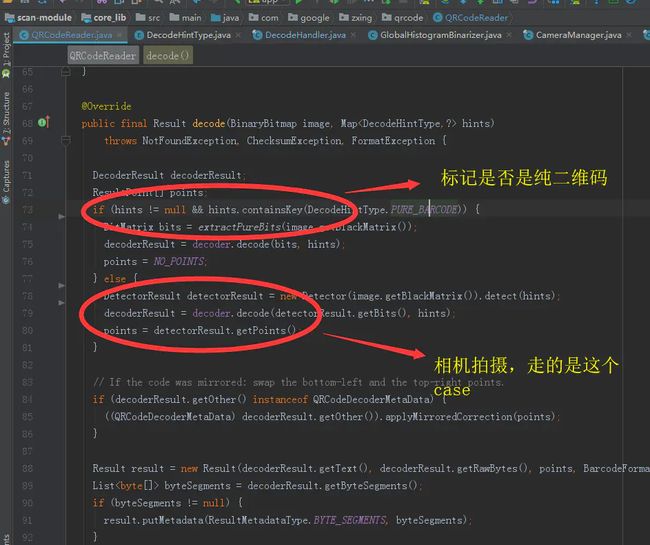
QRCode解析流程
所谓纯的二维码就是,类似于微信长按识别二维码的操作,除了二维码图片外没有其他的干扰因素。
而一般相机在拍摄二维码的过程中,会采集到很多二维码之外的其他无关图像信息,所以ZXing在解析之前需要先把这部分图像信息处理掉。来看看ZXing是怎么做到这一点。
首先是以横切的方式,寻找二维码的三个特征点,如果无法找到这三个点,那就不是一个合格的二维码,则视为本次解析失败。
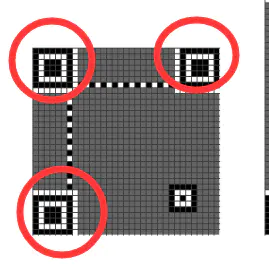
二维码特征module
具体的解析代码为:
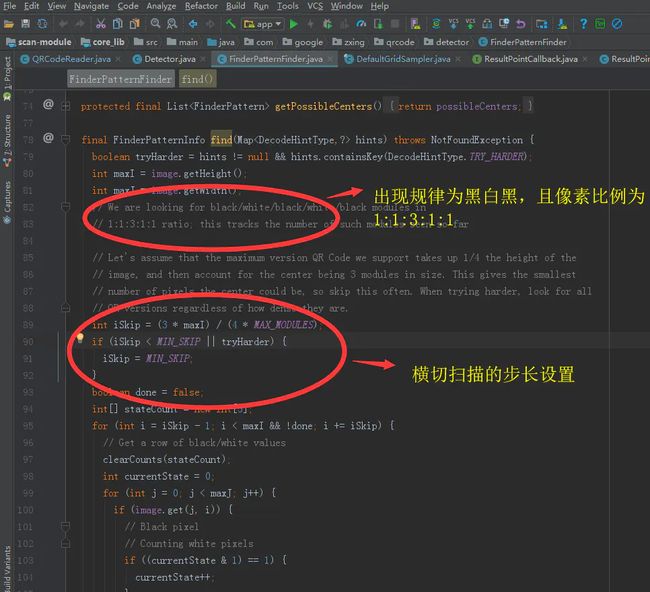
寻找定位点
这里有一点需要注意: ZXing提供了一个参数可以调整扫描定位点时的步长,如果这里的步长设置的小一些,可以提升扫描的成功率,减少错过定位点的情况。
在找到之后ZXing还会对三个定位点进行旋转排序,这也是为什么无论我们以什么样的姿势扫描二维码,解析的时候都能保证其成功率的原因。
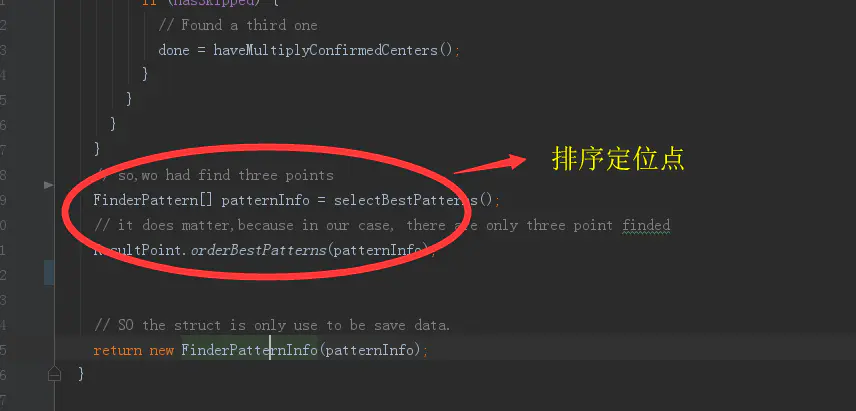
旋转定位点
这也是QRCode标准的优势所在:

官网优势5--360旋转
五 将像素点与QRCode的module 进行对应处理
如果ZXing获取到排列有序的三个定位点之后,那么我们就确定,我们找到了一张二维码。接下来,我们会去尝试读取其中的信息。 注意:这不是百分百成功的。
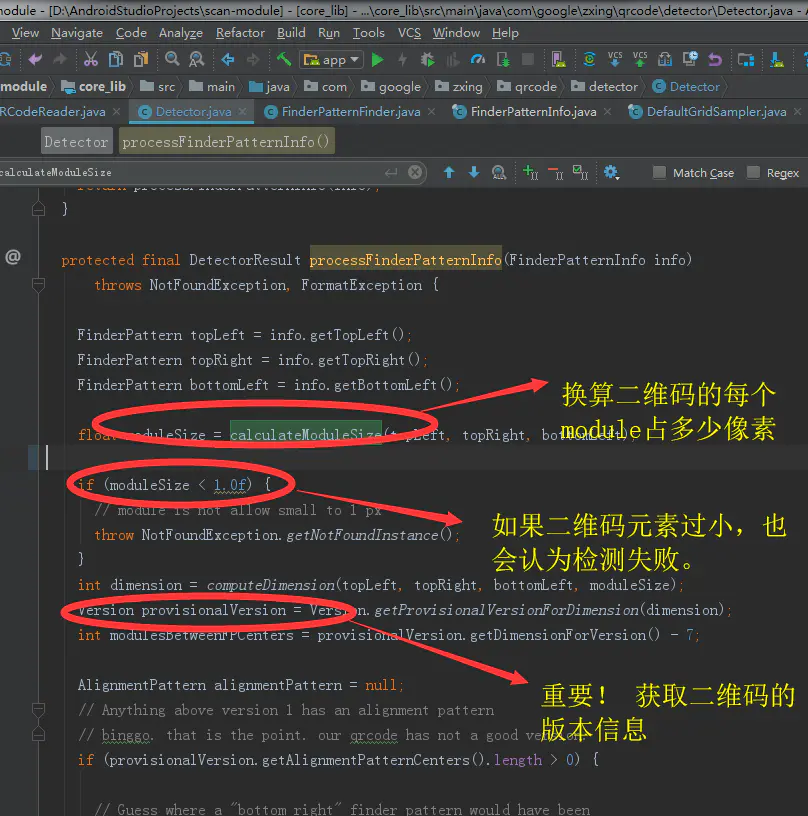
获取二维码版本信息
看到这里又必须要来储存一点二维码的格式知识,才能继续了。
首先:什么是二维码的版本:
二维码是版本是在ISO QRCode标准中约定好的内容。
会在二维码右上,左下两个定位点储存两份。 (为了避免信息损失,如果两份同时都丢了,,那就是采集环境太差,,没办法了。)
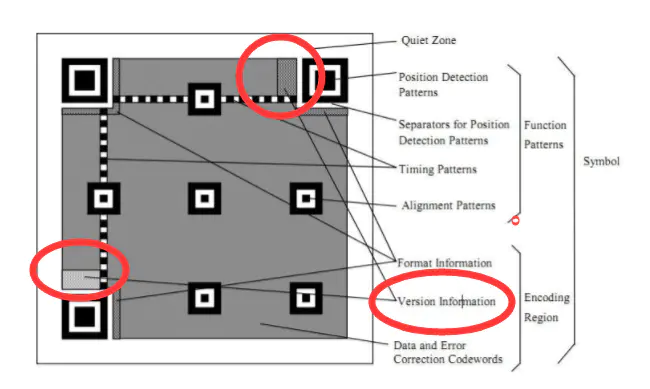
版本信息储存位置
目前二维码版本会有 有40个版本,也就是1-40。 可以简单的理解,就是版本越高的二维码可以储存的内容就越大。反之也说得通,储存信息越多的二维码,其版本也就越高。
我们目前正在追踪,有问题的二维码版本是 1版本。所以我们只看这部分的逻辑。其他的不管。
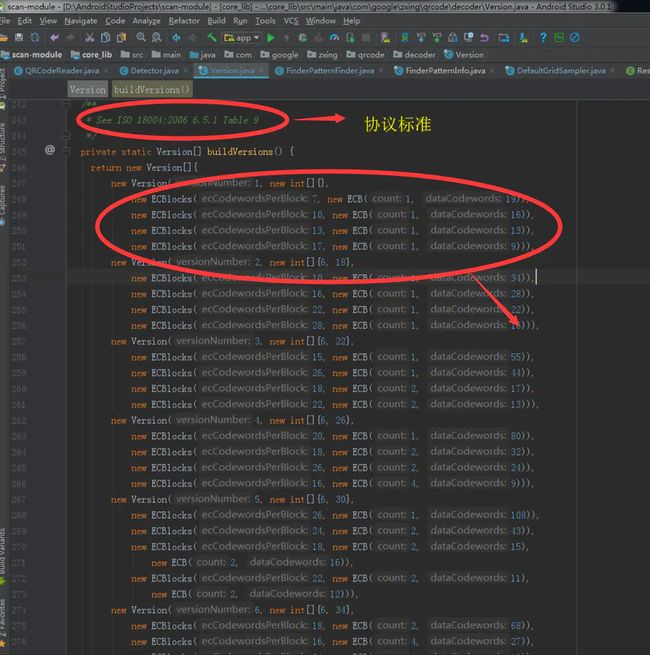
ZXing支持的二维码版本表
具体的点数和版本的关系,可以看这个:
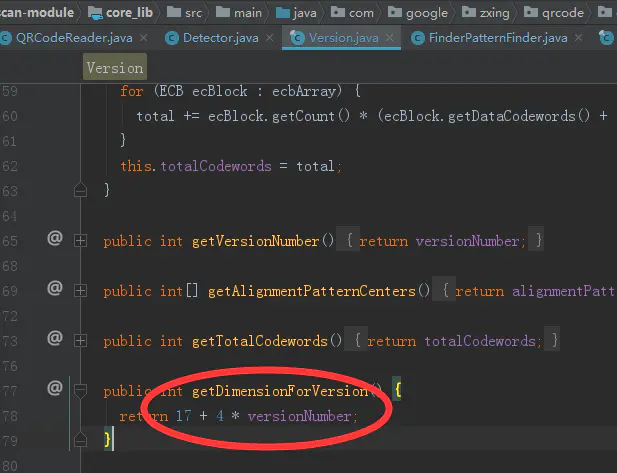
版本和内容数的关系
在获取到当前二维码版本为1之后,zxing 会去计算 三个定位点之间的module的数量
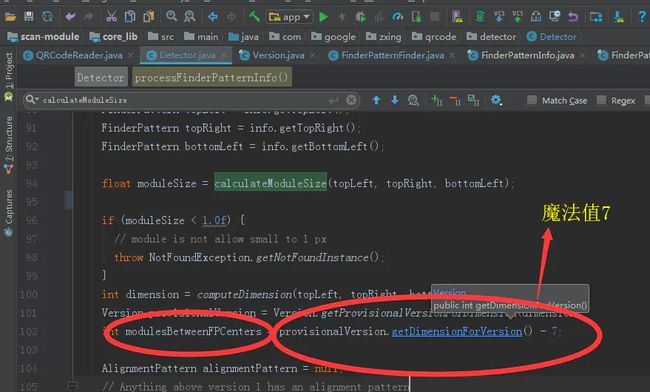
获取内容module数量
上面减掉一个魔法值7的意思是,截取内容区域。

内容区域
也就是说,在一张二维码图片中,真正储存内容数据的是,只是我们上图标注出来的部分。
除此以外的内容都是用来辅助定位等其他功能的。
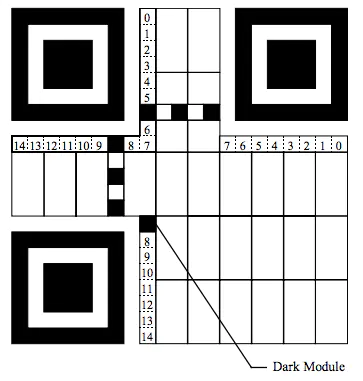
结构示意图
题外话:
上面的1-15个bit位,对于二维码结构来说十分重要,所以每张二维码都会保存两份。这十五个bit位中,2个比特用来储存纠错码类型,3个比特用来储存掩码类型,剩下的十个比特用来储存BCH纠错码。
本文对二维码的格式,不做细致的展开,如果你对二维码感兴趣,可以阅读这里http://www.qrcode.com/en/about/
继续说,我们的流程,ZXing在获取到内容区域,之后会尝试去寻找 校正点。
什么是校正点呢。 就是这个东西:

校正点示意
如果存在校正点,会对二维码的识别和解析工作产生很大的助力。但是版本1的二维码是没有校正点的 。。。。 所以这部分的逻辑代码,我没看。。 继续往下走。

雷彦祖 语录(我特么也忘了是几了)

校正点示意
六 对采集的像素进行透视转换(重要)
ZXing,通过上面阐述的过程,已经成功拿到了二维码的内容区域所对应的深度像素矩阵。
接下来,就是要进行变换操作了。因为我们的获取到的图像有可能是斜着拍的。虽然不影响ZXing识别出来他是一个二维码,但是会影响ZXing识别二维码所包含的内容,所以这里要根据采集图像的视角,对图像像素,进行一定程度上的变化。
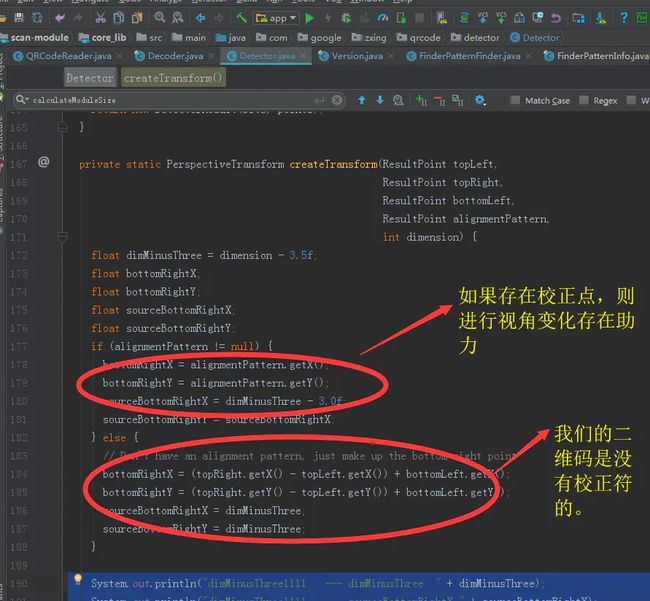
透视转换算法
//TODO 这里给自己加个TODO标签吧。 因为我经过长时间的排查,认定那张二维码之所以扫描不出来,就是这个环节出现的问题。
但是这里的透视算法。我并不是很熟悉(说实话就是,一点都特么没看懂。),所以后续我会对这里继续跟进。
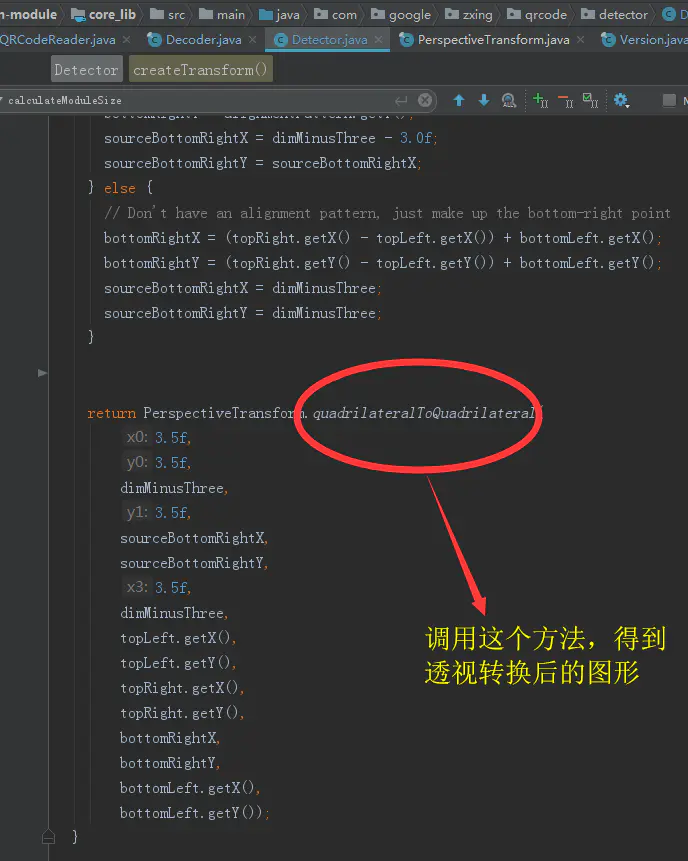
透视转换算法
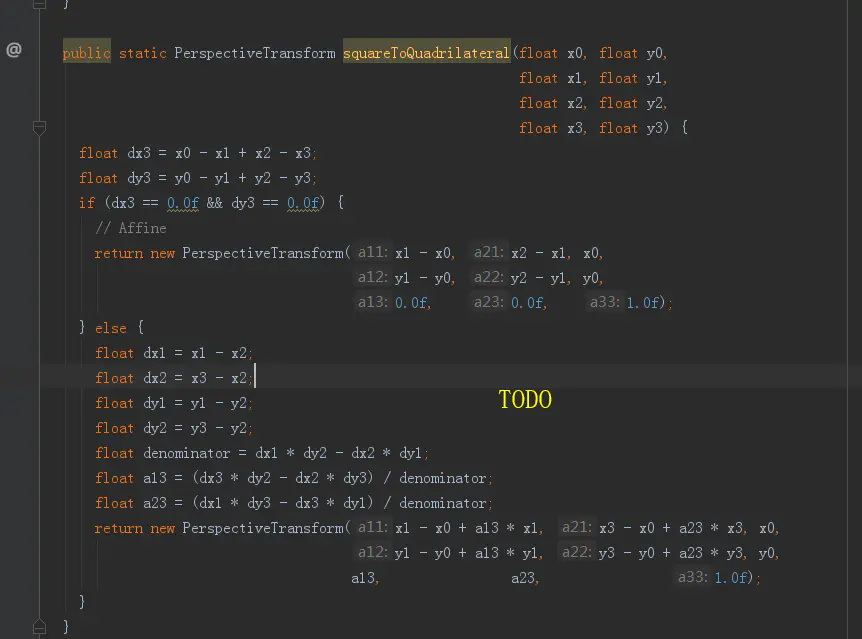
透视转换算法的具体实现
七 像素和QRCode点阵之间的转换
ZXing在透视完成之后,会对图像进行 转换,将数万个深色像素点,转换成对应的 21*21的二维码点矩阵。
(版本1对应的矩阵是21*21)

点阵化像素
具体的点阵化代码:
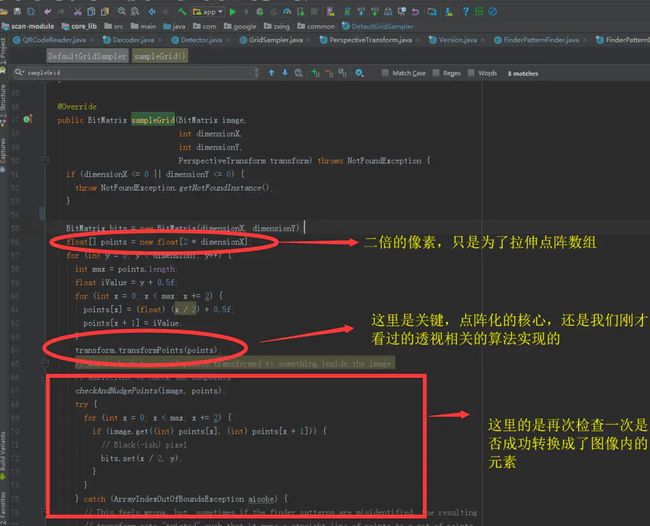
点阵化对象
上面讲的,所有的所有,都是在做一件事,就是把几万个像素转换成21*21的黑色点阵。对应到QRCoder类代码里,其实只有这么一句:
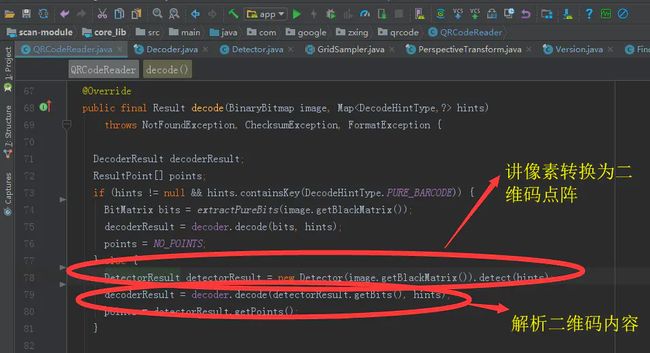
解析流程
八 真正的解析21*21的矩阵所代表的内容
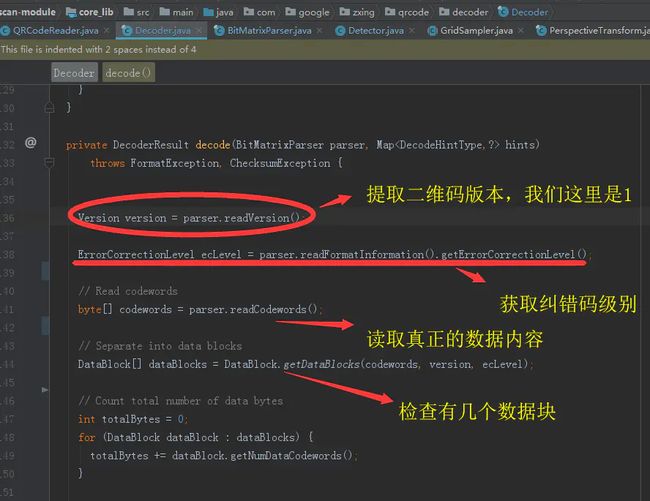
解析流程
这里需要提到一个纠错码的概念。
我们知道二维码之所以能流行起来,就是很大程度是因为二维码格式定义中自纠错的能力很强。
也就是说我们获得到的 21*21的黑白点阵哪怕其中有一部分,因为种种原因,采集错了。黑色被描述成白色,白色被描述成了黑色。 只要错误的内容不要太多,二维码的解析器,依然能够帮你纠正过来。

污渍和损坏的二维码都可以被纠错
在本文的阐述范围内, 只需要知道二维码的纠错是通过里德所罗门算法实现的。 它可以自纠错就可以,不需要过度展开。 如果感兴趣可以阅读这里:
https://en.wikiversity.org/wiki/Reed%E2%80%93Solomon_codes_for_coders
我们需要知道的是,二维码的纠错能力是有代价的。 如果纠错级别越高,所能包含的内容也就越少,反之亦然。
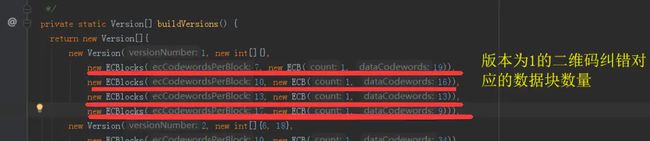
纠错码级别对应的数据块数量
而二维码纠错码的存在也正是,微信的个人二维码可以加入自定义的图片,而识别不受影响的原因。
下图是版本为1的二维码,各个级别所对应的纠错码-数据码对照表
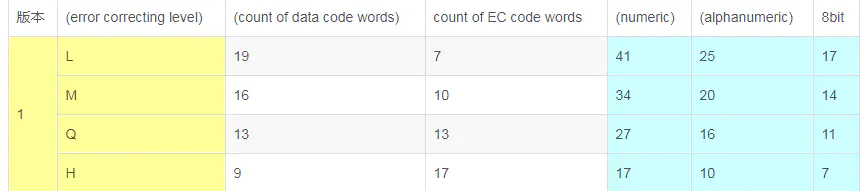
L-M-Q-H
我们这张出错二维码的纠错码级别是H的。也就是最高级别了。
继续下一步:判断数据块的数量。
这个数量与二维码的内容大小有直接关系,我相信大家可能见过 类似这样密集恐惧症的二维码:
高版本二维码
我甚至可以用它去承载一篇长诗。 但是其本质他还是由一个个最简单的二维码数据块组成的。

多个数据块组成的
我们目前追踪的二维码是只有一个模块的二维码,所以这方面的内容也不继续深究,了解即可。
ZXing在拿到点阵中对应真正数据之后,会使用 里德所罗门算法进行自纠错。 这个也是我们的二维码出错的直接原因: 错误点阵太多了 (ps 根本原因不在这)
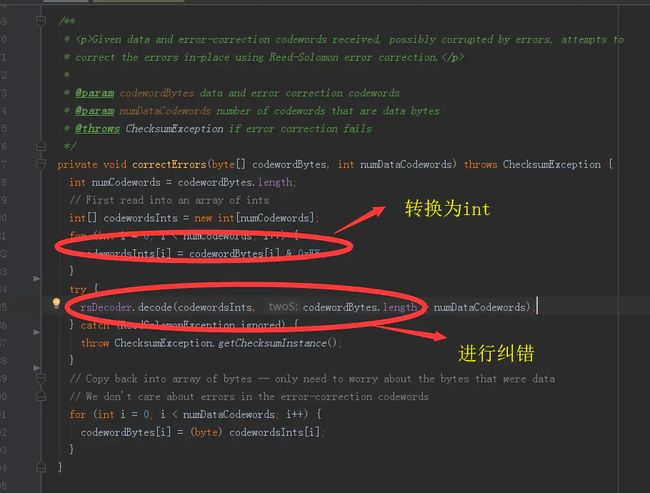
纠错算法
对不起,既然大家都看到这了,我就要说实话了。 纠错的这部分的代码我确实没看懂,只知道所有的数据都是放在伽罗瓦域中的,储存关系类似这样:
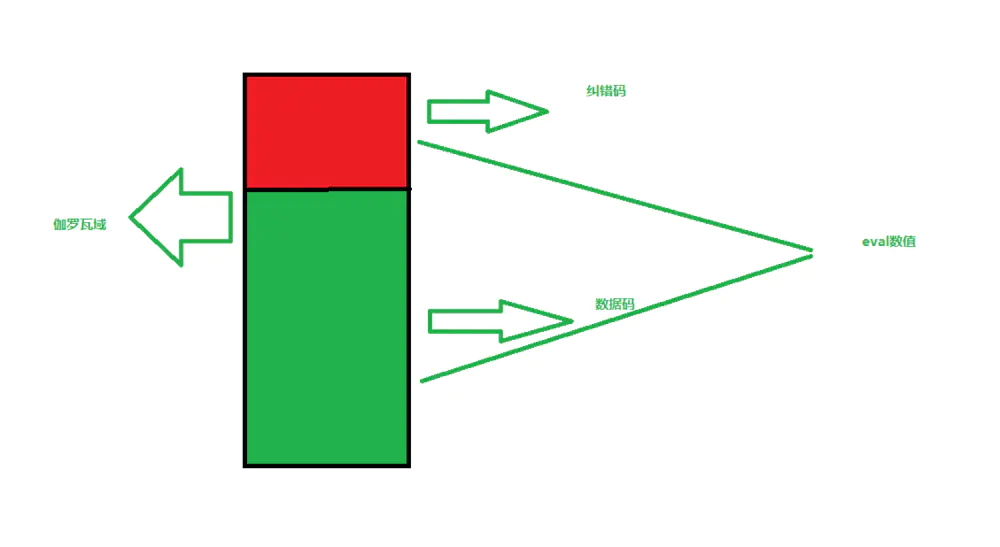
伽罗瓦域示意图
当我们在解析一个伽罗瓦域的时候,先计算校验值,如果eval的数值是0,那么说明这个模块中是没有错误的,不需要纠错操作。如果eval很小,也是可以依据纠错码将其纠正回来的。
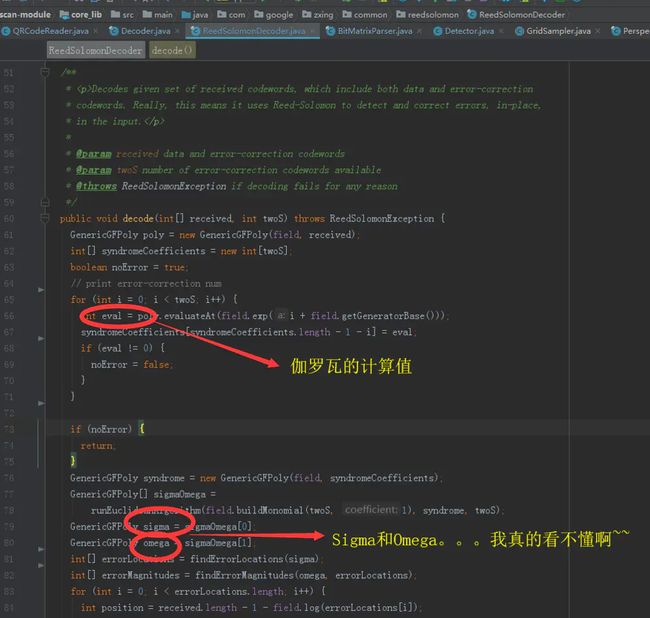
如果计算出来的eval 偏差数值很大。。。那么那就意味着当前数据块数量丢失过多,连纠错码也无法挽救回来:

无药可救
下面就是具体的抢救。。啊不,,是纠错实现:
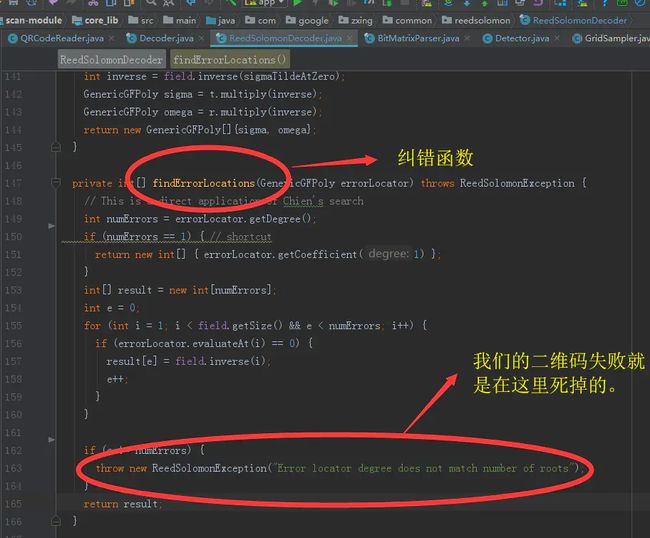
解析终于此处
等等,我们好像忘记说了很重要的一部分内容:
在我们读取二维码的 字节数组数据时,还有一个 mask层换算的过程。
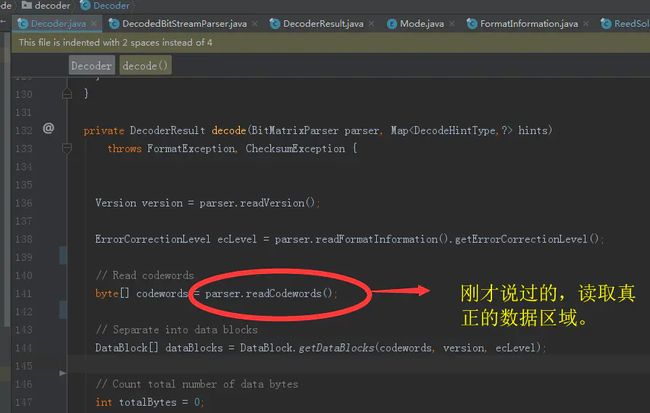
因为二维码本身是一种格式,使用者可以写入任何数据格式进去,很可能造成数据区域出现大面积的空白或者大面积的黑色区域。为了避免这种情况,QRCode内置了八种mask掩码供大家使用。 具体使用的那种信息,是写入到格式信息中,上文有提到。
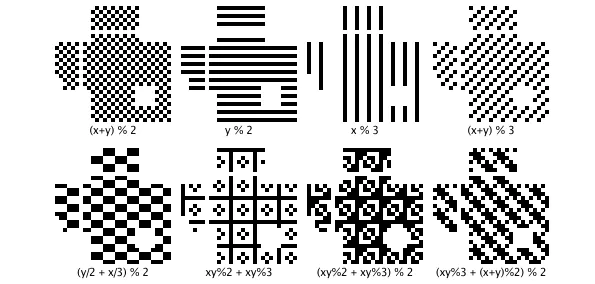
八种掩码
mask解析部分代码:
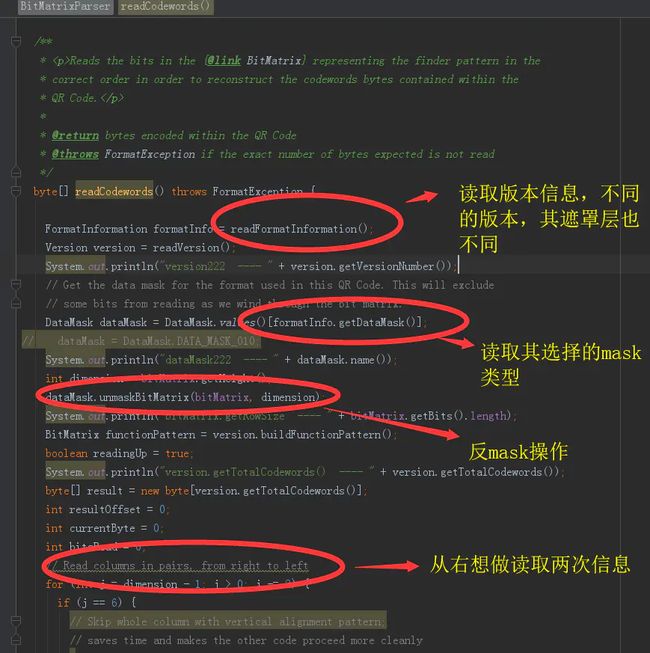
mask部分逻辑
上文中我们提到过,为了二维码的稳定性,QRCode把很多关键数据都会在左下和右上 各存一份,这样子你也就能理解,为什么在阅读ZXing 代码的时候很多地方都是左一次,右一次的来回跳了:
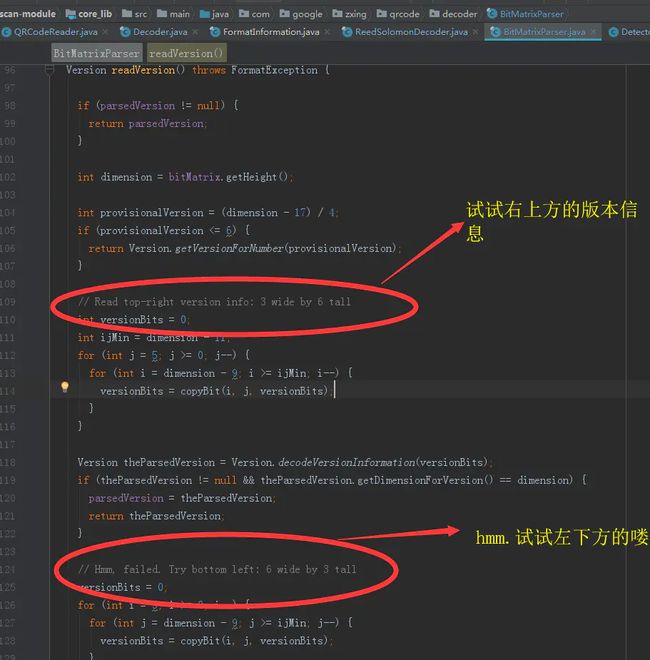
左右跳转的示例
继续我们的流程, 虽然我们二维码最终解析失败在了 数据块纠错的这个环节。
但是逻辑我们还是要继续看下去的。如果是一次成功的扫描流程,那么接下会进行具体的字符编码操作。也就是把0101010的二进制,转换为我们需要的 业务代码需要的文本字符的过程。

打包编码
这里又要膜拜一下设计二维码的大佬了。因为二维码为了实现有限的图像承载尽可能多的数据,所以对于字符的编解码是下了大心思的。

雷彦祖 语录(假装是6吧)
官网描述: 在支持日文的平假字,片假字的前提下,比一般的2D图像容量超出20%

官网描述
二维码所支持的数字,英文,双字节汉字(日文) 不同的内容组合,编码规则是完全不一样的。
具体的编码细节可以看这里:
https://coolshell.cn/articles/10590.html
因此在解析的时候,ZXing也是针对不同的内容组合,进行不同的解析处理:

解析编码的过程
编码结束后,主要工作就已经完成了。接下来就是扔给调用者:
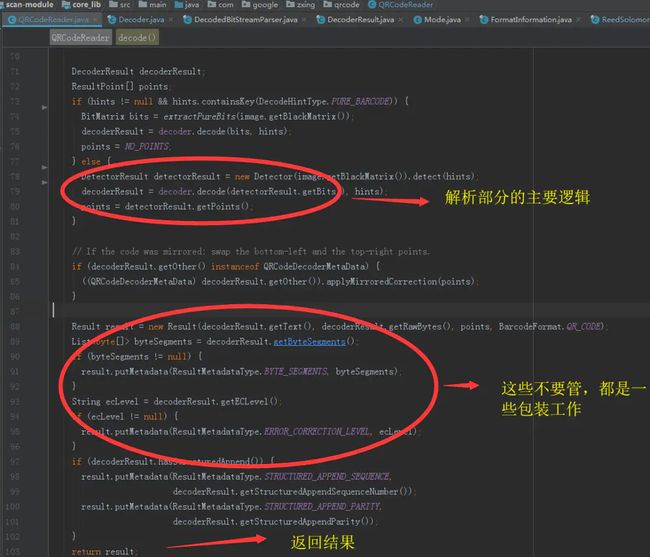
封装返回结果
ZXing解析完成后,返回结果抛给调用者。这里有一点需要注意的是,可以在这里将解析结果的图像以参数的形式返回,便于调试。
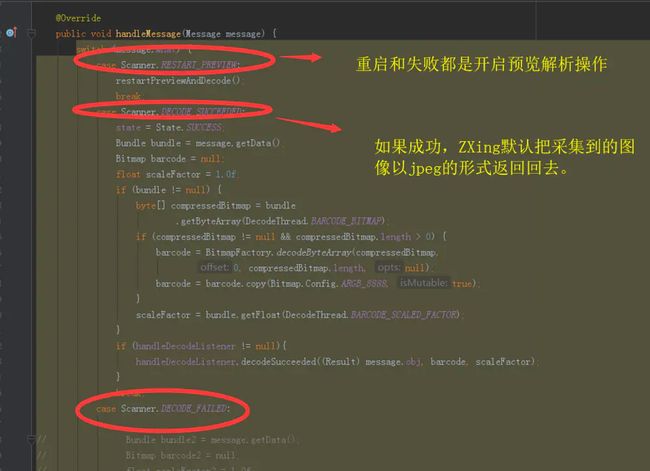
解析的最后的回调
好吧,写了差不多五千字了,总结一下吧。
目前能确定的突破点,是在图像点阵化的透视部分。给自己立个flag,下一篇文档解决掉这个问题。当然如果有大佬可以给点指点,更是求之不得了~~~

大佬,求包养