PHP7 性能优化与新特性
PHP是一种在全球范围内被广泛使用的Web开发语言,PHP7 的革新也当然会给这些Web服务带来更深刻的变化。这里引用鸟哥PPT中的一个图表(82%的Web站点有使用PHP作为开发语言):
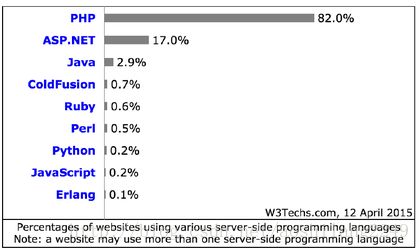
(注:一个web站点可以会使用多种语言作为它的开发语言)
PHP7重写了zend_vm,性能相比于PHP5.6提升了2-3倍,在某些方面相比于早年的HHVM还要优秀。 PHP7 的新增特性很多,不过,我们会更聚焦于那些主要的变化。
1. 性能突破
1.1 JIT与性能
Just In Time(即时编译)是一种软件优化技术,指在运行时才会去编译字节码为机器码。从直觉出发,我们都很容易认为,机器码是计算机能够直接识别和执行的,比起Zend读取opcode逐条执行效率会更高。其中,HHVM(HipHop Virtual Machine,HHVM是一个Facebook开源的PHP虚拟机)就采用JIT,让他们的PHP性能测试提升了一个数量级,放出一个令人震惊的测试结果,也让我们直观地认为JIT是一项点石成金的强大技术。
而实际上,在2013年的时候,鸟哥和Dmitry(PHP语言内核开发者之一)就曾经在PHP5.5的版本上做过一个JIT的尝试(并没有发布)。PHP5.5的原来的执行流程,是将PHP代码通过词法和语法分析,编译成opcode字节码(格式和汇编有点像),然后,Zend引擎读取这些opcode指令,逐条解析执行。
![]()
而他们在opcode环节后引入了类型推断(TypeInf),然后通过JIT生成ByteCodes,然后再执行。
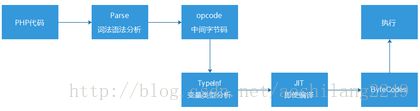
于是,在benchmark(测试程序)中得到令人兴奋的结果,实现JIT后性能比PHP5.5提升了8倍。然而,当他们把这个优化放入到实际的项目WordPress(一个开源博客项目)中,却几乎看不见性能的提升,得到了一个令人费解的测试结果。
于是,他们使用Linux下的profile工具,对程序执行进行CPU耗时占用分析。
执行100次WordPress的CPU消耗的分布(截图来自PPT):

注解:
21%CPU时间花费在内存管理。
12%CPU时间花费在hash table操作,主要是PHP数组的增删改查。
30%CPU时间花费在内置函数,例如strlen。
25%CPU时间花费在VM(Zend引擎)。
经过分析之后,得到了两个结论:
(1)JIT生成的ByteCodes如果太大,会引起CPU缓存命中率下降(CPU Cache Miss)
在PHP5.5的代码里,因为并没有明显类型定义,只能靠类型推断。尽可能将可以推断出来的变量类型,定义出来,然后,结合类型推断,将非该类型的分支代码去掉,生成直接可执行的机器码。然而,类型推断不能推断出全部类型,在WordPress中,能够推断出来的类型信息只有不到30%,能够减少的分支代码有限。导致JIT以后,直接生成机器码,生成的ByteCodes太大,最终引起CPU缓存命中大幅度下降(CPU Cache Miss)。
CPU缓存命中是指,CPU在读取并执行指令的过程中,如果需要的数据在CPU一级缓存(L1)中读取不到,就不得不往下继续寻找,一直到二级缓存(L2)和三级缓存(L3),最终会尝试到内存区域里寻找所需要的指令数据,而内存和CPU缓存之间的读取耗时差距可以达到100倍级别。所以,ByteCodes如果过大,执行指令数量过多,导致多级缓存无法容纳如此之多的数据,部分指令将不得不被存放到内存区域。

CPU的各级缓存的大小也是有限的,下图是Intel i7 920的配置信息:

因此,CPU缓存命中率下降会带来严重的耗时增加,另一方面,JIT带来的性能提升,也被它所抵消掉了。
通过JIT,可以降低VM的开销,同时,通过指令优化,可以间接降低内存管理的开发,因为可以减少内存分配的次数。然而,对于真实的WordPress项目来说,CPU耗时只有25%在VM上,主要的问题和瓶颈实际上并不在VM上。因此,JIT的优化计划,最后没有被列入该版本的PHP7特性中。不过,它很可能会在更后面的版本中实现,这点也非常值得我们期待哈。
(2)JIT性能的提升效果取决于项目的实际瓶颈
JIT在benchmark中有大幅度的提升,是因为代码量比较少,最终生成的ByteCodes也比较小,同时主要的开销是在VM中。而应用在WordPress实际项目中并没有明显的性能提升,原因WordPress的代码量要比benchmark大得多,虽然JIT降低了VM的开销,但是因为ByteCodes太大而又引起CPU缓存命中下降和额外的内存开销,最终变成没有提升。
不同类型的项目会有不同的CPU开销比例,也会得到不同的结果,脱离实际项目的性能测试,并不具有很好的代表性。
1.2 Zval的改变
PHP的各种类型的变量,其实,真正存储的载体就是Zval,它特点是海纳百川,有容乃大。从本质上看,它是C语言实现的一个结构体(struct)。对于写PHP的同学,可以将它粗略理解为是一个类似array数组的东西。
PHP5的Zval,内存占据24个字节(截图来自PPT):

PHP7的Zval,内存占据16个字节(截图来自PPT):

Zval从24个字节下降到16个字节,为什么会下降呢,这里需要补一点点的C语言基础,辅助不熟悉C的同学理解。struct和union(联合体)有点不同,Struct的每一个成员变量要各自占据一块独立的内存空间,而union里的成员变量是共用一块内存空间(也就是说修改其中一个成员变量,公有空间就被修改了,其他成员变量的记录也就没有了)。因此,虽然成员变量看起来多了不少,但是实际占据的内存空间却下降了。
除此之外,还有被明显改变的特性,部分简单类型不再使用引用。
Zval结构图(来源于PPT中):
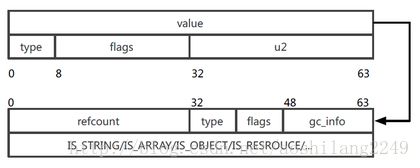
图中Zval的由2个64bits(1字节=8bit,bit是“位”)组成,如果变量类型是long、bealoon这些长度不超过64bit的,则直接存储到value中,就没有下面的引用了。当变量类型是array、objec、string等超过64bit的,value存储的就是一个指针,指向真实的存储结构地址。
对于简单的变量类型来说,Zval的存储变得非常简单和高效。
不需要引用的类型: NULL、Boolean、Long、Double
需要引用的类型: String、Array、Object、Resource、Reference
1.3 内部类型zend_string
Zend_string是实际存储字符串的结构体,实际的内容会存储在val(char,字符型)中,而val是一个char数组,长度为1(方便成员变量占位)。

结构体最后一个成员变量采用char数组,而不是使用char*,这里有一个小优化技巧,可以降低CPU的cache miss。
如果使用char数组,当malloc申请上述结构体内存,是申请在同一片区域的,通常是长度是sizeof(_zend_string) + 实际char存储空间。但是,如果使用char*,那个这个位置存储的只是一个指针,真实的存储又在另外一片独立的内存区域内。
使用char[1>和char*的内存分配对比:

从逻辑实现的角度来看,两者其实也没有多大区别,效果很类似。而实际上,当这些内存块被载入到CPU的中,就显得非常不一样**。前者因为是连续分配在一起的同一块内存,在CPU读取时,通常都可以一同获得(因为会在同一级缓存中)**。而后者,因为是两块内存的数据,CPU读取第一块内存的时候,很可能第二块内存数据不在同一级缓存中,使CPU不得不往L2(二级缓存)以下寻找,甚至到内存区域查到想要的第二块内存数据。这里就会引起CPU Cache Miss,而两者的耗时最高可以相差100倍。
另外,在字符串复制的时候,采用引用赋值,zend_string可以避免的内存拷贝。
1.4. PHP数组的变化(HashTable和Zend Array)
在编写PHP程序过程中,使用最频繁的类型莫过于数组,PHP5的数组采用HashTable实现。如果用比较粗略的概括方式来说,它算是一个支持双向链表的HashTable,不仅支持通过数组的key来做hash映射访问元素,也能通过foreach以访问双向链表的方式遍历数组元素。
PHP5的HashTable(截图来自于PPT):
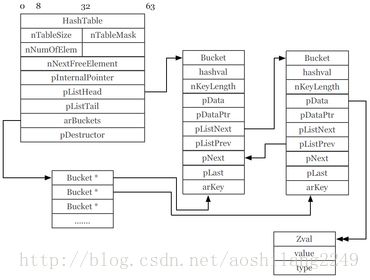
这个图看起来很复杂,各种指针跳来跳去,当我们通过key值访问一个元素内容的时候,有时需要3次的指针跳跃才能找对需要的内容。而最重要的一点,就在于这些数组元素存储,都是分散在各个不同的内存区域的。同理可得,在CPU读取的时候,因为它们就很可能不在同一级缓存中,会导致CPU不得不到下级缓存甚至内存区域查找,也就是引起CPU缓存命中下降,进而增加更多的耗时。
PHP7的Zend Array(截图来源于PPT):
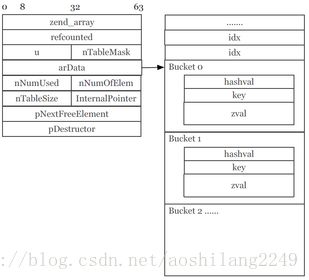
新版本的数组结构,非常简洁,让人眼前一亮。最大的特点是,**整块的数组元素和hash映射表全部连接在一起,被分配在同一块内存内。**如果是遍历一个整型的简单类型数组,效率会非常快,因为,数组元素(Bucket)本身是连续分配在同一块内存里,并且,数组元素的zval会把整型元素存储在内部,也不再有指针外链,全部数据都存储在当前内存区域内。当然,最重要的是,它能够避免CPU Cache Miss(CPU缓存命中率下降)。
Zend Array的变化:
数组的value默认为zval。
HashTable的大小从72下降到56字节,减少22%。
Buckets的大小从72下降到32字节,减少50%。
数组元素的Buckets的内存空间是一同分配的。
数组元素的key(Bucket.key)指向zend_string。
数组元素的value被嵌入到Bucket中。
降低CPU Cache Miss。
1.5 函数调用机制(Function Calling Convention)
PHP7改进了函数的调用机制,通过优化参数传递的环节,减少了一些指令,提高执行效率。
PHP5的函数调用机制(截图来自于PPT):
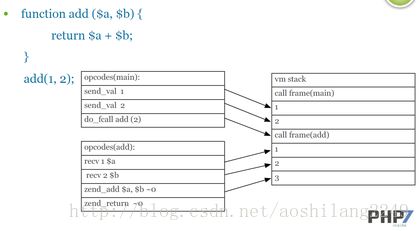
图中,在vm栈中的指令send_val和recv参数的指令是相同,PHP7通过减少这两条重复,来达到对函数调用机制的底层优化。
PHP7的函数调用机制(截图来自于PPT):
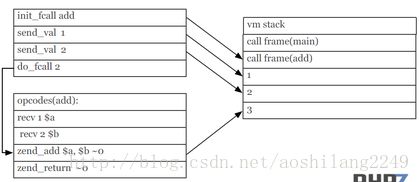
1.6 通过宏定义和内联函数(inline),让编译器提前完成部分工作
C语言的宏定义会被在预处理阶段(编译阶段)执行,提前将部分工作完成,无需在程序运行时分配内存,能够实现类似函数的功能,却没有函数调用的压栈、弹栈开销,效率会比较高。内联函数也类似,在预处理阶段,将程序中的函数替换为函数体,真实运行的程序执行到这里,就不会产生函数调用的开销。
PHP7在这方面做了不少的优化,将不少需要在运行阶段要执行的工作,放到了编译阶段。例如参数类型的判断(Parameters Parsing),因为这里涉及的都是固定的字符常量,因此,可以放到到编译阶段来完成,进而提升后续的执行效率。
例如下图中处理传递参数类型的方式,从左边的写法,优化为右边宏的写法。

2. 新特性
https://secure.php.net/manual/zh/migration70.new-features.php
