ML算法基础——分类算法-决策树、随机森林
文章目录
- 1.决策树
- 1.1 认识决策树
- 1.2 信息论基础-银行贷款分析
- 1.2.1 信息论基础-信息熵
- 1.2.2 决策树的划分依据之一-信息增益
- 1.3 泰坦尼克号乘客生存分类
- 1.3.1 sklearn决策树API
- 1.3.2 泰坦尼克号乘客生存分类模型
- 1.4 决策树的结构、本地保存
- 1.4.1 导出DOT格式
- 1.4.2 安装graphviz
- 1.4.3 运行命令
- 1.5 决策树的优缺点以及改进
- 2.集成学习方法-随机森林
- 2.1 随机森林简述
- 2.2 集成学习API
- 2.3 泰坦尼克号乘客生存分类分析
- 2.4 随机森林的优点
1.决策树
1.1 认识决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
1.2 信息论基础-银行贷款分析
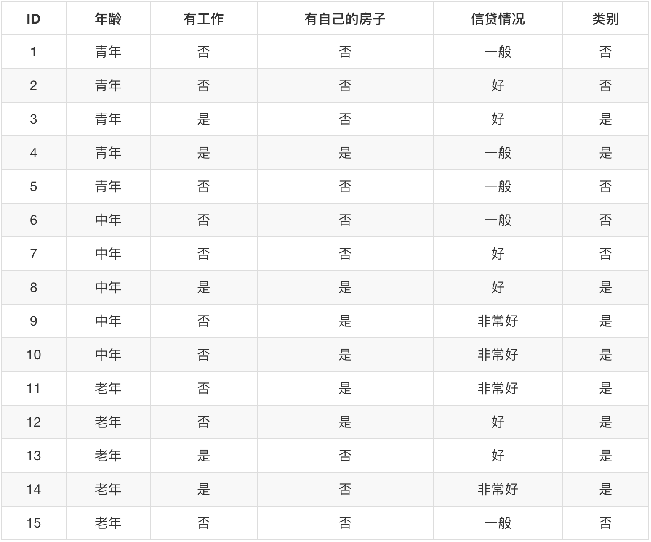
如何去划分是否能得到贷款?
1.2.1 信息论基础-信息熵
香农被称为是“信息论之父”。人们通常将香农于1948年10月发表于《贝尔系统技术学报》上的论文《A Mathematical Theory of Communication》(通信的数学理论)作为现代信息论研究的开端。这一文章部分基于哈里·奈奎斯特和拉尔夫·哈特利先前的成果。在该文中,香农给出了信息熵(以下简称为“熵”)的定义:

H的专业术语称之为信息熵,单位为比特。
这一定义可以用来推算传递经二进制编码后的原信息所需的信道带宽。熵度量的是消息中所含的信息量,其中去除了由消息的固有结构所决定的部分,比如,语言结构的冗余性以及语言中字母、词的使用频度等统计特性。
注:信息和消除不确定性是相联系的
1.2.2 决策树的划分依据之一-信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
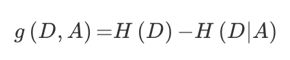
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
信息增益的计算

既然我们有了这两个公式,我们可以根据前面的是否通过贷款申请的例子来通过计算得出我们的决策特征顺序。那么我们首先计算总的经验熵为:
H(D)=-(9/15)log(9/15)-(6/15)log(6/15) = 0.971
然后我们让A1,A2,A3,A4分别表示年龄、有工作、有自己的房子和信贷情况4个特征,则计算出年龄的信息
年龄:
g(D,A1)=H(D)-[(5/15)H(D1)+(5/15)H(D2)+(5/15)H(D3)]
H(D1)=-(2/5)log(2/5)-(3/5)log(3/5)
H(D2)=-(3/5)log(3/5)-(2/5)log(2/5)
H(D3)=-(4/5)log(4/5)-(1/5)log(1/5)
同理其他的也可以计算出来, g(D,A2)=0.324,g(D,A3)=0.420,g(D,A4)=0.363,相比较来说其中特征A3(有自己的房子)的信息增益最大,所以我们选择特征A3为最有特征
1.3 泰坦尼克号乘客生存分类
1.3.1 sklearn决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’,max_depth=None,random_state=None)- 决策树分类器
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’max_depth:树的深度大小random_state:随机数种子method:decision_path:返回决策树的路径
1.3.2 泰坦尼克号乘客生存分类模型
泰坦尼克号数据
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。在泰坦尼克号的数据帧不包含从剧组信息,但它确实包含了乘客的一半的实际年龄。关于泰坦尼克号旅客的数据的主要来源是百科全书Titanica。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。
我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
其中age数据存在缺失。
流程
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def decision():
#获取数据
titan=pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
#处理数据
x=titan[['pclass','age','sex']]
y=titan[['survived']]
print(x)
#缺失值处理
x['age'].fillna(x['age'].mean(),inplace=True)
#分割数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#处理(特征工程)特征-类别-onehot
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test=dict.transform(x_test.to_dict(orient="records"))
# print(x_train)
#决策树预测
dec=DecisionTreeClassifier()
dec.fit(x_train,y_train)
#预测准确率
print("预测的准确率:",dec.score(x_test,y_test))
return None
decision()
结果:
预测的准确率: 0.8054711246200608
1.4 决策树的结构、本地保存
1.4.1 导出DOT格式
sklearn.tree.export_graphviz()
export_graphviz(dec,out_file="./tree.dot",feature_names=['年龄', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=女性', 'sex=男性'])
1.4.2 安装graphviz
工具:(能够将dot文件转换为pdf、png)
- ubuntu:
sudo apt-get install graphviz - Mac:
brew install graphviz - windows:jingyan.baidu.com/article/020278115032461bcc9ce598.html
1.4.3 运行命令
注意:windows下ctrl+r打开cmd,输入完整“dot.exe”的路径才能转换成图片
E:\pycharmproject>"D:\***\graphviz-2.38\bin\dot.exe" -Tpng tree.dot -o tree.png
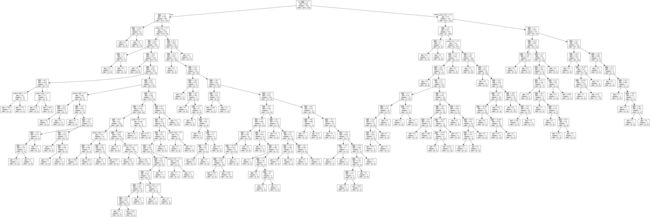
![]()
可以看到已经转换成png格式,打卡文件
1.5 决策树的优缺点以及改进
- 优点:
- 简单的理解和解释,树木可视化
- 需要很少的数据准备,其他技术通常需要数据归一化
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树
被生成
- 改进:
- 减枝cart算法(决策树API中已经实现)
- 随机森林
2.集成学习方法-随机森林
集成学习方法
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
2.1 随机森林简述
定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
学习算法
根据下列算法而建造每棵树:
用N来表示训练用例(样本)的个数,M表示特征数目。
输入特征数目m,用于确定决策树上一个节点的决策结果;其中m应远小于M。
从N个训练用例(样本)中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
为什么要随机抽样训练集?
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
为什么要有放回地抽样?
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
2.2 集成学习API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10,criterion=’gini’,max_depth=None, bootstrap=True,random_state=None)- 随机森林分类器
n_estimators:integer,optional(default = 10)森林里的树木数量criteria:string,可选(default =“gini”)分割特征的测量方法max_depth:integer或None,可选(默认=无)树的最大深度bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样max_features=“auto”,每个决策树的最大特征数量-
- If “auto”, then ‘max_ features= =sqrt(n_ features)’.
- If “sqrt”, then ‘max_ features= =sqrt(n_ features)’(same as “auto”).
- If “log2”, then ‘max_ features: =log2(n_ features)’.
- If None, then ‘max_ features=n_ features’.
2.3 泰坦尼克号乘客生存分类分析
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
def decision():
#获取数据
titan=pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
#处理数据
x=titan[['pclass','age','sex']]
y=titan[['survived']]
#print(x)
#缺失值处理
x['age'].fillna(x['age'].mean(),inplace=True)
#分割数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
#处理(特征工程)特征-类别-onehot
dict=DictVectorizer(sparse=False)
x_train=dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test=dict.transform(x_test.to_dict(orient="records"))
# print(x_train)
#随机森林预测(超参数调优)
rf=RandomForestClassifier()
param={"n_estimators":[100,200,300,500,800,1200],"max_depth":[5,8,15,25,30]}
#网格搜索与交叉验证
gc=GridSearchCV(rf,param_grid=param,cv=2)
print(y_train)
y_train=np.ravel(y_train)
print("_____________________________")
print(y_train)
gc.fit (x_train,y_train)
print("准确率为:",gc.score(x_test,y_test))
print("选择的参数模型:", gc.best_params_)
return None
decision()
2.4 随机森林的优点
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 对于缺省值问题也能够获得很好得结果