linux下安装eclipse开发Spark程序
今天成功在eclipse下开发了一个简单的Scala版WordCount,并在spark集群成功运行(standalone模式)。做个笔记mark一下
前提
安装了jdk,我的环境是1.7.0_79
安装包
Eclipse:eclipse-standard-kepler-SR2-linux-gtk-x86_64.tar.gz
Scala:scala-2.10.6.rpm 下载地址:http://www.scala-lang.org/files/archive/
Eclipse Scala IDE插件: update-site.zip 下载地址:http://download.scala-ide.org/sdk/e38/scala210/stable/
安装过程
1. 把eclipse-standard-kepler-SR2-linux-gtk-x86_64.tar.gz解压缩到/opt下(自定义解压缩到哪里)
tar zxvf eclipse-standard-kepler-SR2-linux-gtk-x86_64.tar.gz
[root@sparkmaster ~]# ll /opt/eclipse/
total 320
drwxrwsr-x. 2 100 users 4096 Feb 24 2014 about_files
-rw-rw-r--. 1 100 users 18732 Jan 17 2014 about.html
-rw-rw-r--. 1 100 users 113671 Feb 24 2014 artifacts.xml
drwxrwsr-x. 11 100 users 4096 Jan 20 18:55 configuration
drwxrwsr-x. 2 100 users 4096 Feb 24 2014 dropins
-rwxr-xr-x. 1 100 users 73031 Jan 15 2014 eclipse
-rw-rw-r--. 1 100 users 449 Jan 20 18:54 eclipse.ini
-rw-rw-r--. 1 100 users 16536 Feb 12 2014 epl-v10.html
drwxrwsr-x. 33 100 users 4096 Jan 20 18:54 features
-rw-rw-r--. 1 100 users 9022 Oct 9 2013 icon.xpm
-rw-rw-r--. 1 100 users 9230 Feb 12 2014 notice.html
drwxrwsr-x. 4 100 users 4096 Feb 24 2014 p2
drwxrwsr-x. 11 100 users 45056 Jan 20 18:54 plugins
drwxrwsr-x. 2 100 users 4096 Feb 24 2014 readme
2. 解压缩update-site.zip并把其features和plugins下的所有jar包都copy到eclipse下对应的features和plugins目录下
3.安装Scala
rpm -ivh scala-2.10.6.rpm
启动eclipse编写程序
进入到/opt/eclipse下启动eclipse:
[root@sparkmaster opt]# ./eclipse/eclipse
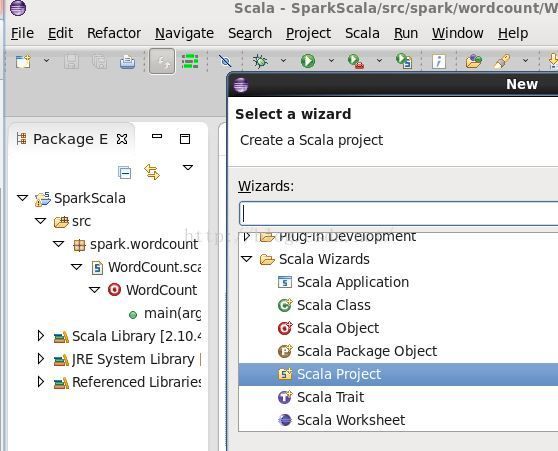
Eclipse打开之后,从file-->new-->others-->Scala Wizards-->Scala Project新建一个project,我命名为SparkScala
右击SparkScala,-->properties-->Java Build Path-->Libraries-->Add External Jars,选择spark安装目录下lib/的assembly jar包:

然后在src包下new一个Scala class,步骤跟上步一样,把包名命名为spark.wordcount,把类名命名为WordCount.进入编辑界面:
简单起见,我的code如下:
package spark.wordcount
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val infile = "/input" // Should be some file on your system
val conf = new SparkConf().setAppName("word count")
val sc = new SparkContext(conf)
val indata = sc.textFile(infile, 2).cache()
val words = indata.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => (a+b))
words.saveAsTextFile("/output")
println("All words are counted!")
}
}其中本地目录/下预先准备好一个input文件,内含一些内容;/output必须不存在,否则运行时会报错。
[root@sparkmaster output]# cat /input
test file
this is for spark test
workcount
fantastic
导出jar包:右击spark.wordcount,选择export-->java-->JAR file-->选择报错路径和jar包名字,我的为/opt/spark-wordcount-in-scala.jar。
在spark上运行
确保master和worker已经在运行,如果没有,先启动。
[root@sparkmaster bin]# jps
3038 Jps
1635 Worker
29749 org.eclipse.equinox.launcher_1.3.0.v20130327-1440.jar
20186 Master
进入[root@sparkmaster ~]# cd /opt/spark-1.6.0-bin-hadoop2.6/bin
提交作业
[root@sparkmaster bin]# ./spark-submit --class spark.wordcount.WordCount /opt/spark-wordcount-in-scala.jar
红色字highlight的部分,需注意,是包名加类名,否则会报找不到类的exception
查看结果
[root@sparkmaster /]# cd output/
[root@sparkmaster output]# ll
total 8
-rw-r--r--. 1 root root 48 Jan 20 23:15 part-00000
-rw-r--r--. 1 root root 32 Jan 20 23:15 part-00001
-rw-r--r--. 1 root root 0 Jan 20 23:15 _SUCCESS
[root@sparkmaster output]# cat part-00000
(this,1)
(is,1)
(workcount,1)
(file,1)
(test,2)
[root@sparkmaster output]# cat part-00001
(spark,1)
(fantastic,1)
(for,1)
至此,哦了~~