Window下Spark环境搭建(可跑代码调试)
前言
这篇博客是在同事的帮忙下完成的,这里我做一个记录,感谢牛逼的同事一波先。哈哈。
本篇博客目的是指导搭建一个Spark的调试环境,在Win10下面。
本人使用的开发工具是IDEA,博客里面用的的所有依赖包会在博客后面分享给需要的朋友,希望能帮助你,跨好大数据入门的一步。
准备工作
为了搭建Spark的调试环境,我们下面需要准备一些工具:
- hadoop-2.8.5.tar(Spark需要依赖于Hadoop)
- scala-2.11.12
- winutils-master(hadoop不可以直接在Win下运行,所以需要这个工具)
- IDEA 2018
- jdk1.8、maven等基础环境
下载安装包
-
下载Spark
我们知道Spark的启动需要依赖于Hadoop,通过官方的说明,可以知道它是在Hadoop对应的版本上面进行构建的。
我们先到Spark官网看看,然后选择我们需要的Spark版本。

我下载spark-2.4.0-bin-hadoop2.7这个版本。根据官网提供的信息,这个Spark版本,构建在Hadoop2.7之后的版本,并且需要Scala版本2.11
-
下载Scala
根据我们Spark的版本,我们到Scala官网下载2.11.12这个Scala SDK版本

-
下载Hadoop
接下来,我们需要到Hadoop官网下载,对应版本的Hadoop.

-
下载winutils-master
由于在win下不可以运行hadoop,虽然我们下载了Hadoop的软件包,还是不可以直接使用。
为了解决这个问题,我们需要额外下载一个东西winutils-master。
然后把里面hadoop-2.8.3\bin里面的文件替换到我们之前hadoop源码包的bin目录下。
环境变量的配置
软件包已经下载完成了,我们开始进行环境变量的配置!

环境变量的配置中,我们需要把环境变量配置在系统变量里面。
如果配置在用户变量里面,当管理员运行用户运行项目的时候,读取不到我们配置的用户变量。

具体的配置说明:
JAVA_HOME=C:\Program Files\Java\jdk1.8.0_181
SPARK_HOME=D:\code\bigData\spark-2.4.0-bin-hadoop2.7
HADOOP_HOME=D:\code\bigData\hadoop-2.8.5
SCALA_HOME=D:\code\bigData\scala-2.11.12

启动Spark
命令行使用命令spark-shell,过一会儿按下回车键。
出现如下界面。

spark在win下启动成功,spark web UI此时也才可以正常访问!!
启动Spark Example进行调试
下载Spark源码
我们需要到github下载spark源代码。

我们选择最新的分支2.4,使用git下载到本地。
git clone https://github.com/apache/spark.git

由于项目是使用Maven构建的,所以我们可以先配置阿里镜像源,加快我们项目的构建速度,maven的setting.xml文件,mirrors节点下,添加如下配置:
nexus-aliyun
central
aliyun
http://maven.aliyun.com/nexus/content/groups/public
然后使用idea打开源码下面的example项目。(idea需要安装Scala插件,请自行安装!)
修改pom文件的scope
运行项目的时候如果scope为provided会遇到下面的异常
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:11)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession$
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 2 more
解决方法是修改pom.xml文件全局替换provided为compile
补充依赖包
此时idea运行项目,看看情况
object SparkPi {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.master("local[1]")//我们spark环境是在本地,所以设置local模式
.appName("Spark Pi")
.getOrCreate()
val slices = if (args.length > 0) args(0).toInt else 2
val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow
val count = spark.sparkContext.parallelize(1 until n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y <= 1) 1 else 0
}.reduce(_ + _)
println(s"Pi is roughly ${4.0 * count / (n - 1)}")
spark.stop()
}
}
出现了下面的异常
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
19/01/09 10:20:29 INFO SparkContext: Running Spark version 3.0.0-SNAPSHOT
Exception in thread "main" java.lang.NoClassDefFoundError: com/google/common/collect/Maps
...
根据异常提示(或者其他google common的错误),我们在pom.xml文件添加依赖包。
com.google.guava
guava
18.0
compile
设置Scala 的SDK
安装依赖包以后,会看到另外一个异常。
"C:\Program Files\Java\jdk1.8.0_181\bin\java.exe" "-javaagent:D:\soft\idea\IntelliJ IDEA 2018.2\lib\idea_rt.jar=50319:D:\soft\idea\IntelliJ IDEA 2018.2\bin" -Dfile.encoding=UTF-8 -classpath "C:\Program Files\Java\jdk1.8.0_181\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\cldrdata.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\jfxrt.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\nashorn.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\sunpkcs11.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\ext\zipfs.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jce.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jfxswt.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\resources.jar;C:\Program Files\Java\jdk1.8.0_181\jre\lib\rt.jar;D:\code\bigData\spark\examples\target\scala-2.12\classes;C:\Users\win 10\.m2\repository\org\apache\orc\orc-core\1.5.4\orc-core-1.5.4-nohive.jar;C:\Users\win 10\.m2\repository\org\apache\orc\orc-shims\1.5.4\orc-shims-1.5.4.jar;C:\Users\win 10\.m2\repository\io\airlift\aircompressor\0.10\aircompressor-0.10.jar;C:\Users\win 10\.m2\repository\org\apache\orc\orc-mapreduce\1.5.4\orc-mapreduce-1.5.4-nohive.jar;C:\Users\win 10\.m2\repository\commons-lang\commons-lang\2.6\commons-lang-2.6.jar;C:\Users\win 10\.m2\repository\commons-codec\commons-codec\1.10\commons-codec-1.10.jar;C:\Users\win 10\.m2\repository\com\github\scopt\scopt_2.12\3.7.0\scopt_2.12-3.7.0.jar;C:\Users\win 10\.m2\repository\com\google\guava\guava\18.0\guava-18.0.jar;C:\Users\win 10\.m2\repository\com\google\collections\google-collections\1.0\google-collections-1.0.jar" org.apache.spark.examples.SparkPi
Exception in thread "main" java.lang.NoClassDefFoundError: scala/collection/Seq
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
Caused by: java.lang.ClassNotFoundException: scala.collection.Seq
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 1 more
此时我们,需要进行Scala的SDK设置。

设置sdk以后,还出现了新的问题
Exception in thread "main" java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;)V
at org.apache.spark.internal.config.ConfigBuilder.(ConfigBuilder.scala:177)
at org.apache.spark.internal.config.Tests$.(Tests.scala:24)
at org.apache.spark.internal.config.Tests$.(Tests.scala)
at org.apache.spark.util.Utils$.isTesting(Utils.scala:1851)
at org.apache.spark.sql.SparkSession$.org$apache$spark$sql$SparkSession$$assertOnDriver(SparkSession.scala:1085)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:915)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:32)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
Process finished with exit code 1
这个是scala版本错误!!
搜索发现依赖的scala版本确实,不一致
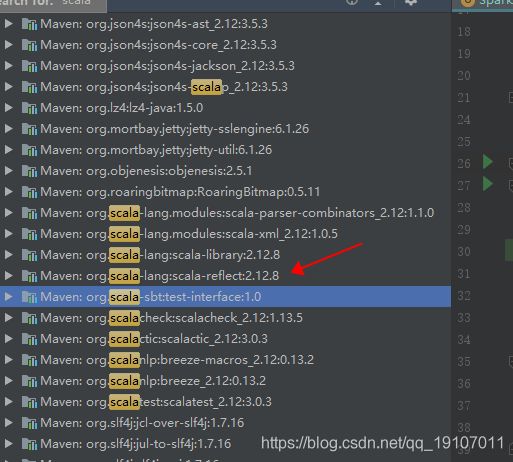
那好吧,我们修改scala的sdk试试
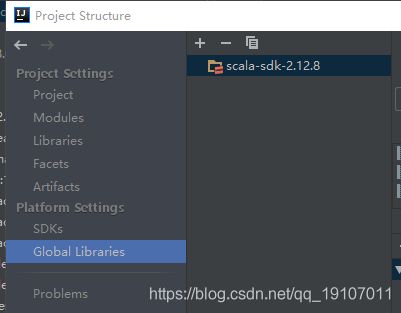
重新运行项目,发现正常了,所以我们没有用我们下载的scala,sdk使用IDEA插件重新下了一个2.12.8的版本。(这里和官方说的,也就是我们最上面分析的有点出入哦)
运行example例子
经过了重重修改终于可以正常运行了!!

安装包分享

链接:https://pan.baidu.com/s/1ZAwjeqXbEtDIMOKSTtcyxQ
提取码:hp1k