Redis的过期策略和内存淘汰策略及LRU算法详解
1 设置带过期时间的 key
expire key seconds
时间复杂度:O(1)
设置key的过期时间。超时后,将会自动删除该key。在Redis的术语中一个key的相关超时是volatile的。
超时后只有对key执行DEL、SET、GETSET时才会清除。 这意味着,从概念上讲所有改变key而不用新值替换的所有操作都将保持超时不变。 例如,使用 INCR 递增key的值,执行 LPUSH 将新值推到 list 中或用 HSET 改变hash的field,这些操作都使超时保持不变。
- 使用
PERSIST命令可以清除超时,使其变成一个永久key - 若
key被RENAME命令修改,相关的超时时间会转移到新key - 若
key被RENAME命令修改,比如原来就存在Key_A,然后调用RENAME Key_B Key_A命令,这时不管原来Key_A是永久的还是设为超时的,都会由Key_B的有效期状态覆盖
注意,使用非正超时调用 EXPIRE/PEXPIRE 或具有过去时间的 EXPIREAT/PEXPIREAT 将导致key被删除而不是过期(因此,发出的key事件将是 del,而不是过期)。
1.1 刷新过期时间
对已经有过期时间的key执行EXPIRE操作,将会更新它的过期时间。有很多应用有这种业务场景,例如记录会话的session。
1.2 Redis 之前的 2.1.3 的差异
在 Redis 版本之前 2.1.3 中,使用更改其值的命令更改具有过期集的密钥具有完全删除key的效果。由于现在修复的复制层中存在限制,因此需要此语义。
EXPIRE 将返回 0,并且不会更改具有超时集的键的超时。
1.3 返回值
1如果成功设置过期时间。0如果key不存在或者不能设置过期时间。
1.4 示例
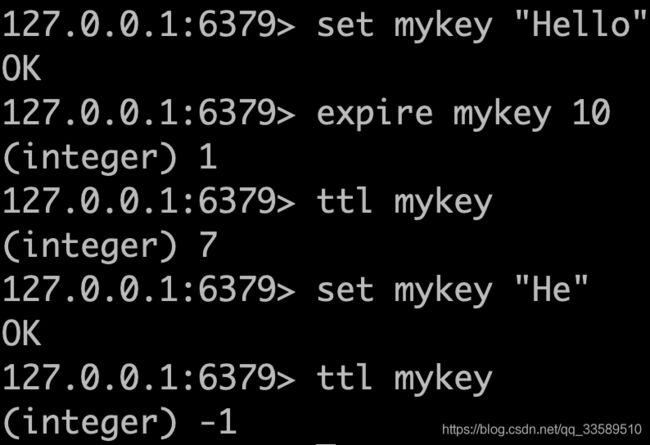
假设有一 Web 服务,对用户最近访问的最新 N 页感兴趣,这样每个相邻页面视图在上一个页面之后不超过 60 秒。从概念上讲,可以将这组页面视图视为用户的导航会话,该会话可能包含有关ta当前正在寻找的产品的有趣信息,以便你可以推荐相关产品。
可使用以下策略轻松在 Redis 中对此模式建模:每次用户执行页面视图时,您都会调用以下命令:
MULTI
RPUSH pagewviews.user:<userid> http://.....
EXPIRE pagewviews.user:<userid> 60
EXEC
如果用户空闲超过 60 秒,则将删除该key,并且仅记录差异小于 60 秒的后续页面视图。
此模式很容易修改,使用 INCR 而不是使用 RPUSH 的列表。
1.5 带过期时间的 key
通常,创建 Redis 键时没有关联的存活时间。key将永存,除非用户以显式方式(例如 DEL 命令)将其删除。
EXPIRE 族的命令能够将过期项与给定key关联,但代价是该key使用的额外内存。当key具有过期集时,Redis 将确保在经过指定时间时删除该key。
可使用 EXPIRE 和 PERSIST 命令(或其他严格命令)更新或完全删除生存的关键时间。
1.6 过期精度
在 Redis 2.4 中,过期可能不准确,并且可能介于 0 到 1 秒之间。
由于 Redis 2.6,过期误差从 0 到 1 毫秒。
1.7 过期和持久化
过期信息的键存储为绝对 Unix 时间戳(Redis 版本 2.6 或更高版本为毫秒)。这意味着即使 Redis 实例不处于活动状态,时间也在流动。
要使过期工作良好,必须稳定计算机时间。若将 RDB 文件从两台计算机上移动,其时钟中具有大 desync,则可能会发生有趣的事情(如加载时加载到过期的所有key)。
即使运行时的实例,也始终会检查计算机时钟,例如,如果将一个key设置为 1000 秒,然后在将来设置计算机时间 2000 秒,则该key将立即过期,而不是持续 1000 秒。
2 Redis 如何使key过期
键的过期方式有两种:被动方式 - 惰性删除,主动方式 - 定期删除。
2.1 惰性删除
当客户端尝试访问key时,key会被动过期,即Redis会检查该key是否设置了过期时间,如果过期了就会删除,也不会返回任何东西。
注意并非是key到期了就会被自动删除,而是当查询该key时,Redis再很懒惰地检查是否删除。这和 spring 的延迟初始化有着异曲同工之妙。
当然,这是不够的,因为有过期的key,永远不会再访问。无论如何,这些key都应过期,因此请定期 Redis 在具有过期集的key之间随机测试几个key。已过期的所有key将从key空间中删除。
2.2 定期删除
具体来说,如下 Redis 每秒 10 次:
- 测试 20 个带有过期的随机键
- 删除找到的所有已过期key
- 如果超过 25% 的key已过期,从步骤 1 重新开始
这是一个微不足道的概率算法,基本上假设我们的样本代表整个key空间,继续过期,直到可能过期的key百分比低于 25%。
这意味着在任何给定时刻,使用内存的已过期的最大键量等于最大写入操作量/秒除以 4。
2.3 在复制链路和 AOF 文件中处理过期的方式
为了在不牺牲一致性的情况下获得正确行为,当key过期时,DEL 操作将同时在 AOF 文件中合成并获取所有附加的从节点。这样,过期的这个处理过程集中到主节点中,还没有一致性错误的可能性。
但是,虽然连接到主节点的从节点不会独立过期key(但会等待来自master的 DEL),但它们仍将使用数据集中现有过期的完整状态,因此,当选择slave作为master时,它将能够独立过期key,完全充当master。
可是,很多过期key,你没及时去查,定期删除也漏掉了,大量过期key堆积内存,Redis内存殆耗尽!
因此还需有内存淘汰机制!
3 内存淘汰
3.1 内存淘汰策略
noeviction(Redis默认策略)
不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样
可以保证不会丢失数据,但是会让线上的业务不能持续进行。
- config.c
createEnumConfig("maxmemory-policy", NULL,
MODIFIABLE_CONFIG, maxmemory_policy_enum,
server.maxmemory_policy,
MAXMEMORY_NO_EVICTION, NULL, NULL),
allkeys-random
当内存不足以容纳新写入数据时,在键空间中,随机移除某key。凭啥随机呢,至少也是把最近最少使用的key删除。
allkeys-lru(Least Recently Used)
当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key,没有设置过期时间的 key 也会被淘汰。
allkeys-lfu(Least Frequently Used)
LRU的关键是看页面最后一次被使用到发生调度的时间长短,而LFU关键是看一定时间段内页面被使用的频率。
volatile-lru
尝试淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。
没有设置过期时间的 key 不会被淘汰,这样可以保证需要持久化的数据不会突然丢失。
区别于 allkey-lru,这个策略要淘汰只是过期的 key 集合。
volatile-lfu
volatile-random
淘汰的 key 是过期 key 集合中随机的 key。
volatile-ttl
淘汰的策略不是 LRU,而是 key 的剩余寿命 ttl 的值,ttl
越小越优先被淘汰。
volatile-xxx 策略只会针对带过期时间的 key 进行淘汰,allkeys-xxx 策略会对所有的 key 进行淘汰。
- 如果你只是拿 Redis 做缓存,那应该使用 allkeys-xxx,客户端写缓存时不必携带过期时间。
- 如果你还想同时使用 Redis 的持久化功能,那就使用 volatile-xxx 策略,这样可以保留没有设置过期时间的 key,它们是永久的 key 不会被 LRU 算法淘汰。
3.2 手写LRU
确实有时会问这个,因为有些候选人如果确实过五关斩六将,前面的问题都答的很好,那么其实让他写一下LRU算法,可以考察一下编码功底
你可以现场手写最原始的LRU算法,那个代码量太大了,不太现实
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE;
// 这里就是传递进来最多能缓存多少数据
public LRUCache(int cacheSize) {
// true指linkedhashmap将元素按访问顺序排序
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
// 当KV数据量大于指定缓存个数时,就自动删除最老数据
return size() > CACHE_SIZE;
}
}
参考
- https://redis.io/commands#generic