笔记:前端自学基础之正则表达式
转义字符"\"
多行字符串:
document.body.innerHTML = "\
\
<\span>\
";
字符串换行符\n;行结束:\r;制表符:\t(缩进)
正则表达式 RegExp
正则表达式的作用:匹配特殊字符或有特殊搭配原则的字符的最佳选择。 贪婪匹配原则。
两种创建方式:
1、字面量 (推荐) /pattern/attributes
var reg1 = /abc/i;
var str = "abcd";
reg1.test(str);//true 返回true或者false
str.match(reg1);//["abc"] 返回的是数组2、new RegExp(pattern,attributes);
var str = "abcd"
var reg2 = new RegExp("abc","i");
注:
若 var reg2 = new RegExp(reg1);则此时reg1与reg2内部值相同,但是指向两个引用。
但若 var reg2 = RegExp(reg1);则此时reg1与reg2内部值相同,且指向同一个引用。修饰符:
i:执行对大小写不敏感的匹配;
g:执行全局匹配(查找所有匹配而非在找到第一个匹配后停止);
m :执行多行匹配。
var reg = /^a/g;
var reg2 = /^a/gm;
var str = "abcde\na";//包含换行
str.match(reg);//["a"]
str.match(reg2);//["a","a"]多行匹配
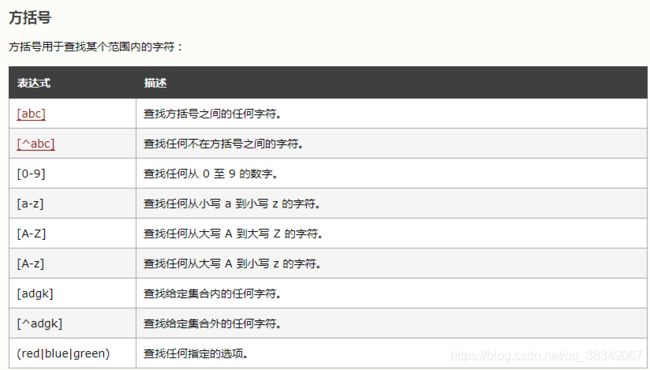
一个方括号代表一位!(red|blue\green)匹配"red"或"blue"或"green"
var reg = /[0123456789][0123456789][0123456789]/g;//表示全局匹配连续的三个数字
var str = "12309u98723lashgkjghajh";
str.match(reg);//["123","987"]
元字符也代表一位!方括号里也可以写元字符! var reg = /[\w\d]/g;
\w === [0-9A-z_] \d === [0-9] \s === [\t\n\r\v\f ] 最后一个是空格 \b === 单次边界 . === [^\r\n]
\W === [^\w] \D === [^\d] \S === [^\s] \B ===非单次边界
var reg1 = /\bcde/g;//单次边界必须是在c之前的那个
var reg2 = /\bc/g;//匹配的是第二个c
var str = "abc cde fgh"'
str.match(reg1);//"cde"结果中不包含前面的空格
str.match(reg2);//"c"结果中不包含前面的空格
unicode编码 \uxxxx后面四位一般指常见的第一层的所有unicode编码,实际应该为\u01xxxx。另外十五层表示为(\u020000-\u02ffff)-(\u100000-\u10ffff)
var reg = /\u8001\u9093\u8eab\u4f53\u597d/g;
var str = "老邓身体好";
str.match(reg);//"老邓身体好"

贪婪匹配原则,尽量匹配最多的。n+ : {1,} n* : {0,}

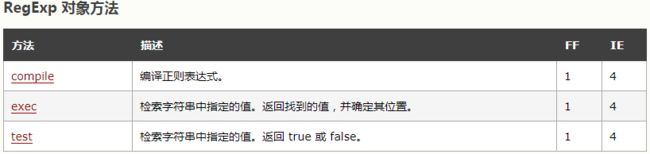
reg.exec()和lastIndex相对应相匹配,且lastIndex可以手动修改。不使用全局匹配时,lastIndex值始终为0.
匹配连续出现的相同字符:var reg = /(\w)\1\1\1/g \1表示反向引用第一个子表达式的内容也就是第一个\w,这样一来,字符串如"aaaa"、"bbbb"都能匹配出来。如果要匹配出"aabb",则需要reg = /(\w)\1(\w)\2/g,这里的\2表示反向引用第二个子表达式,也就是第二个\w。
var str = "aabb";
var reg = /(\w)\1(\w)\2/;
console.log(reg.exec(str));//["aabb","a","b",index:0,input:"aabb"]
var str = "aabb";
var reg1 = /(\w)\1(\w)\2/;
var reg2 = /(\w)\1(\w)\2/g;
console.log(str.match(reg1));//["aabb","a","b",index:0,input:"aabb"]
//返回匹配结果和两个子表达式的内容
console.log(str.match(reg2));//["aabb"]
//全局搜索时,返回的结果中不包含子表达式的内容search匹配不到的话,返回-1,匹配到的话,返回匹配到的位置,且仅仅返回匹配到的第一个字符的位置,其后再有匹配到的也不会返回结果。所以search只管能不能匹配到,而不管能匹配到多少,更不用说其他匹配成功的字符位置了。
对于split方法,如果正则表达式中含有子表达式,则会在每一截分割的结果后跟着子表达式的内容。不管是不是全局搜索。
var str = "aa";
str1 = str.replace("a","b");
console.log(str1);//ba replace方法只对字符串的第一个指定字符进行了替换操作,它没有访问全局的能力
console.log(str);//aa replace方法不更改原来的字符串
var reg = /a/g;
str1 = str.replace(reg,"b");
console.log(str1);//bb 使用正则表达式全局匹配,可以全局替换
console.log(str);//aa 对原来的字符串依旧没有影响replace方法的第二个参数必须是字符串格式(或者是用function但是返回的是字符串),其内部使用$1时表示的是第一个参数正则表达式的第一个子表达式,$2表示的是第一个参数正则表达式的第二个子表达式。(replace方法的精华)
var reg = /(\w)\1(\w)\2/g;
var str = "aabb";
console.log(str.replace(reg,"$2$2$1$1"));//bbaa
console.log(str.replace(reg,function($,$1,$2){
return $2 + $2 + $1 + $1;
}));//bbaareplace方法的第二个参数使用function时,系统自动传参。传递的第一个参数是全局匹配时每一次匹配到的str中的字符(串),往后依次为正则表达式匹配出的第一个子表达式第二个子表达式等。
e.g:将the-first-name变成theFirstName(小驼峰式)
var reg = /-(\w)/g;
var str = "the-first-name";
str.replace(reg,function($,$1){
return $1.toUpperCase
});//theFirstName全局匹配中,匹配了多少次,function就会执行多少次!
正向预查 正向断言
var str = "abaaaaaa";
var reg = /a(?=b)/g;//这里的(?=b)表示a后面需要跟一个b,但是b不参与选择,只参与修饰限定。
str.match(reg);//"a" 这里只能选出一个"a"
var str = "abaaaaaa";
var reg = /a(?!b)/g;//这里的(?!b)表示a后面不能跟b,此时的括号内容也只参与修饰限定。
str.match(reg);//"a","a","a","a","a","a" 这里能选出六个"a"非贪婪匹配
将默认的贪婪匹配更改成为非贪婪匹配的方法为:在正则表达式内部末尾加一个?
var str = "aaaaaa";
var reg1 = /a+?/g;
var reg2 = /a+/g;
var reg3 = //
str.match(reg1);//["a","a","a","a","a","a"]
str.match(reg2);//["aaaaaa"]练习
将var str = "10000000000" 匹配替换为10,000,000,000
var str = "10000000000";
var reg = /(\d\d\d)/g;
console.log(str.split('').reverse().join('').replace(reg,function($,$1){
return $1+',';
}).split('').reverse().join(''));//'10,000,000,000' 解法一
var reg2 = /(?=(\B)(\d{3})+$)/g;
console.log(str.replace(reg2,","));//'10,000,000,000' 解法二