windows下用idea编写wordcount单词计数项目并打jar包上传到hadoop执行
编写环境:windows ,IntelliJ IDEA 2018.1.4 x64 ,maven,jdk-1.8
运行环境:centos-7.3,hadoop-2.7.3,jdk-1.8
基本思路:在windows中的idea新建maven项目wordcount并编写,将项目打包成jar,上传至hadoop并执行作业
一、新建maven项目
1、菜单File——>New——>Project…——>Maven(编写环境的jdk和运行环境的jdk最好一致),结果如下:
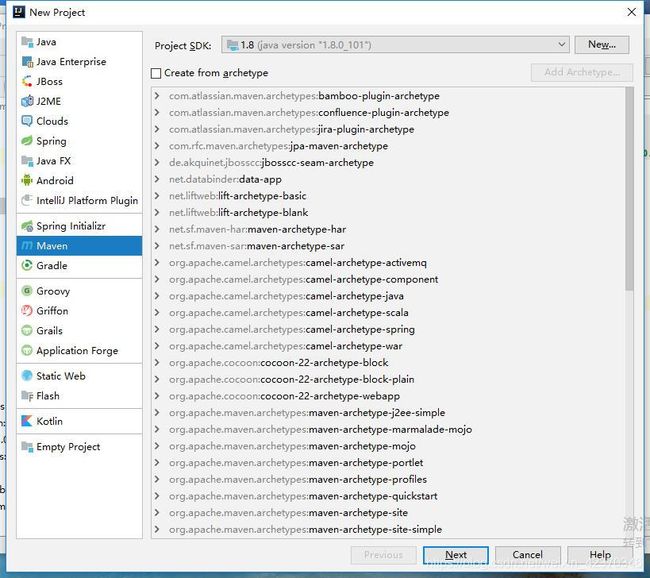
2、点击Next,结果如下:
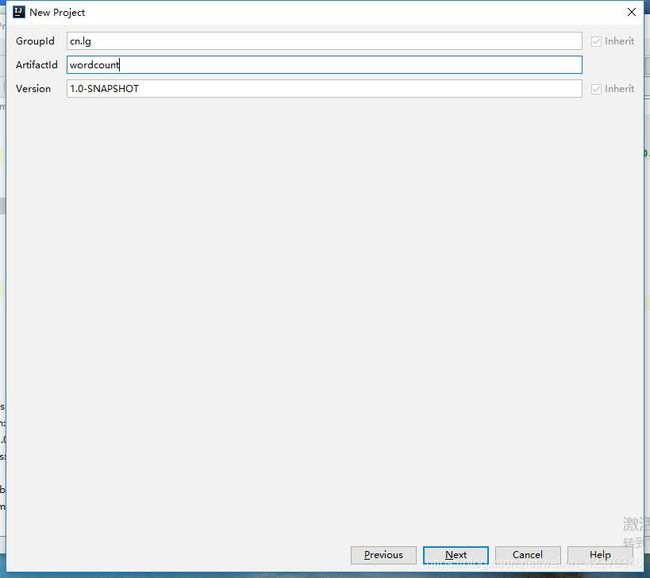
3、填好GroupId和ArtifactId,点击Next,结果如下:

4、Finish.
二、编写wordcount项目
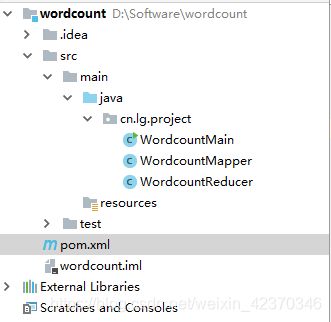
1、建立项目结构目录
2、编写pom.xml(引入用到的jar包)
4.0.0
cn.lg
wordcount
1.0-SNAPSHOT
org.apache.hadoop
hadoop-common
2.7.3
org.apache.hadoop
hadoop-hdfs
2.7.3
org.apache.hadoop
hadoop-mapreduce-client-common
2.7.3
org.apache.hadoop
hadoop-mapreduce-client-core
2.7.3
3、编写项目代码
(1)WordcountMapper.java
package cn.lg.project;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import java.io.IOException;
public class WordcountMapper extends org.apache.hadoop.mapreduce.Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] words=line.split(" ");
for (String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
(2)WordcountReducer.java
package cn.lg.project;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordcountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
Integer counts=0;
for (IntWritable value:values){
counts+=value.get();
}
context.write(key,new IntWritable(counts));
}
}
(3)WordcountMain.java
package cn.lg.project;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordcount");
job.setJarByClass(WordcountMain.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean flag = job.waitForCompletion(true);
if (!flag) {
System.out.println("wordcount failed!");
}
}
}
三、将项目打包成jar
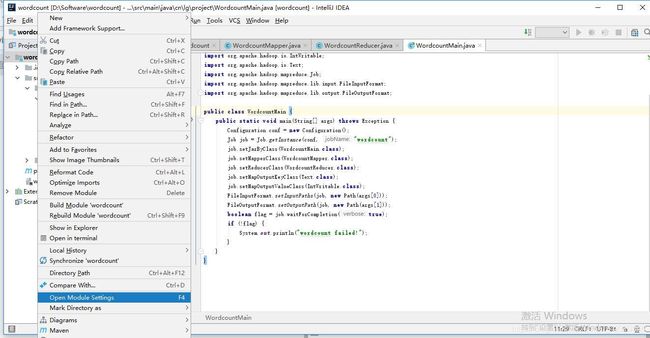
1、右键项目名称——>Open Module Settings,如下:
2、Artifacts——>+——>JAR——>From modules with dependencies…,如下:
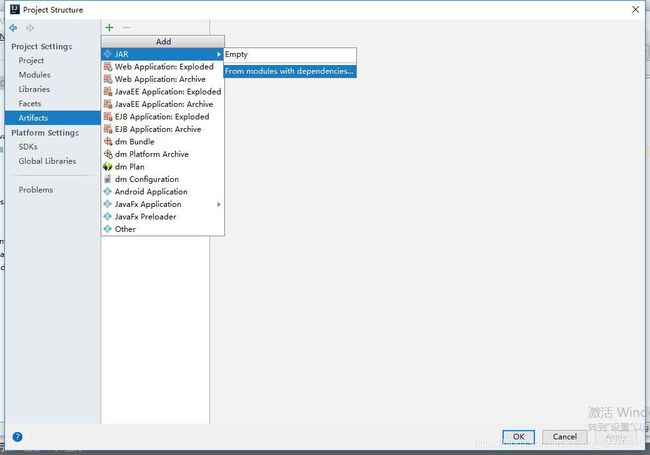
3、填写Main Class(点击…选择WordcountMain),再然后下面有两个选项,第一个是
extract to the target JAR,指将项目及项目依赖的包都打包成一个JAR(结果运行比较慢,见附录),第二个是copy to the output directory and link via manifest,指其他依赖包分开放,结果为多个JAR,因为执行环境hadoop上已经有相关的依赖包,这里选第二个,点击ok,如下:
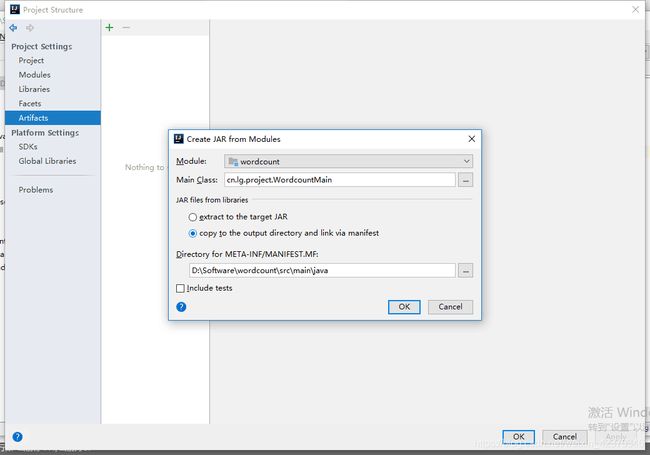
4、勾选include in project build ,其中Output directory为最后的输出目录,下面output layout是输出的各jar包,点击ok,如下:

5、点击菜单Build——>Build Aritifacts…,如下:

6、选择Build,结果可到前面4的output目录查看或者项目结构中的out目录,如下:
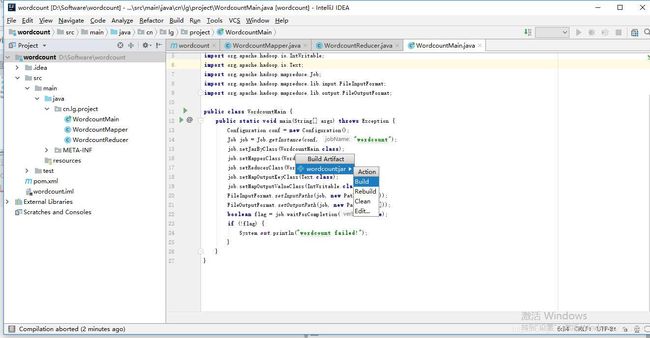
7、结果查看如下,找到wordcount.jar,并上传到hadoop:

四、执行验证
1、新建测试文本testdata,并添加内容“I believe that I will be successful”,上传至hdfs,如下可查看:
[hadoop@master ~]$ hdfs dfs -cat /user/hadoop/input/testdata
19/03/20 14:35:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
I believe that I will be successful
2、执行命令,注意命令的形式,只有两个参数,主类已经在代码和打jar包的时候设置了,所以这里命令不用输入,和使用hadoop自带的wordcount不一样,况且代码中args[0]已经设置为输入路径了,args[1]为输出路径,查看结果:
[hadoop@master ~]$ hadoop jar wordcount.jar /user/hadoop/input/testdata /user/hadoop/output3
19/03/20 14:39:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/03/20 14:39:26 INFO client.RMProxy: Connecting to ResourceManager at master/172.16.0.17:8032
19/03/20 14:39:27 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
19/03/20 14:39:28 INFO input.FileInputFormat: Total input paths to process : 1
19/03/20 14:39:28 INFO mapreduce.JobSubmitter: number of splits:1
19/03/20 14:39:28 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1553002961722_0009
19/03/20 14:39:29 INFO impl.YarnClientImpl: Submitted application application_1553002961722_0009
19/03/20 14:39:29 INFO mapreduce.Job: The url to track the job: http://master:8077/proxy/application_1553002961722_0009/
19/03/20 14:39:29 INFO mapreduce.Job: Running job: job_1553002961722_0009
19/03/20 14:39:39 INFO mapreduce.Job: Job job_1553002961722_0009 running in uber mode : false
19/03/20 14:39:39 INFO mapreduce.Job: map 0% reduce 0%
19/03/20 14:39:46 INFO mapreduce.Job: map 100% reduce 0%
19/03/20 14:39:53 INFO mapreduce.Job: map 100% reduce 100%
19/03/20 14:39:55 INFO mapreduce.Job: Job job_1553002961722_0009 completed successfully
19/03/20 14:39:56 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=84
FILE: Number of bytes written=236613
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=146
HDFS: Number of bytes written=46
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4552
Total time spent by all reduces in occupied slots (ms)=4754
Total time spent by all map tasks (ms)=4552
Total time spent by all reduce tasks (ms)=4754
Total vcore-milliseconds taken by all map tasks=4552
Total vcore-milliseconds taken by all reduce tasks=4754
Total megabyte-milliseconds taken by all map tasks=4661248
Total megabyte-milliseconds taken by all reduce tasks=4868096
Map-Reduce Framework
Map input records=1
Map output records=7
Map output bytes=64
Map output materialized bytes=84
Input split bytes=110
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=84
Reduce input records=7
Reduce output records=6
Spilled Records=14
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=157
CPU time spent (ms)=1320
Physical memory (bytes) snapshot=302055424
Virtual memory (bytes) snapshot=4166328320
Total committed heap usage (bytes)=165810176
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=36
File Output Format Counters
Bytes Written=46
第一个为hdfs中的输入目录,第二个为hdfs的输出目录,输出目录不能先存在,否则会报错。
3、再次验证:
[hadoop@master ~]$ hdfs dfs -cat /user/hadoop/output3/part-r-00000
19/03/20 14:44:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
I 2
be 1
believe 1
successful 1
that 1
will 1
五、附录
若将整个项目都打成jar包,结果会很慢,运行如下:
[hadoop@master ~]$ hadoop jar wordcount.jar /user/hadoop/input/testdata /user/hadoop/output4
19/03/20 15:09:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/03/20 15:09:59 INFO client.RMProxy: Connecting to ResourceManager at master/172.16.0.17:8032
19/03/20 15:10:00 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
19/03/20 15:18:03 WARN hdfs.DFSClient: Slow waitForAckedSeqno took 41091ms (threshold=30000ms)
19/03/20 15:18:03 INFO input.FileInputFormat: Total input paths to process : 1
19/03/20 15:18:04 INFO mapreduce.JobSubmitter: number of splits:1
19/03/20 15:18:04 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1553002961722_0011
19/03/20 15:18:05 INFO impl.YarnClientImpl: Submitted application application_1553002961722_0011
19/03/20 15:18:05 INFO mapreduce.Job: The url to track the job: http://master:8077/proxy/application_1553002961722_0011/
19/03/20 15:18:05 INFO mapreduce.Job: Running job: job_1553002961722_0011
19/03/20 15:26:37 INFO mapreduce.Job: Job job_1553002961722_0011 running in uber mode : false
19/03/20 15:26:37 INFO mapreduce.Job: map 0% reduce 0%
19/03/20 15:26:43 INFO mapreduce.Job: map 100% reduce 0%
19/03/20 15:26:50 INFO mapreduce.Job: map 100% reduce 100%
19/03/20 15:26:52 INFO mapreduce.Job: Job job_1553002961722_0011 completed successfully
19/03/20 15:26:52 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=84
FILE: Number of bytes written=236613
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=146
HDFS: Number of bytes written=46
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4610
Total time spent by all reduces in occupied slots (ms)=5078
Total time spent by all map tasks (ms)=4610
Total time spent by all reduce tasks (ms)=5078
Total vcore-milliseconds taken by all map tasks=4610
Total vcore-milliseconds taken by all reduce tasks=5078
Total megabyte-milliseconds taken by all map tasks=4720640
Total megabyte-milliseconds taken by all reduce tasks=5199872
Map-Reduce Framework
Map input records=1
Map output records=7
Map output bytes=64
Map output materialized bytes=84
Input split bytes=110
Combine input records=0
Combine output records=0
Reduce input groups=6
Reduce shuffle bytes=84
Reduce input records=7
Reduce output records=6
Spilled Records=14
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=180
CPU time spent (ms)=1360
Physical memory (bytes) snapshot=310743040
Virtual memory (bytes) snapshot=4172840960
Total committed heap usage (bytes)=165810176
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=36
File Output Format Counters
Bytes Written=46