MIT-JOS系列4:内存管理
在MIT-JOS lab1的实验中我们了解了bootloader和kernel载入的过程,并在kernel中完成了最初的虚拟内存映射、栈设置和硬件相关的一系列初始化。在Lab2中,我们将在JOS操作系统中实现分页内存管理,其包括:
- 物理页面管理(对机器拥有的物理内存的管理,包括建立对应的数据结构、处理分配和回收动作等)
- 虚拟内存管理(将内核和用户软件使用的虚拟地址映射到物理地址)
在lab2开始之前,JOS的内存布局如下图所示:
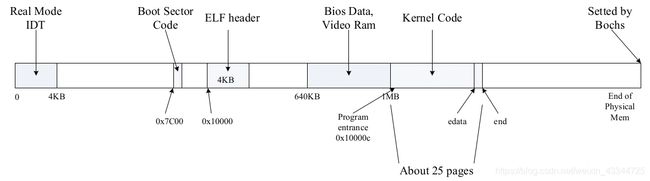
物理页面管理
在物理页面管理部分,我们为页表目录分配内存,完成页表目录的初始化,完成页面数据结构和空闲页面链表的初始化。页面数据结构是一个管理物理内存分割成的所有页面的数组,其中每一项包括指向下一空闲页面的指针和页面的引用计数,在物理页面管理过程中,将找出物理内存中不可使用的页面将其引用计数记为1,其他页放入空闲页面链表中
i386_detect_memory():读CMOS获取物理内存的实际大小
在32位i386上,页面大小固定为4KB,因此页面总数(npage)=物理内存大小>>12(除以4K)
在MIT-JOS系列2:bool loader过程中提到:
对虚拟地址0xf0000000 ~ 0xf0400000和0x00000000 ~ 0x00400000的访问被映射到物理地址0x00000000 ~ 0x00400000
因此内核的虚拟地址从KERNBASE=0xF0000000开始
初始化页表目录
首先调用 boot_alloc() 为页表目录分配一页的内存:
kern_pgdir = (pde_t *) boot_alloc(PGSIZE);
kern_pgdir 为指向操作系统页表目录的指针。操作系统之后在保护模式下工作,通过该页表目录查找页表进行地址转换
boot_alloc()内部代码如下:
static void *
boot_alloc(uint32_t n)
{
static char *nextfree; // virtual address of next byte of free memory
char *result;
// Initialize nextfree if this is the first time.
// 'end' is a magic symbol automatically generated by the linker,
// which points to the end of the kernel's bss segment:
// the first virtual address that the linker did *not* assign
// to any kernel code or global variables.
if (!nextfree) {
extern char end[];
nextfree = ROUNDUP((char *) end, PGSIZE);
}
// Allocate a chunk large enough to hold 'n' bytes, then update
// nextfree. Make sure nextfree is kept aligned
// to a multiple of PGSIZE.
//
// LAB 2: Your code here.
result = nextfree;
nextfree = ROUNDUP(nextfree+n, PGSIZE);
if (nextfree-KERNBASE > npages*PGSIZE)
panic("Out of memory!\n");
return result;
}
nextfree指明下一可用内存字节的虚拟地址。从JOS的内存布局图中可以发现,物理地址的使用是不连续的,程序的各部分分散地载入在物理内存中,而在使用虚拟地址后,内存的使用可以“看作”是连续的。
初始状态下nextfree指向kernel后第一个可用的虚拟地址并向高地址页对齐,在这段程序中我们为kern_pgdir分配一整个页,所以使kern_pgdir指向当前第一个可用的虚拟地址,修改nextfree指向下一个(一页后)可用的虚拟地址,通过这种方式使页表目录在紧跟kernel之后拥有一页的可用内存。
然后,调用 memset(kern_pgdir, 0, PGSIZE); 将分配给页表目录的一页内存初始化为0;
boot_alloc()只是被暂时用作页分配器,之后使用的真正页分配器是page_alloc()函数
初始化页面数据结构
将物理内存以页为单位记录到一个数组中。
维护页面的数据结构为 struct PageInfo *pages,它将物理内存分为npages页,数组中每一项PageInfo代表内存中的一页。初始化代码如下:
pages = (pde_t *) boot_alloc(npages*sizeof(struct PageInfo));
memset(pages, 0, npages*sizeof(struct PageInfo));
首先为pages分配能够存放所有PageInfo项目的内存,然后将这段内存初始化为0
然后,调用 page_init() 函数对pages中的每一项和page_free_list链表进行初始化:
-
如果页已被占用,其
pp_ref(引用计数)被置1 -
若页空闲,则其
pp_ref置0,并送入page_free_list链表中 -
根据注解部分的提示,第0页、IO hole已被占用,内存extended部分被占用
其中,第0页为物理地址的前4k,存放real-mode IDT和BIOS structures;
IO hole为0x0A0000-0x100000的区域,被硬件保留用于特殊用途;
extended memory部分被占用的区域如kernel,以及我们刚刚分配的页表目录
物理内存的具体分配可以参考MIT-JOS系列2:bool loader过程的第一张图
在i386_detect_memory()函数中,我们已经得到前640K low memory(base)的页数npages_basemem;然后我们可以通过EXTPHYSMEM获得扩展内存的起始地址,从而算出IO hole的页数;最后可以通过boot_alloc(0)获得extended memory中当前可用的第一个虚拟地址,与起始地址KERNBASE作差得到extended memory处已使用的页数。由于IO hole与kernel无缝连接,所以可以直接将0x0A0000-kernel .bss的end部分的页都设置为已使用。
初始化页表的函数具体实现如下:
void
page_init(void)
{
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
//
// Change the code to reflect this.
// NB: DO NOT actually touch the physical memory corresponding to
// free pages!
size_t i;
// IO hole 区域 page 个数
int npages_io_hole = KERNBASE / PGSIZE - npages_basemem;
// extended memory处已使用的page个数
int npages_used_entmem = ((pde_t) boot_alloc(0) - KERNBASE) / PGSIZE;
pages[0].pp_ref = 1;
for (i = 1; i < npages; i++) {
// 页为 IO hole 区域或extended memory(两者是连续的, 占用0xA0000~kernel .bss段的end区域)
if (i >= npages_basemem && i < npages_basemem + npages_io_hole + npages_used_entmem) {
pages[i].pp_ref = 1;
} else {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
}
page_free_list结构如下图所示:
TODO
页面分配和释放
分配和释放页面的操作可以类比成进出栈。当需要alloc一个页面时,从page_free_list处取出一个空闲页面,page_free_list指向下一个空闲页面;当free一个页面时,将该页面的pp_link(下一个页表地址)指向当前page_free_list(头节点),page_free_list指向free的页面。alloc和free操作的过程中不修改任何页面的引用计数
分配和释放页面的具体实现如下:
// Allocates a physical page. If (alloc_flags & ALLOC_ZERO), fills the entire
// returned physical page with '\0' bytes. Does NOT increment the reference
// count of the page - the caller must do these if necessary (either explicitly
// or via page_insert).
//
// Be sure to set the pp_link field of the allocated page to NULL so
// page_free can check for double-free bugs.
//
// Returns NULL if out of free memory.
//
// Hint: use page2kva and memset
struct PageInfo *
page_alloc(int alloc_flags)
{
// Fill this function in
struct PageInfo *new_page;
if (page_free_list == NULL)
return NULL;
new_page = page_free_list;
page_free_list = new_page->pp_link;
new_page->pp_link = NULL;
if (alloc_flags & ALLOC_ZERO)
memset(page2kva(new_page), 0, PGSIZE);
return new_page;
}
//
// Return a page to the free list.
// (This function should only be called when pp->pp_ref reaches 0.)
//
void
page_free(struct PageInfo *pp)
{
// Fill this function in
// Hint: You may want to panic if pp->pp_ref is nonzero or
// pp->pp_link is not NULL.
assert(0 == pp->pp_ref);
assert(NULL == pp->pp_link);
pp->pp_link = page_free_list;
page_free_list = pp;
}
在初始化阶段,仅将内存规划为页面,做出各页面的数据结构,对虚拟内存到物理内存的映射、虚拟内存到页面的关联,由接下来的虚拟内存管理来做
虚拟内存管理
虚拟内存管理主要是对页表进行管理,包括插入和删除线性地址到物理地址的映射关系,以及创建页表等操作(之前只是创建了页表相关的数据结构,整理出可用的空闲页表,但并未填写页表目录和创建出真正的二级页表)
在进行虚拟地址映射之前,首先回顾MIT-JOS系列1:实模式和保护模式下的段寻址方式中的保护模式,理解以下内容:
- 何为逻辑地址、线性地址和物理地址
- 页表的数据结构(线性地址格式,页表项格式,页表目录、二级页表项存储方式等)
- 如何从线性地址利用二级页表转化为物理地址
对以上问题,也许博客中的例1和例2能帮助快速理解
在此基础上,增加以下概念:
页框地址Page Frame Address
页框地址是一个指定页面的物理地址的起始地址。由于页大小为4K,并对其到内存的4K边界,因此页框地址必定是4K的倍数,页框地址的低12位必然为0。
- 对于页表目录,页框地址是页表目录的地址(页表目录是一整个页)
- 对于二级页表,页框地址是目的地址条目的页表项所在的页的起始地址
访问位和脏位Accessed and Dirty Bits
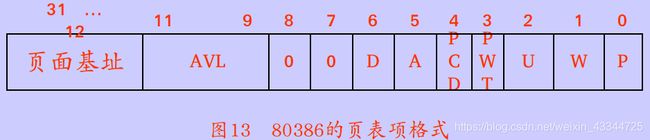
页表项中第5和第6位分别是访问位(accessed bit)和脏位(dirty bit)
- 访问位指示自从最近一次清空该位以来,是否访问过相应页面
- 脏标志位指示该页面自从最近一次换入之后是否曾被修改过
当读写一个页面(包括页表目录和二级页表)时,处理器置其相应访问位accessed为1
当写一个二级页表的页面时,处理器置其脏位dirty为1,处理器不修改页表目录的脏位
处理器不自动清除任何位,由操作系统负责测试和清除这些位
页面保护
页面保护分为两种类型:
- 可寻址域检查
- 类型检查
可寻址域检查:通过设置每个页面的权限级别(图中第2位U)实现两种页面权限:
- 特权级别:U=0,用于操作系统和其他系统软件的相关数据
- 用户级别:U=1,用于用户应用产生的数据
当前进程的级别与CPL有关。选择子(如DS)存放描述符索引TI、描述符指示器和当前特权级RPL,如图:
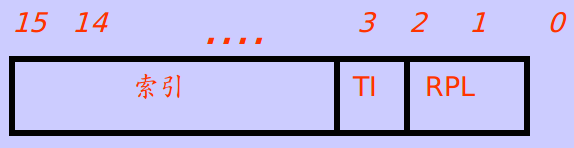
当选择子被放入代码段选择子(CS)后,0和1位的RPL就是当前进程的CPL
CPU的当前特权级(CPL)反映了进程是在用户态还是内核态,CPL的值为0,1,2时当前进程处于内核态(特权级别),为3时当前进程处于用户态(用户级别)
类型检查:页面寻址类型由图中第一位W定义:
- 只读模式:W=0
- 读写模式:W=1
若当前进程运行在特权模式,则任何页面都是可读写的;若当前进程运行在用户模式,仅对于用户级别且标记为可读写的页面可写,对于特权级别的页面不可读也不可写
在lab1中,我们载入GDT表并将代码段和数据段的基地址设置为0,因此在之前我们使用的段选择子都没有发挥实际效果,代码中的线性地址等于逻辑地址的偏移部分(此时相当于链接地址)。与此同时,在lab1中我们建立简易页表,利用entry_pgdir建立起4MB的映射使内核能够使用高于0xf0000000的部分地址。接下来我们要从0xf0000000扩展虚拟内存映射,使之能映射到物理内存前256M的地址
物理地址和虚拟地址的数据类型
在JOS内核中使用的物理地址和虚拟地址都使用整数类型表示,但以类型名加以区分:
- 物理地址:
physaddr_t - 虚拟地址:
uintptr_t
它们实际上都是uint32_t类型(32位无符号整数),因此直接解引用(dereferencing)取值会报错,例如uintptr_t addr=0xf0100000;,虽然里面存放的是地址,但直接使用*addr获取该地址的值是编译器不允许的
一旦进入保护模式,我们无法再使用物理地址,在代码中使用的地址都应该是虚拟地址,它们会被MMU自动转换成物理地址。因此对于虚拟地址,我们可以强制转换它为uintptr_t*类型后取出它的值;但对于物理地址,这么做虽然编译不报错,但经过MMU转换后的地址取出的值可能不会是我们想要的值
在需要读写内存时,JOS内核有时候可能只知道内存的物理地址,例如新加入一个页表项时需要为他分配一块物理内存来存放它并初始化这块内存。此时可以使用KADDR(pa)将物理地址转化为虚拟地址,然后对虚拟地址进行操作。例如之前在初始化页表为0时,使用过的page2kva(pp),其实现如下:
#define KADDR(pa) _kaddr(__FILE__, __LINE__, pa)
static inline void*
_kaddr(const char *file, int line, physaddr_t pa)
{
if (PGNUM(pa) >= npages)
_panic(file, line, "KADDR called with invalid pa %08lx", pa);
return (void *)(pa + KERNBASE);
}
static inline physaddr_t
page2pa(struct PageInfo *pp)
{
return (pp - pages) << PGSHIFT;
}
static inline void*
page2kva(struct PageInfo *pp)
{
return KADDR(page2pa(pp));
}
初始化页表需要知道该页表的首地址,且这个地址应该是虚拟地址。
首先根据该页表项的地址&page[i]和页表信息的首地址page得出是第几个页表,然后左移12位(乘页面大小4K),此时得到的地址是当前页表相当于地址0的偏移。由于分页是从物理内存0开始,因此此时得到的应该是物理地址。然后,通过调用KADDR(pa)将得到的物理地址转化为我们需需要的虚拟地址,然后使用这个虚拟地址对指定长度的页面初始化
引用计数
在实际应用中经常会有多个不同的虚拟地址页被同时映射到同一物理页的情况。struct PageInfo结构中使用pp_ref字段保存物理页的引用计数。当引用计数为0,代表页面没有被使用,这个物理页才能被释放
在之前的实现中可以发现alloc和free操作的过程中不修改任何页表的引用计数,因此当调用page_alloc()得到页面后,总会得到一个引用计数为0的页面,需要将它的引用计数+1
虚拟内存管理
虚拟内存管理根据lab2 Exercise4给出的实验步骤进行讲解
pgdir_walk()
函数功能:给定一个指向页表目录的指针pgdir,pgdir_walk返回指向线性地址va对应的页表项的指针
相关的页表项对应的页表可能是不存在的:
- 若
create == false则返回NULL - 否则调用
page_alloc()分配一个页表,增加其引用计数或返回NULL(分配失败) - 返回页表项
函数的操作步骤如下:
- 根据线性地址
va,计算出页表项所在的页表的基地址:线性地址va的高10位是该基址在页表目录中的索引,可以通过宏PDX(va)得到(这个宏将参数右移22位)如果对应位置的页表不存在,则新分配一个页表 - 计算页表项的地址:线性地址
va的12-21位为页表项在页表中的索引,可以通过宏PTX(va)得到
代码实现如下:
pte_t *
pgdir_walk(pde_t *pgdir, const void *va, int create)
{
// Fill this function in
// 得到线性地址对应的页表项所在的页表的基地址在页表目录中的索引
// 线性地址va的高10位是该基址在页表目录中的索引
struct PageInfo *new_page = NULL;
pde_t *dir_page_entry = pgdir + PDX(va);
// 从页表目录中查询该页表(得到的是该页表的页表项)
// 若其P位为0,则该页表不在内存中,通过page_alloc分配一个
// 分配成功后,对page的引用计数+1,更新页表目录中的地址信息、权限
if (!(*dir_page_entry & PTE_P)) {
if (!create)
return NULL;
new_page = page_alloc(1);
if (!new_page)
return NULL;
new_page->pp_ref++;
// 此处page2pa(new_page)得到的是页表new_page的物理地址(由于4k对齐,低12位为0)
*dir_page_entry = page2pa(new_page) | PTE_P | PTE_W | PTE_U;
}
// 页表存在,获取页表的首地址
// 页表目录的页表项高20位是页面的基地址(实页号),高20位的值左移12位(乘4k)为页面的首地址
// ↑ 上述操作等同于直接取出页表项的高20位(取到的是物理地址)
physaddr_t page_base = PTE_ADDR(*dir_page_entry);
// 线性地址va的12-21位为页表项在页表中的索引
physaddr_t page_entry = page_base + PTX(va);
// 得到的是物理地址,转化为虚拟地址
return KADDR(page_entry);
}
boot_map_region()
函数功能:向页表目录pgdir加入映射关系,将虚拟地址[va, va+size)映射到物理地址[pa, pa+size)。size是PGSIZE的整数倍,且va,pa是页对齐的
这个函数利用之前编写的pgdir_walk(),对指定的虚拟地址,完成了其页表目录和二级页表的建立,从而完成映射
pgdir_walk()的返回值是页表项的地址(虚拟地址),对于得到的页表项,填写其高20位为物理页面地址(页面基址),设置其权限为perm,存在位为1
代码实现如下:
static void
boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm)
{
// Fill this function in
int n = size / PGSIZE;
int i;
uintptr_t *page_enrty = NULL;
for (i=0; i<size; i+=PGSIZE) {
page_enrty = pgdir_walk(pgdir, (void*)va, 1);
if (!page_enrty)
panic("Out of memory!\n");
*page_enrty = pa | perm | PTE_P;
pa += PGSIZE;
va += PGSIZE;
}
}
page_lookup()
函数功能:返回虚拟地址va对应的页表。如果pte_store非空,则将页表项的地址存放在pte_store中
代码实现如下:
struct PageInfo *
page_lookup(pde_t *pgdir, void *va, pte_t **pte_store)
{
// Fill this function in
// 得到va对应的页表项
uintptr_t *page_entry = pgdir_walk(pgdir, va, 0);
if (!pgdir)
return NULL;
// 得到va对应的页表首地址(物理地址)
physaddr_t page_addr = PTE_ADDR(*page_entry);
if (pte_store)
*pte_store = page_entry;
return pa2page(page_addr);
}
page_remove()
函数功能:删除虚拟地址va到物理地址pa的映射,如果该虚拟地址没有对应的物理地址,直接返回
- 将页面的引用计数减1
- 若引用计数为0,则回收(page_free)页面
- 相关联的页表项应当被设置为0
- 使TLB缓存无效
代码实现如下:
void
page_remove(pde_t *pgdir, void *va)
{
// Fill this function in
uintptr_t *page_entry = NULL;
struct PageInfo *page = page_lookup(pgdir, va, &page_entry);
if (!page) return;
page_decref(page);
tlb_invalidate(pgdir, va);
*page_entry = 0;
}
page_insert()
函数功能:建立虚拟地址va到物理页面pp的映射
- 如果已有物理地址被映射到
va,调用page_remove()将其删除 - 物理页面pp的引用计数+1
代码实现如下:
int
page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm)
{
// Fill this function in
uintptr_t *page_entry = pgdir_walk(pgdir, va, 1);
if (!page_entry)
return -E_NO_MEM;
pp->pp_ref++;
// 若该虚拟地址有映射的物理页,先删除映射
if (*page_entry & PTE_P)
page_remove(pgdir, va);
*page_entry = page2pa(pp) | perm | PTE_P;
return 0;
}
注意:这里pp->pp_ref++一定要放在page_remove之前,否则若原来va已经映射到pp且只有va映射到pp,先调用page_remove将会free掉pp,造成空闲页表链表管理出错
虚拟内存管理在物理页面管理的基础上实现虚拟地址到物理地址的映射管理操作和二级页表管理操作。
- 在物理页面管理中,只创建了一个空的页表目录,并没有建立页表目录与二级页表的对应关系,也没有为二级页表分配内存空间
- 对于一个特定的虚拟地址(线性地址),其映射到哪个物理页面是需要人为指定的,它对应与页表目录的哪个项是确定的(都是根据虚拟地址本身计算得出),该项指向哪个二级页表是不确定的(初始通过page_alloc分配一个可用的页面,将页面基地址填入页表目录)。因此只有在有映射关系建立时,即有二级页表的页表项需要被写入时,该页表项对应的二级页表才会被分配页面
- 除了建立页表目录,往后都不需要boot_alloc手动分配内存,只以页为单位分配(或释放)内存,修改该页面的引用计数示意这段内存是否被使用,并维护空闲页面链表
至此为止,我们建立了内存映射的数据结构和相关方法,但还没有实际映射它们
内核地址空间
JOS将32位虚拟地址空间分为内核地址空间和用户地址空间。为了给用户地址空间留下足够多的空间,操作系统内核一般占据在高地址的部分。这两个部分的分界线由inc/memlayout.h中的符号ULIM定义,其上为约256MB的内核地址空间。JOS的虚拟内存布局如下:
/*
* Virtual memory map: Permissions
* kernel/user
*
* 4 Gig --------> +------------------------------+
* | | RW/--
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* : . :
* : . :
* : . :
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
* | | RW/--
* | Remapped Physical Memory | RW/--
* | | RW/--
* KERNBASE, ----> +------------------------------+ 0xf0000000 --+
* KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| |
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* | CPU1's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| PTSIZE
* | Invalid Memory (*) | --/-- KSTKGAP |
* +------------------------------+ |
* : . : |
* : . : |
* MMIOLIM ------> +------------------------------+ 0xefc00000 --+
* | Memory-mapped I/O | RW/-- PTSIZE
* ULIM, MMIOBASE --> +------------------------------+ 0xef800000
* | Cur. Page Table (User R-) | R-/R- PTSIZE
* UVPT ----> +------------------------------+ 0xef400000
* | RO PAGES | R-/R- PTSIZE
* UPAGES ----> +------------------------------+ 0xef000000
* | RO ENVS | R-/R- PTSIZE
* UTOP,UENVS ------> +------------------------------+ 0xeec00000
* UXSTACKTOP -/ | User Exception Stack | RW/RW PGSIZE
* +------------------------------+ 0xeebff000
* | Empty Memory (*) | --/-- PGSIZE
* USTACKTOP ---> +------------------------------+ 0xeebfe000
* | Normal User Stack | RW/RW PGSIZE
* +------------------------------+ 0xeebfd000
* | |
* | |
* ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
* . .
* . .
* . .
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~|
* | Program Data & Heap |
* UTEXT --------> +------------------------------+ 0x00800000
* PFTEMP -------> | Empty Memory (*) | PTSIZE
* | |
* UTEMP --------> +------------------------------+ 0x00400000 --+
* | Empty Memory (*) | |
* | - - - - - - - - - - - - - - -| |
* | User STAB Data (optional) | PTSIZE
* USTABDATA ----> +------------------------------+ 0x00200000 |
* | Empty Memory (*) | |
* 0 ------------> +------------------------------+ --+
*
* (*) Note: The kernel ensures that "Invalid Memory" is *never* mapped.
* "Empty Memory" is normally unmapped, but user programs may map pages
* there if desired. JOS user programs map pages temporarily at UTEMP.
*/
由于内核和用户进程都各自运行在自己的地址空间,因此我们使用**页表权限位(permission bits)**阻止用户进程访问用户地址空间以外的空间,避免其读取或改写内核数据
- 对于
ULIM以上的地址空间,用户态无权访问,只有内核可以读写它们 - 对于
[UTOP,ULIM)部分的地址空间,用户和内核都只能读取,不能写入。这个地址范围通常用于将某些内核数据结构以只读方式暴露给用户 - 对于
UTOP以下的地址空间留给用户使用,用户可以读写它们
初始化内核地址空间
映射建立的代码都在mem_init()内补充,紧跟在物理页初始化page_init()之后。首先将虚拟地址UPAGES以用户、内核只读的方式映射到存放page数组的物理内存处,此处调用boot_map_region()方法:
// 计算出pages数组的大小,并映射到UPAGES
int size = ROUNDUP(npages*sizeof(struct PageInfo), PGSIZE);
boot_map_region(kern_pgdir, UPAGES, size, PADDR(pages), PTE_U);
然后将bootstack(在kernel的entry.S中创建的大小为KSTKSIZE(32K)的栈)映射到虚拟地址[KSTACKTOP-KSTKSIZE, KSTACKTOP)处,权限为Kernel可读写,用户不可读写
boot_map_region(kern_pgdir, KSTACKTOP-KSTKSIZE, ROUNDUP(KSTKSIZE, PGSIZE),
PADDR(bootstack), PTE_W);
最后将整个物理地址空间映射到KERNBASE
- 虚拟地址范围:
[KERNBASE, 2^32) - 物理地址范围:
[0, 2^32 - KERNBASE) - 事实上物理内存不一定有2^32 - KERNBASE bytes那么大,但映射的时候没关系,映射就完事儿了
- 权限:Kernel可读写,用户不可读写
size = 0xffffffff - KERNBASE + 1;
boot_map_region(kern_pgdir, KERNBASE, ROUNDUP(size, PGSIZE), 0, PTE_W);
在所有的映射完成后,页表目录kern_pgdir和二级页表根据当前使用的内存进行了适当的填写,此时修改寄存器cr3的值为当前的页表目录的物理地址:
lcr3(PADDR(kern_pgdir));
映射后,虚拟地址空间与物理地址空间的对应关系如下:
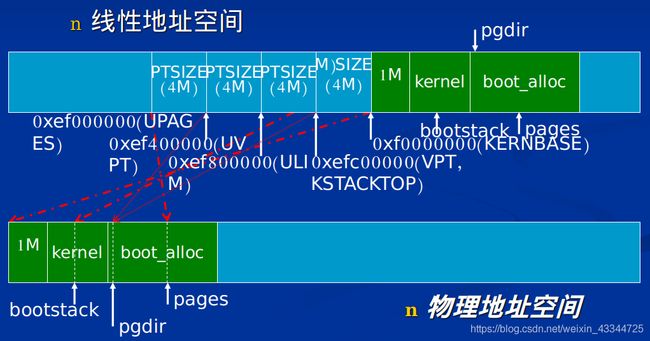
到这里我们建立的256M内存的映射关系被真正启用了
Q:mem_init()中通过lcr3(PADDR(kern_pgdir));更改了页表目录,但此时GDTR放的gdt表地址还是旧的物理地址(比如我打印得到的0x7c4c),新的页表目录没有映射这段低虚拟地址空间。在lcr3前可以通过x/10x *0x7c4c访问到这段内存,但在lcr3操作后之后就访问不了了,这时候又还没载入新的gdt地址(直到env_init()的env_init_percpu才载入,这个操作以后会提到),那么这期间内是怎么通过gdt进行逻辑地址到线性地址的转换,为什么程序还能正常运行?
A:问了老师,确实存在如上的问题。在2007版的JOS操作系统实验中,kernel的entry.S中重新载入过GDT表基地址到GDTR保证寻址的正确,但2016版更新GDTR确实晚了,可能是考虑不严谨。至于为什么还能正常寻到址,推测可能是CPU做了缓存,暂时免去了这部分的地址转换和页面查找
Question
-
We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
页表项的Supervisor/User位(
PTE_U)设置为0,使用户无法访问此页 -
What is the maximum amount of physical memory that this operating system can support? Why?
UPAGES的大小为PTSIZE(4MB),UPAGES中存放pages数组,数组每个项struct PageInfo为8字节,因此最多存放524288个PageInfo。一个PageInfo对应一个4K大小的页面,因此最多管理524288×4K=2G大小的物理内存 -
How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
若实际拥有2G物理内存,将需要4MB的pages数组管理物理页面;初次之外需要一个页面(4K)存放页表目录,需空间存放二级页表(一个页表项四个字节,一个二级页面4K可存放1024个页表项,管理2G空间需要存储524288个页表项,总共需要512个页面,总计2M),因此空间总开销为4M+4K+2M=6M+4K
-
Revisit the page table setup in
kern/entry.Sandkern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?在指令
jmp *%eax后重新设置了EIP的值,完成EIP从小地址到大地址的转换。因为利用
entry_pgdir建立4MB地址空间的映射时,同时映射了虚拟地址[0, 4M)到物理地址[0, 4M),因此可以保证跳转之前对地址的转换正确
内存管理小结
本次实验主要建立了虚拟内存到物理内存的映射,首先编写映射所需要的基本函数,然后调用这些函数进行内存映射:
- 用CMOS检测可用的物理内存
- 为kernel的页表目录分配内存,将页表目录
kern_pgdir作为页表插入到页表项UVPT处(以便内核以外的环境在UVPT处能够查找到自己的页表目录,在lab4中会讲到,原理也可以直接参考MIT-JOS系列:用户态访问页表项详解) - 初始化
pages数组,将物理内存以页为单位记录到pages数组中并利用page_free_list管理空闲页面,编写页表分配、释放、映射的相关函数 - 完成物理内存前256M的映射,与此同时填写了页表目录和二级页表,并赋予页面相应权限
- 设置
cr3为kern_pgdir的物理地址,并设置cr0的标志