Map:探寻HashMap及其实现原理
今天看下util包下的HashMap类,看看我们常用的数据结构有哪些好用方法没被get到!

类实现了一个抽象类和一堆接口,先从接口看起
这个接口没有定义要实现的方法,设计思路应该是遵循 "接口隔离原则" 实现最小范围调用
接下来看看Map接口,所有的内容如下
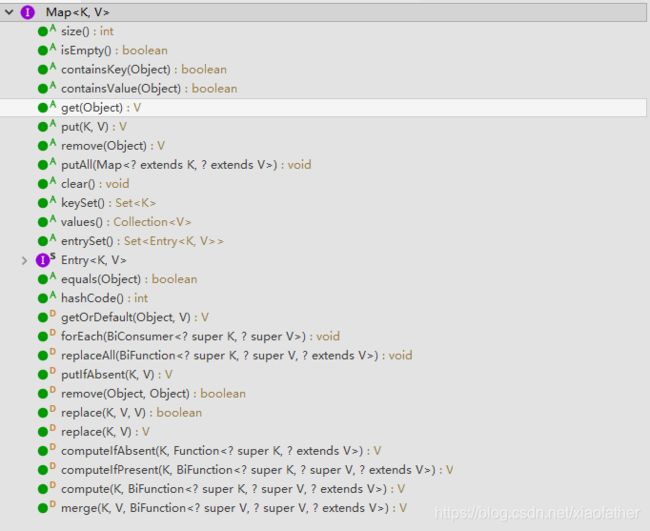
方法总结如下方表格中汇总所述:
| method | parameterType | resultType | remark |
|---|---|---|---|
| size() | int | 获取Map大小 | |
| isEmpty() | boolean | 是否为空,为空返回true | |
| containsKey() |
Object | boolean | Map是否包含某个key |
| containsValue() | Object | boolean | Map是否包含某个Value |
| get() | Object | V | 获取指定Key对应的Value,没有返回null |
| put() | K,V | V | 添加键值对 |
| remove() | Object | V | 删除指定key对应的键值对 |
| putAll() | Map | 将另一个Map对象添加到当前Map | |
| clear() | 清空Map | ||
| KeySet() | Set |
获取Map的所有Key并存在Set中 | |
| Values() | Collection |
获取所有的value | |
| entrySet() | Set |
获取Map下所有的Entry | |
| Entry |
结构,抽象类 | ||
| equals() | Object | boolean | |
| hashCode() | int | ||
| getOrDefault() | Object,V | V | |
| forEach() | BiConsume | ||
| replaceAll() | BiConsume, ? extends V | ||
| putIfAbsent() | K,V | V | |
| remove() | Object,Object | boolean | |
| replace() | K,V,V | boolean | |
| replace() | K,V | V | |
| computeIfAbsent() | K,Function | V | |
| computeIfPresent() | K key,BiFunction remappingFunction | V | |
| compute() | K key, BiFunction remappingFunction | V | |
| merge() | K key, V value,BiFunction remappingFunction | V |
对K,V类型不太了解的话可以看下这篇博客《Java泛型中E、T、K、V等的含义》
遵守如上规则既是一个合格的Map,但今天是解析HashMap类的,so接着 看看HashMap类唯一继承AbstractMap
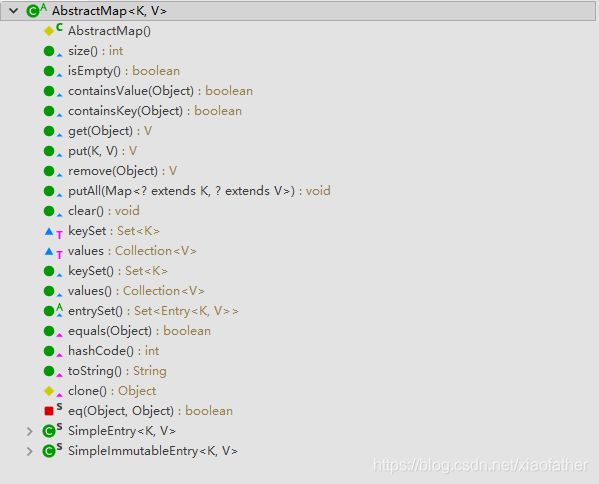
这个类是Map接口的实现类,主要作用是将Map接口下 相同的 具体实现方法实现汇总共享,起到承上启下的作用。
其中核心方法 entrySet() 需要注意, 这个抽象方法需要子类实现 并 返回子类所有Entry实例,提供抽象类其他方法使用
背景介绍完了,现在看看HashMap类
HashMap继承AbstractMap抽象类,隐式的引入了Map接口,故在AbstractMap中未实例化的方法将会在HashMap中实现,在AbstractMap定义的抽象方法也会在这里得以实现,另包含了一些HashMap的功能处理方法,所以看起来有点多
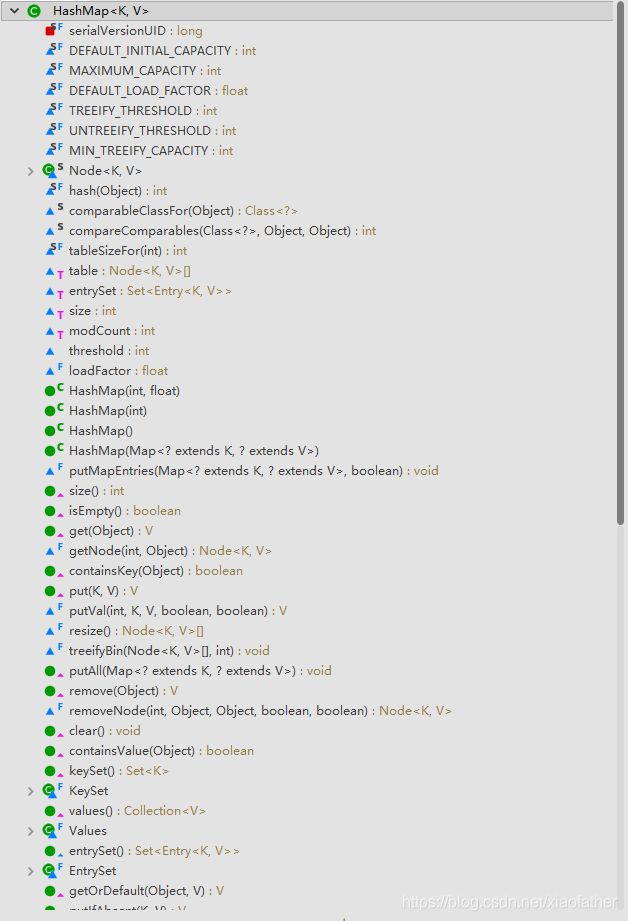
方法和成员变量太多博主也不想一个一个看了,结合实际内容 和 本文命题 探寻一下重要部分 并 扫扫盲
在博主的理解中HashMap的组成分为如下部分:
1>核心结构
2>初始化构造器
3>针对核心结构进行业务运用
1 先来认识HashMap的核心结构
Map.Entry -> AbstractMap中Map.Entry实现 -> HashMap中Map.Entry实现
1>Node.class [implements Map.Entry

这个Node对象类似于Integer对象中封装的int一样,在Integer中都是围绕int做处理,在HashMap中也是相同的原理
Node对象结构和提供的能力如上,比较简洁,其中Node
2>TreeNode.class [extends LinkedHashMap.Entry

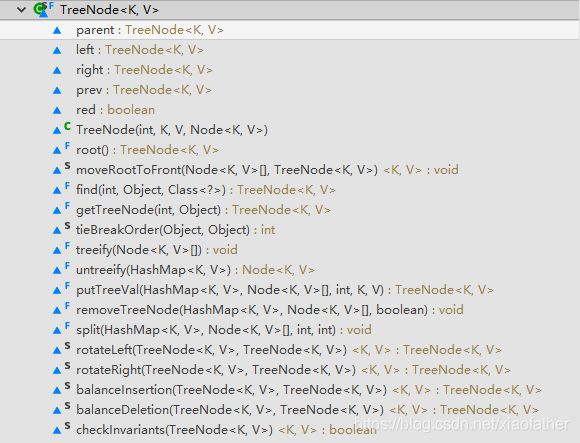
详解请看这篇博文【博文在讲解执行过程中有点难理解的地方可以画图描述步骤方便理解】
2.看看在初始化HashMap时候进行了那些默认配置处理

构造器中初始化了一些配置,可以看下《HashMap中capacity、loadFactor、threshold、size等概念的解释》这篇文章
默认构造器
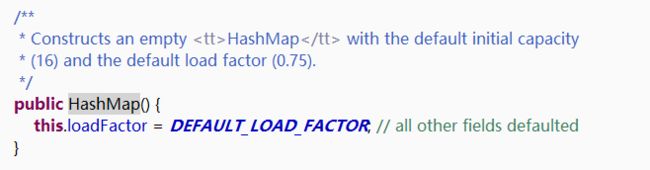
带参构造器(int)

带参构造器(int,float)

按照文章中所描述的内容我们知道这些参数是为HashMap自动扩容做准备
带参构造器(Map)

3.运用部分
因为根据HashMap进行业务运用的方法太多,现在依据比较热点的问题对运用这块进行剖析
1:HashMap的存储(put的工作)原理是?

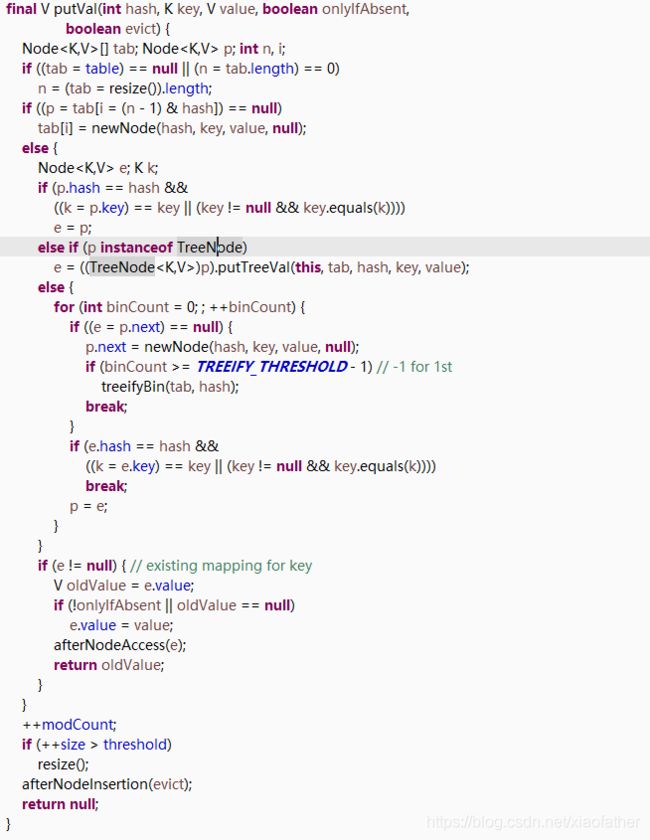
其中用到位运算符,不熟的同学请先了解
根据代码一步一步解析:
1> 如果为空,通过resize方法初始化HashMap的成员变量node数组容量
final Node[] resize() {
// 获取当前HashMap中保存的node数组
Node[] oldTab = table;
// 判断数组是否为null,如果为空,旧桶的数量为0,否则得到桶的数量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 获取旧的(reside方法判断执行依据数据)
int oldThr = threshold;
// 创建新的桶和新的(reside方法判断执行依据数据)
int newCap, newThr = 0;
// 如果旧桶的数量大于0
if (oldCap > 0) {
// 如果旧桶的数量大于等于最大的桶数
if (oldCap >= MAXIMUM_CAPACITY) {
// 当前HashMap触发(reside方法判断执行依据数据)等于Integer的最大值
threshold = Integer.MAX_VALUE;
// 返回当前node数组给调用方法
return oldTab;
}
// 否则新的桶数量赋值为旧的桶数量的一倍,如果新的桶小于桶的最大数 并且 旧桶大于默认桶的个数(16)
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 新桶的个数是旧桶的一倍
newThr = oldThr << 1; // double threshold
}
// 在旧桶的数量不大于0情况,判断HashMap的(reside方法判断执行依据数据)是否大于0
else if (oldThr > 0) // initial capacity was placed in threshold
// 条件成立 旧桶的数量等同于(reside方法判断执行依据数据)
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 否则新桶的数量为默认桶的数量(16)
newCap = DEFAULT_INITIAL_CAPACITY;
// 新HashMap的扩容判断数据为 装载因子* 默认桶数 0.75 * 16 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果新桶的(reside方法判断执行依据数据) == 0
if (newThr == 0) {
// 重新获取一遍当前(reside方法判断执行依据数据)
float ft = (float)newCap * loadFactor;
// 如果新桶小于最大桶数并且 (reside方法判断执行依据数据) 小于最大桶数,就用新的(reside方法判断执行依据数据),否则(reside方法判断执行依据数据)为Integer的最大值
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 当前HashMap的(reside方法判断执行依据数据)为新的 (reside方法判断执行依据数据)
threshold = newThr;
// 创建新的node数组,大小为新的桶数
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
// 当前HashMap的node数组等于新的node数组
table = newTab;
// 如果旧的node数组不为空的话
if (oldTab != null) {
// 循环拿到旧的node数组中node实例
for (int j = 0; j < oldCap; ++j) {
// 创建一个node对象
Node e;
// 将从node数组中拿到的node实例赋值给新建的node对象,并判断是否为null
if ((e = oldTab[j]) != null) {
// 如果不为null,将node数组中的对应下标node赋值为null
oldTab[j] = null;
// 如果node没有链表的下一个节点
if (e.next == null)
// 将得到的node存入node数组 (与计算)位置
newTab[e.hash & (newCap - 1)] = e;
// 如果node实现了treeNode,既是树存储结构
else if (e instanceof TreeNode)
// 则调用treeNode中的split方法实现存储
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
// 当node不为null的时候,又不是树存储结构,此时的node是一个链表结构
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
// 赋值next为node对象的下一个node对象
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
} 2> 当下标没中没有node对象时候直接创建一个node对象进去,否则进入else分支,其中难点解释一下
if ((p = tab[i = (n - 1) & hash]) == null)
// 其中hash是根据Key从静态方法hash()中获取
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//获得的hashcode是一个32位的int型数据,很明显从2的-31次幂到2的32次幂长度的数据远超过hashmap的
//最大容量,所以这里通过key的hashcode右移16位与原hashcode进行或非运算,实际上就是hashcode与
//前16位换成0的hashcode进行或非运算,如果高位不参与运算,发生hash冲撞的几率就会增大,从而影响性能
// 至于为什么用n-1,举个例子,假设n为16,n-1为15,
// 也就是0000 0000 0000 0000 0000 0000 0000 1111,和hash值进行与运算,
// 也就是这后四位进行运算,
// 结果就被限制在0000~1111之间,正好是数组的长度,游标从0到15
以上内容来自
---------------------
作者:li_cangqiong
来源:CSDN
原文:https://blog.csdn.net/li_cangqiong/article/details/81871332
3> 如果(数组下标的node元素)hash等于新存入的Hash,并且key相同,则进行替换
4> (数组下标的node元素)是 红黑树 结构,则通过putTreeVal()方法执行添加操作【TreeNode中引入的文章中有具体解释】
5> 否则(数组下标的node元素)是链表结构,因为拿到的是一个链表,所以这里有个 if( (e=p.next) == null ) 判断,为的就是得到 bin 的个数,如果大于8【TREEIFY_THRESHOLD】个则将 bin组 转换成 红黑树
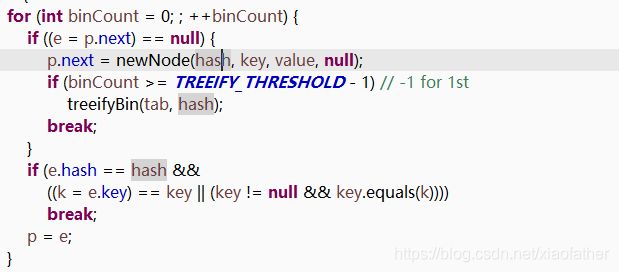
此时遗留一个问题 : 如果 bin组 中也有相同的key,该怎么处理?下面的判断则是将这个问题继续往后抛,接着往下看!
6> 此时我们可以看到,上述遗留问题也迎刃而解,并且得到旧的value值,用来返回给调用者

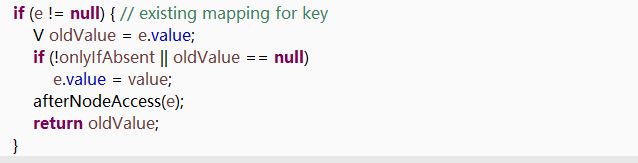

7> 对一些内容进行修改,其中包括扩容

2:HashMap的获取(get的工作)原理是?


似乎没什么好讲解的....
最难的部分应该已经讲解了,剩下的其他方法只是对这块的运用,自己看看源码即可。
那么第一阶段HashMap的探索就到此结束,后续会补充一些HashMap相关的内容:可能是在下次复习HashMap的时候
那么,就这样吧