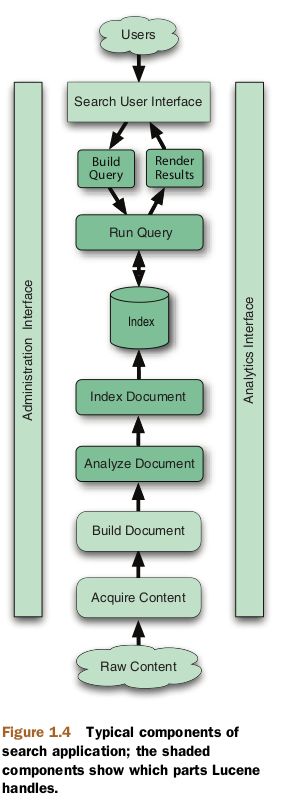
 Components for indexing
Components for indexing
ACQUIRE CONTENT
The first step, at the bottom of figure 1.4, is to acquire content. This process, which involves using a crawler or spider, gathers and scopes the content that needs to be indexed. That may be trivial, for example, if you’re indexing a set of XML files that resides in a specific directory in the file system or if all your content resides in a wellorganized database. Alternatively, it may be horribly complex and messy if the content is scattered in all sorts of places (file systems, content management systems, Microsoft
Exchange, Lotus Domino, various websites, databases, local XML files, CGI scripts running on intranet servers, and so forth).
BUILD DOCUMENT
Once you have the raw content that needs to be indexed, you must translate the content into the units (usually called documents) used by the search engine. The document typically consists of several separately named fields with values, such as title, body, abstract, author, and url. You’ll have to carefully design how to divide the raw content into documents and fields as well as how to compute the value for each of those fields. Often the approach is obvious: one email message becomes one document, or one
PDF file or web page is one document.
Once you’ve worked out this design, you’ll need to extract text from the original raw content for each document. If your content is already textual in nature, with a known standard encoding, your job is simple. But more often these days documents are binary in nature (PDF, Microsoft Office, Open Office, Adobe Flash, streaming video and audio multimedia files) or contain substantial markups that you must remove before indexing (RDF, XML, HTML). You’ll need to run document filters to extract text from such content before creating the search engine document.
Interesting business logic may also apply during this step to create additional fields. For example, if you have a large “body text” field, you might run semantic analyzers to pull out proper names, places, dates, times, locations, and so forth into separate fields in the document. Or perhaps you tie in content available in a separate store(such as a database) and merge this for a single document to the search engine.
Another common part of building the document is to inject boosts to individual documents and fields that are deemed more or less important.
Lucene provides an API for building fields and documents, but it doesn’t provide any logic to build a document because that’s entirely application specific. It also doesn’t provide any document filters, although Lucene has a sister project at Apache,Tika, which handles document filtering very well (see chapter 7). If your content resides in a database, projects like DBSight, Hibernate Search, LuSQL, Compass, and Oracle/Lucene integration make indexing and searching your tables simple by handling the Acquire Content and Build Document steps seamlessly.
ANALYZE DOCUMENT
No search engine indexes text directly: rather, the text must be broken into a series of individual atomic elements called tokens. This is what happens during the Analyze Document step. Each token corresponds roughly to a “word” in the language, and this step determines how the textual fields in the document are divided into a series of tokens.
INDEX DOCUMENT
During the indexing step, the document is added to the index.
---------------------------------------------------
Components for searching
SEARCH USER INTERFACE
The user interface is what users actually see, in the web browser, desktop application,or mobile device, when they interact with your search application. The UI is the most important part of your search application!
Keep the interface simple: don’t present a lot of advanced options on the first page. Provide a ubiquitous, prominent search box, visible everywhere, rather than requiring a two-step process of first clicking a search link and then entering the search text (this is a common mistake).
Once a user interacts with your search interface, she or he submits a search request, which first must be translated into an appropriate Query object for the search engine.
BUILD QUERY
When you manage to entice a user to use your search application, she or he issues a search request, often as the result of an HTML form or Ajax request submitted by a browser to your server. You must then translate the request into the search engine’s Query object.
The query may contain Boolean operations, phrase queries (in double quotes), or wildcard terms. If your application has further controls on the search UI, or further interesting constraints, you must implement logic to translate this into the equivalent query.
SEARCH QUERY
Search Query is the process of consulting the search index and retrieving the documents matching the Query, sorted in the requested sort order. Lucene is also wonderfully extensible at this point, so if you’d like to customize how results are gathered, filtered, sorted, and so forth, it’s straightforward.
There are three common theoretical models of search:
- Pure Boolean model—Documents either match or don’t match the providedquery, and no scoring is done. In this model there are no relevance scores associated with matching documents, and the matching documents are unordered;a query simply identifies a subset of the overall corpus as matching the query.
- Vector space model—Both queries and documents are modeled as vectors in ahigh dimensional space, where each unique term is a dimension. Relevance, or similarity, between a query and a document is computed by a vector distancemeasure between these vectors.
- Probabilistic model—In this model, you compute the probability that a document is a good match to a query using a full probabilistic approach.
RENDER RESULTS
Once you have the raw set of documents that match the query, sorted in the right order, you then render them to the user in an intuitive, consumable manner. The UI should also offer a clear path for follow-on searches or actions, such as clicking to the next page, refining the search, or finding documents similar to one of the matches, so that the user never hits a dead end。